

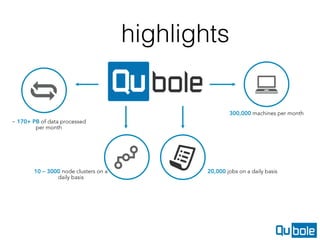



















This document discusses running Spark on the cloud, including the advantages, challenges, and how Qubole addresses them. Some key advantages include using S3 for storage which allows independent scaling of storage and compute, ability to create ephemeral clusters on demand, and autoscaling capabilities. Challenges involve cluster lifecycle management, different interfaces needed, Spark autoscaling, debuggability across clusters, and handling spot instances. Qubole provides tools that automate cluster management, enable autoscaling of Spark, and make experiences seamless across clusters and interfaces.

















































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)


