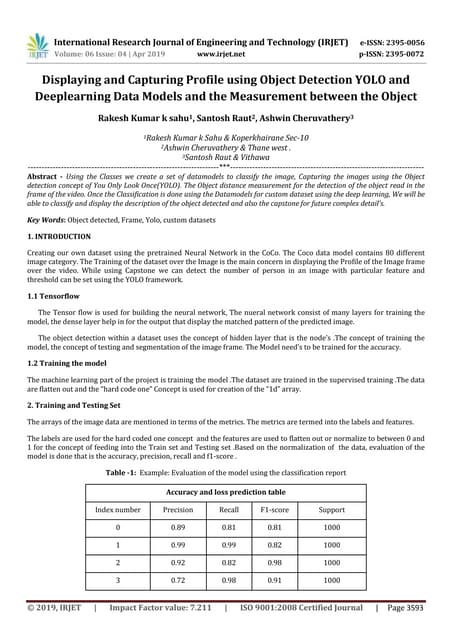
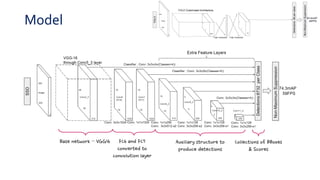
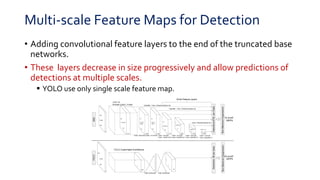
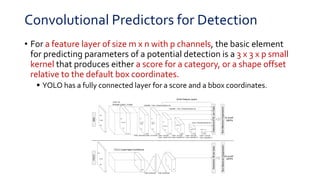
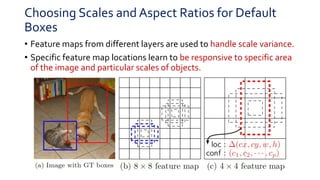
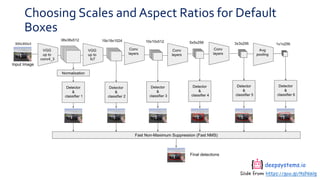
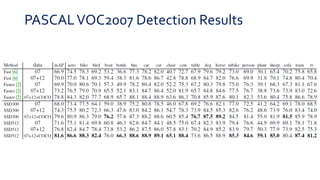
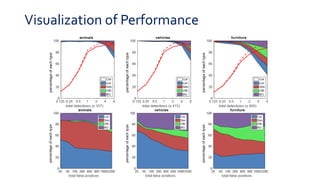
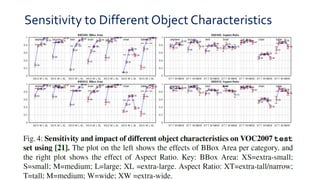
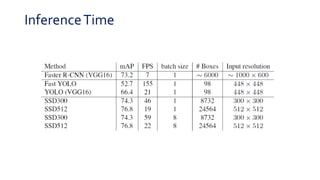
SSD is a single-shot object detector that processes the entire image at once, rather than proposing regions of interest. It uses a base VGG16 network with additional convolutional layers to predict bounding boxes and class probabilities at three scales simultaneously. SSD achieves state-of-the-art accuracy while running significantly faster than two-stage detectors like Faster R-CNN. It introduces techniques like default boxes, hard negative mining, and data augmentation to address class imbalance and improve results on small objects. On PASCAL VOC 2007, SSD detects objects at 59 FPS with 74.3% mAP, comparable to Faster R-CNN but much faster.









![Data Augmentation
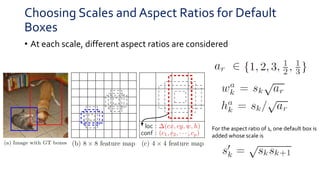
• Use the entire original input image.
• Sample a patch so that the minimum jaccard overlap with the
objects is 0.1, 0.3, 0.5, 0.7 or 0.9.
• Randomly sample a patch.
• The size of each sampled patch is [0,1, 1] of the original image size
• Aspect ratio is between ½ and 2.
• Horizontally flipped with probability of 0.5](https://image.slidesharecdn.com/pr12ssd-190106144735/85/PR-132-SSD-Single-Shot-MultiBox-Detector-19-320.jpg)














![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)