Download as PDF, PPTX







![SparkContext: entry to the world
● Can be used to create distributed data from many input
sources
○ Native collections, local & remote FS
○ Any Hadoop Data Source
● Also create counters & accumulators
● Automatically created in the shells (called sc)
● Specify master & app name when creating
○ Master can be local[*], spark:// , yarn, etc.
○ app name should be human readable and make sense
● etc.
Petfu
l](https://image.slidesharecdn.com/improvingpysparkperformance-sparkbeyondthejvmpydatadc20161-161009210704/85/Improving-PySpark-Performance-Spark-Beyond-the-JVM-PyData-DC-2016-8-320.jpg)










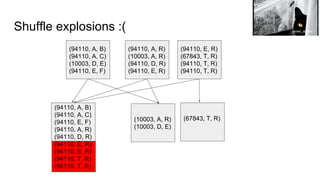
![So what does that look like?
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://image.slidesharecdn.com/improvingpysparkperformance-sparkbeyondthejvmpydatadc20161-161009210704/85/Improving-PySpark-Performance-Spark-Beyond-the-JVM-PyData-DC-2016-21-320.jpg)











![Sample json record
{"name":"mission",
"pandas":[{"id":1,"zip":"94110","pt":"giant",
"happy":true, "attributes":[0.4,0.5]}]}
Xiahong Chen](https://image.slidesharecdn.com/improvingpysparkperformance-sparkbeyondthejvmpydatadc20161-161009210704/85/Improving-PySpark-Performance-Spark-Beyond-the-JVM-PyData-DC-2016-38-320.jpg)





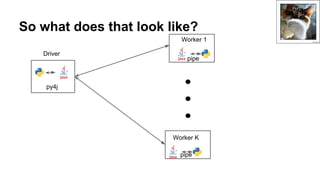
![Calling the functions with py4j*:
● The SparkContext has a reference to the jvm (_jvm)
● Many Python objects which are wrappers of JVM
objects have _j[objtype] to get the JVM object
○ rdd._jrdd
○ df._jdf
○ sc._jsc
● These are private and may change
*The py4j bridge only exists on the driver**
** Not exactly true but close enough
Fiona
Henderson](https://image.slidesharecdn.com/improvingpysparkperformance-sparkbeyondthejvmpydatadc20161-161009210704/85/Improving-PySpark-Performance-Spark-Beyond-the-JVM-PyData-DC-2016-44-320.jpg)




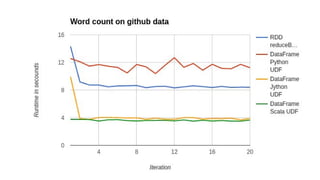








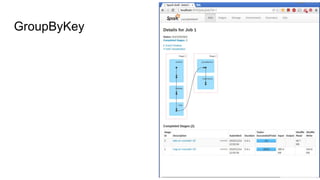
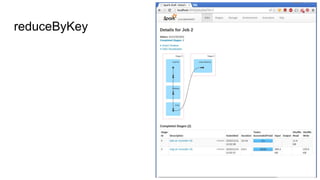
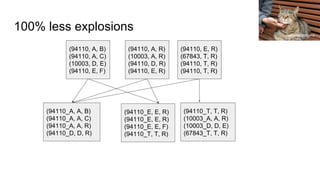
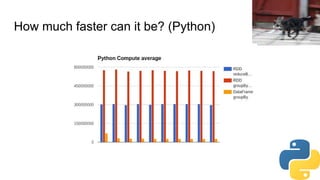
The document discusses improving PySpark performance, emphasizing the internal workings of PySpark, including RDD re-use, Spark SQL, and DataFrames. It highlights the importance of avoiding key skew and the pitfalls of using 'group by key' in distributed computing. The author also outlines potential future improvements in PySpark, including better interoperability with Scala code and performance enhancements through new frameworks.


































































