Downloaded 789 times









![The overheads of Java objects
“abcd”
9
• Native: 4 bytes with UTF-8 encoding
• Java: 48 bytes
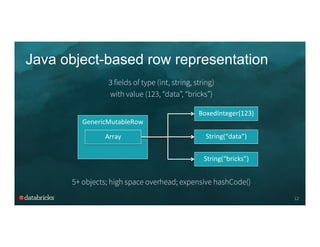
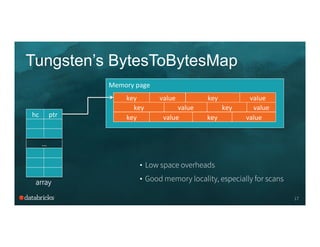
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) ...
4 4 (object header) ...
8 4 (object header) ...
12 4 char[] String.value []
16 4 int String.hash 0
20 4 int String.hash32 0
Instance size: 24 bytes (reported by Instrumentation API)
12 byte object header
8 byte hashcode
20 bytes of overhead + 8 bytes for chars](https://image.slidesharecdn.com/08joshrosen-150624014400-lva1-app6891/85/Deep-Dive-into-Project-Tungsten-Bringing-Spark-Closer-to-Bare-Metal-Josh-Rosen-Databricks-9-320.jpg)






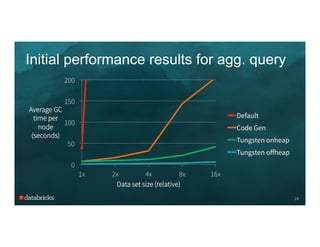





This document summarizes Project Tungsten, an effort by Databricks to substantially improve the memory and CPU efficiency of Spark applications. It discusses how Tungsten optimizes memory and CPU usage through techniques like explicit memory management, cache-aware algorithms, and code generation. It provides examples of how these optimizations improve performance for aggregation queries and record sorting. The roadmap outlines expanding Tungsten's optimizations in Spark 1.4 through 1.6 to support more workloads and achieve end-to-end processing using binary data representations.






























![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































