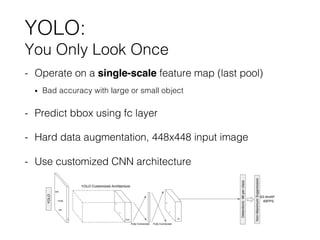
SSD is a single shot detector model that uses multiple feature maps from different layers to detect objects at different scales. It directly predicts bounding boxes and class probabilities using convolutional layers, unlike previous models that separated classification and regression. SSD achieves accuracy comparable to state-of-the-art models while running in real-time by using default bounding boxes of different aspect ratios on feature maps to predict offsets for object detection.







![SSD:
Single Shot Multibox Detector
- Output feature (final layer)
• With given output boxes from multi-scale features, sort them
using class confidence
• Pick top-200 boxes and make each box 7-dim vector
• [ batch_idx, class_confidence, label, box offset…]
• Output feature dim is 7x200
•](https://image.slidesharecdn.com/singleshotmultiboxdetector-161128091640/85/Single-Shot-Multibox-Detector-9-320.jpg)

















































![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)


























