The document contains code snippets demonstrating the use of TensorFlow for building and training neural networks. It shows how to:
1. Define operations like convolutions, max pooling, fully connected layers using common TensorFlow functions like tf.nn.conv2d and tf.nn.max_pool.
2. Create and initialize variables using tf.Variable and initialize them using tf.global_variables_initializer.
3. Construct a multi-layer perceptron model for MNIST classification with convolutional and fully connected layers.
4. Train the model using tf.train.AdamOptimizer by running optimization steps and calculating loss over batches of data.
5. Evaluate the trained model on test data to calculate accuracy.




![>>> import numpy as np
>>> a = np.zeros((2, 2)); b = np.ones((2, 2))
>>> np.sum(b, axis=1)
array([ 2., 2.])
>>> a.shape
(2, 2)
>>> np.reshape(a, (1, 4))
array([[ 0., 0., 0., 0.]])](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-5-320.jpg)
![>>> import tensorflow as tf
>>> sess = tf.Session()
>>> a = tf.zeros((2, 2)); b = tf.ones((2, 2))
>>> sess.run(tf.reduce_sum(b, axis=1))
[ 2., 2.]
>>> a.get_shape()
(2, 2)
>>> sess.run(tf.reshape(a, (1, 4)))
[[ 0., 0., 0., 0.]]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-6-320.jpg)
![sess.run()
>>> sess = tf.Session()
>>> a = np.zeros((2, 2)); ta = tf.zeros((2, 2))
>>> print(a)
[[ 0. 0.]
[ 0. 0.]]
>>> print(ta)
Tensor("zeros:0", shape=(2, 2), dtype=float32)
>>> print(sess.run(ta))
[[ 0. 0.]
[ 0. 0.]]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-7-320.jpg)
![sess.run()
>>> sess = tf.Session()
>>> a = np.zeros((2, 2)); ta = tf.zeros((2, 2))
>>> print(a)
[[ 0. 0.]
[ 0. 0.]]
>>> print(ta)
Tensor("zeros:0", shape=(2, 2), dtype=float32)
>>> print(sess.run(ta))
[[ 0. 0.]
[ 0. 0.]]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-8-320.jpg)







![>>> w = tf.Variable(tf.random_normal([5, 2], stddev=0.1),
name="weight")
>>> with tf.Session() as sess:
>>> sess.run(tf.global_variables_initializer())
>>> print(sess.run(w))
[[-0.10020355 -0.01114563]
[ 0.04050281 -0.15980773]
[-0.00628474 -0.02608337]
[ 0.16397022 0.02898547]
[ 0.04264377 0.04281621]]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-16-320.jpg)
![>>> w = tf.Variable(tf.random_normal([5, 2], stddev=0.1),
name="weight")
>>> with tf.Session() as sess:
>>> sess.run(tf.global_variables_initializer())
>>> print(sess.run(w))
[[-0.10020355 -0.01114563]
[ 0.04050281 -0.15980773]
[-0.00628474 -0.02608337]
[ 0.16397022 0.02898547]
[ 0.04264377 0.04281621]]
tf.Variable](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-17-320.jpg)
![>>> w = tf.Variable(tf.random_normal([5, 2], stddev=0.1),
name="weight")
>>> with tf.Session() as sess:
>>> sess.run(tf.global_variables_initializer())
>>> print(sess.run(w))
[[-0.10020355 -0.01114563]
[ 0.04050281 -0.15980773]
[-0.00628474 -0.02608337]
[ 0.16397022 0.02898547]
[ 0.04264377 0.04281621]]
tf.Variable
tf.Variable](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-18-320.jpg)

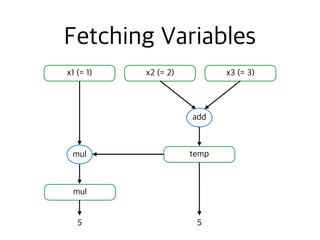
![>>> x1 = tf.constant(1)
>>> x2 = tf.constant(2)
>>> x3 = tf.constant(3)
>>> temp = tf.add(x2, x3)
>>> mul = tf.mul(x1, temp)
>>> with tf.Session() as sess:
>>> result1, result2 = sess.run([mul, temp])
>>> print(result1, result2)
5 5](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-20-320.jpg)
![>>> x1 = tf.constant(1)
>>> x2 = tf.constant(2)
>>> x3 = tf.constant(3)
>>> temp = tf.add(x2, x3)
>>> mul = tf.mul(x1, temp)
>>> with tf.Session() as sess:
>>> result1, result2 = sess.run([mul, temp])
>>> print(result1, result2)
5 5
sess.run(var)
sess.run([var1, .. ,])](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-21-320.jpg)



![# using tf.constant
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
with tf.Session() as sess:
result = sess.run(product)
print(result)
# using placeholder
import numpy as np
matrix1 = tf.placeholder(tf.float32, [1, 2])
matrix2 = tf.placeholder(tf.float32, [2, 1])
product = tf.matmul(matrix1, matrix2)
with tf.Session() as sess:
mv1 = np.array([[3., 3.]])
mv2 = np.array([[2.], [2.]])
result = sess.run(product, feed_dict={matrix1: mv1, matrix2: mv2})
print(result)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-26-320.jpg)
![import tensorflow as tf
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/",
one_hot=True)
learning_rate = 0.001
max_steps = 15000
batch_size = 128
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-27-320.jpg)
![def MLP(inputs):
W_1 = tf.Variable(tf.random_normal([784, 256]))
b_1 = tf.Variable(tf.zeros([256]))
W_2 = tf.Variable(tf.random_normal([256, 256]))
b_2 = tf.Variable(tf.zeros([256]))
W_out = tf.Variable(tf.random_normal([256, 10]))
b_out = tf.Variable(tf.zeros([10]))
h_1 = tf.add(tf.matmul(inputs, W_1), b_1)
h_1 = tf.nn.relu(h_1)
h_2 = tf.add(tf.matmul(h_1, W_2), b_2)
h_2 = tf.nn.relu(h_2)
out = tf.add(tf.matmul(h_2, W_out), b_out)
return out
net = MLP(x)
# define loss and optimizer
loss_op = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(net, y))
opt = tf.train.AdamOptimizer(learning_rate).minimize(loss_op)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-28-320.jpg)
![# initializing the variables
init_op = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init_op)
# train model
for step in range(max_steps):
batch_X, batch_y = mnist.train.next_batch(batch_size)
_, loss = sess.run([opt, loss_op],
feed_dict={x: batch_X, y: batch_y})
if (step+1) % 1000 == 0:
print("[{}/{}] loss:{:.3f}".format(step+1, max_steps, loss))
print("Optimization Finished!")
# test model
correct_prediction = tf.equal(tf.argmax(net, 1), tf.argmax(y, 1))
# calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Train accuracy: {:.3f}” .format(sess.run(accuracy,
feed_dict={x: mnist.train.images, y: mnist.train.labels})))
print("Test accuracy: {:.3f}” .format(sess.run(accuracy,
feed_dict={x: mnist.test.images, y: mnist.test.labels})))](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-29-320.jpg)


![tf.variable_scope()
var1 = tf.Variable([1], name="var")
with tf.variable_scope("foo"):
with tf.variable_scope("bar"):
var2 = tf.Variable([1], name="var")
var3 = tf.Variable([1], name="var")
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}”.format(var3.name))
var1: var:0
var2: foo/bar/var:0
var3: foo/bar/var_1:0](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-34-320.jpg)
![tf.get_variable()
tf.Variable
var1 = tf.Variable([1], name="var")
with tf.variable_scope("foo"):
with tf.variable_scope("bar") as scp:
var2 = tf.Variable([1], name="var")
scp.reuse_variables() # allow reuse variables
var3 = tf.Variable([1], name="var")
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}”.format(var3.name))
var1: var:0
var2: foo/bar/var:0
var3: foo/bar/var_1:0](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-35-320.jpg)
![tf.get_variable()
tf.Variable
var1 = tf.Variable([1], name="var")
with tf.variable_scope("foo"):
with tf.variable_scope("bar") as scp:
var2 = tf.Variable([1], name="var")
scp.reuse_variables() # allow reuse variables
var3 = tf.Variable([1], name="var")
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}”.format(var3.name))
var1: var:0
var2: foo/bar/var:0
var3: foo/bar/var_1:0
var3 foo/bar/var:0
tf.Variable](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-36-320.jpg)
![tf.get_variable()
var1 = tf.get_variable("var", [1])
with tf.variable_scope("foo"):
with tf.variable_scope("bar") as scp:
var2 = tf.get_variable("var", [1])
scp.reuse_variables() # allow reuse variables
var3 = tf.get_variable("var", [1])
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}".format(var3.name))
var1: var:0
var2: foo/bar/var:0
var3: foo/bar/var:0](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-37-320.jpg)
![tf.get_variable()
var1 = tf.get_variable("var", [1])
with tf.variable_scope("foo"):
with tf.variable_scope("bar") as scp:
var2 = tf.get_variable("var", [1])
scp.reuse_variables() # allow reuse variables
var3 = tf.get_variable("var", [1])
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}".format(var3.name))
var1: var:0
var2: foo/bar/var:0
var3: foo/bar/var:0](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-38-320.jpg)

![with tf.variable_scope("foo"):
with tf.variable_scope("bar") as scp:
var1 = tf.get_variable("var", [1])
scp.reuse_variables()
var2 = tf.get_variable("var", [1])
with tf.variable_scope("bar", reuse=True):
var3 = tf.get_variable("var", [1])
print("var1: {}".format(var1.name))
print("var2: {}".format(var2.name))
print("var3: {}”.format(var3.name))
var1: foo/bar/var:0
var2: foo/bar/var:0
var3: foo/bar/var:0](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-40-320.jpg)



![from tensorflow.contrib.layers import variance_scaling_initializer
he_init = variance_scaling_initializer()
def conv(bottom,
num_filter, ksize=3, stride=1, padding="SAME",
scope=None):
bottom_shape = bottom.get_shape().as_list()[3]
with tf.variable_scope(scope or "conv"):
W = tf.get_variable("W",
[ksize, ksize, bottom_shape, num_filter],
initializer=he_init)
b = tf.get_variable("b", [num_filter],
initializer=tf.constant_initializer(0))
x = tf.nn.conv2d(bottom, W,
strides=[1, stride, stride, 1],
padding=padding)
x = tf.nn.relu(tf.nn.bias_add(x, b))
return x](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-44-320.jpg)
![from tensorflow.contrib.layers import variance_scaling_initializer
he_init = variance_scaling_initializer()
def conv(bottom,
num_filter, ksize=3, stride=1, padding="SAME",
scope=None):
bottom_shape = bottom.get_shape().as_list()[3]
with tf.variable_scope(scope or "conv"):
W = tf.get_variable("W",
[ksize, ksize, bottom_shape, num_filter],
initializer=he_init)
b = tf.get_variable("b", [num_filter],
initializer=tf.constant_initializer(0))
x = tf.nn.conv2d(bottom, W,
strides=[1, stride, stride, 1],
padding=padding)
x = tf.nn.relu(tf.nn.bias_add(x, b))
return x](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-45-320.jpg)
![from tensorflow.contrib.layers import variance_scaling_initializer
he_init = variance_scaling_initializer()
def conv(bottom,
num_filter, ksize=3, stride=1, padding="SAME",
scope=None):
bottom_shape = bottom.get_shape().as_list()[3]
with tf.variable_scope(scope or "conv"):
W = tf.get_variable("W",
[ksize, ksize, bottom_shape, num_filter],
initializer=he_init)
b = tf.get_variable("b", [num_filter],
initializer=tf.constant_initializer(0))
x = tf.nn.conv2d(bottom, W,
strides=[1, stride, stride, 1],
padding=padding)
x = tf.nn.relu(tf.nn.bias_add(x, b))
return x](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-46-320.jpg)
![def maxpool(bottom,
ksize=2, stride=2, padding="SAME",
scope=None):
with tf.variable_scope(scope or "maxpool"):
pool = tf.nn.max_pool(bottom, ksize=[1, ksize, ksize, 1],
strides=[1, stride, stride, 1],
padding=padding)
return pool](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-47-320.jpg)
![def fc(bottom, num_dims, scope=None):
bottom_shape = bottom.get_shape().as_list()
if len(bottom_shape) > 2:
bottom = tf.reshape(bottom,
[-1, reduce(lambda x, y: x*y, bottom_shape[1:])])
bottom_shape = bottom.get_shape().as_list()
with tf.variable_scope(scope or "fc"):
W = tf.get_variable("W", [bottom_shape[1], num_dims],
initializer=he_init)
b = tf.get_variable("b", [num_dims],
initializer=tf.constant_initializer(0))
out = tf.nn.bias_add(tf.matmul(bottom, W), b)
return out
def fc_relu(bottom, num_dims, scope=None):
with tf.variable_scope(scope or "fc"):
out = fc(bottom, num_dims, scope="fc")
relu = tf.nn.relu(out)
return relu](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-48-320.jpg)
![def fc(bottom, num_dims, scope=None):
bottom_shape = bottom.get_shape().as_list()
if len(bottom_shape) > 2:
bottom = tf.reshape(bottom,
[-1, reduce(lambda x, y: x*y, bottom_shape[1:])])
bottom_shape = bottom.get_shape().as_list()
with tf.variable_scope(scope or "fc"):
W = tf.get_variable("W", [bottom_shape[1], num_dims],
initializer=he_init)
b = tf.get_variable("b", [num_dims],
initializer=tf.constant_initializer(0))
out = tf.nn.bias_add(tf.matmul(bottom, W), b)
return out
def fc_relu(bottom, num_dims, scope=None):
with tf.variable_scope(scope or "fc"):
out = fc(bottom, num_dims, scope="fc")
relu = tf.nn.relu(out)
return relu](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-49-320.jpg)
![keep_prob = tf.placeholder(tf.float32, None)
def conv_net(x, keep_prob):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
conv1 = conv(x, 32, 5, scope="conv_1")
conv1 = maxpool(conv1, scope="maxpool_1")
conv2 = conv(conv1, 64, 5, scope="conv_2")
conv2 = maxpool(conv2, scope="maxpool_2")
fc1 = fc_relu(conv2, 1024, scope="fc_1")
fc1 = tf.nn.dropout(fc1, keep_prob)
out = fc(fc1, 10, scope="out")
return out](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-50-320.jpg)
![keep_prob = tf.placeholder(tf.float32, None)
def conv_net(x, keep_prob):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
conv1 = conv(x, 32, 5, scope="conv_1")
conv1 = maxpool(conv1, scope="maxpool_1")
conv2 = conv(conv1, 64, 5, scope="conv_2")
conv2 = maxpool(conv2, scope="maxpool_2")
fc1 = fc_relu(conv2, 1024, scope="fc_1")
fc1 = tf.nn.dropout(fc1, keep_prob)
out = fc(fc1, 10, scope="out")
return out](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-51-320.jpg)





![input = ...
with tf.name_scope('conv1_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128],
dtype=tf.float32, stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1],
padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-57-320.jpg)
![input = ...
with tf.name_scope('conv1_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128],
dtype=tf.float32, stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1],
padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128],
dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
input = ...
net = slim.conv2d(input, 128, [3, 3],
padding=‘SAME’, scope=‘conv1_1')](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-58-320.jpg)
![# 1. simple network generation with slim
net = ...
net = slim.conv2d(net, 256, [3, 3], scope='conv3_1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_2')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_3')
net = slim.max_pool2d(net, [2, 2], scope=‘pool3')
# 1. cleaner by repeat operation:
net = ...
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3],
scope='conv3')
net = slim.max_pool(net, [2, 2], scope=‘pool3')
# 2. Verbose way:
x = slim.fully_connected(x, 32, scope='fc/fc_1')
x = slim.fully_connected(x, 64, scope='fc/fc_2')
x = slim.fully_connected(x, 128, scope='fc/fc_3')
# 2. Equivalent, TF-Slim way using slim.stack:
slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-59-320.jpg)
![• tf.truncated_normal_initializer tf
• slim.xavier_initializer
• slim.variance_scaling_initializer
• slim.l1_regularizer
• slim.l2_regularizer
• …
net = slim.conv2d(inputs, 64, [11, 11], 4, padding=‘SAME',
weights_initializer=slim.xavier_initializer(),
weights_regularizer=slim.l2_regularizer(0.0005),
scope='conv1')](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-60-320.jpg)
![he_init = slim.variance_scaling_initializer()
xavier_init = slim.xavier_initializer()
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=he_init,
weights_regularizer=slim.l2_regularizer(0.0005)):
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
net = slim.conv2d(inputs, 64, [11, 11], 4, scope='conv1')
net = slim.conv2d(net, 256, [5, 5],
weights_initializer=xavier_init,
scope='conv2')
net = slim.fully_connected(net, 1000,
activation_fn=None, scope='fc')](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-61-320.jpg)
![he_init = slim.variance_scaling_initializer()
xavier_init = slim.xavier_initializer()
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=he_init,
weights_regularizer=slim.l2_regularizer(0.0005)):
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
net = slim.conv2d(inputs, 64, [11, 11], 4, scope='conv1')
net = slim.conv2d(net, 256, [5, 5],
weights_initializer=xavier_init,
scope='conv2')
net = slim.fully_connected(net, 1000,
activation_fn=None, scope='fc')
[..]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-62-320.jpg)
![he_init = slim.variance_scaling_initializer()
xavier_init = slim.xavier_initializer()
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=he_init,
weights_regularizer=slim.l2_regularizer(0.0005)):
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
net = slim.conv2d(inputs, 64, [11, 11], 4, scope='conv1')
net = slim.conv2d(net, 256, [5, 5],
weights_initializer=xavier_init,
scope='conv2')
net = slim.fully_connected(net, 1000,
activation_fn=None, scope='fc')
[..]](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-63-320.jpg)



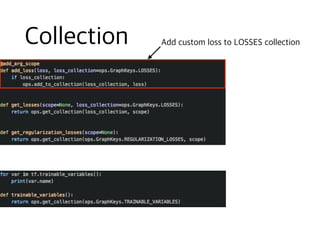
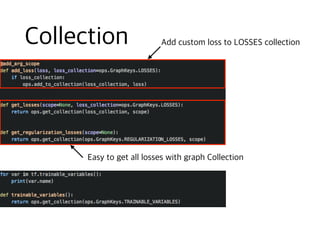
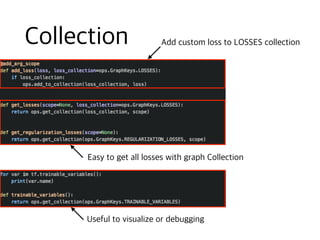
![def save(self, ckpt_dir, global_step=None):
if self.config.get("saver") is None:
self.config["saver"] =
tf.train.Saver(max_to_keep=30)
saver = self.config["saver"]
sess = self.config["sess"]
dirname = os.path.join(ckpt_dir, self.name)
if not os.path.exists(dirname):
os.makedirs(dirname)
saver.save(sess, dirname, global_step)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-70-320.jpg)
![def save(self, ckpt_dir, global_step=None):
if self.config.get("saver") is None:
self.config["saver"] =
tf.train.Saver(max_to_keep=30)
saver = self.config["saver"]
sess = self.config["sess"]
dirname = os.path.join(ckpt_dir, self.name)
if not os.path.exists(dirname):
os.makedirs(dirname)
saver.save(sess, dirname, global_step)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-71-320.jpg)
![def save(self, ckpt_dir, global_step=None):
if self.config.get("saver") is None:
self.config["saver"] =
tf.train.Saver(max_to_keep=30)
saver = self.config["saver"]
sess = self.config["sess"]
dirname = os.path.join(ckpt_dir, self.name)
if not os.path.exists(dirname):
os.makedirs(dirname)
saver.save(sess, dirname, global_step)
dirname
global_step](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-72-320.jpg)
![def load_latest_checkpoint(self, ckpt_dir, exclude=None):
path = tf.train.latest_checkpoint(ckpt_dir)
if path is None:
raise AssertionError("No ckpt exists in {0}.".format(ckpt_dir))
print("Load {} save file".format(path))
self._load(path, exclude)
def load_from_path(self, ckpt_path, exclude=None):
self._load(ckpt_path, exclude)
def _load(self, ckpt_path, exclude):
init_fn = slim.assign_from_checkpoint_fn(ckpt_path,
slim.get_variables_to_restore(exclude=exclude),
ignore_missing_vars=True)
init_fn(self.config["sess"])](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-73-320.jpg)
![def load_latest_checkpoint(self, ckpt_dir, exclude=None):
path = tf.train.latest_checkpoint(ckpt_dir)
if path is None:
raise AssertionError("No ckpt exists in {0}.".format(ckpt_dir))
print("Load {} save file".format(path))
self._load(path, exclude)
def load_from_path(self, ckpt_path, exclude=None):
self._load(ckpt_path, exclude)
def _load(self, ckpt_path, exclude):
init_fn = slim.assign_from_checkpoint_fn(ckpt_path,
slim.get_variables_to_restore(exclude=exclude),
ignore_missing_vars=True)
init_fn(self.config["sess"])
exclude](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-74-320.jpg)
![def load_latest_checkpoint(self, ckpt_dir, exclude=None):
path = tf.train.latest_checkpoint(ckpt_dir)
if path is None:
raise AssertionError("No ckpt exists in {0}.".format(ckpt_dir))
print("Load {} save file".format(path))
self._load(path, exclude)
def load_from_path(self, ckpt_path, exclude=None):
self._load(ckpt_path, exclude)
def _load(self, ckpt_path, exclude):
init_fn = slim.assign_from_checkpoint_fn(ckpt_path,
slim.get_variables_to_restore(exclude=exclude),
ignore_missing_vars=True)
init_fn(self.config["sess"])
exclude
False
True](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-75-320.jpg)


![X = tf.placeholder(tf.float32, [None, 224, 224, 3], name="X")
y = tf.placeholder(tf.int32, [None, 8], name="y")
is_training = tf.placeholder(tf.bool, name="is_training")
with slim.arg_scope(vgg.vgg_arg_scope()):
net, end_pts = vgg.vgg_16(X, is_training=is_training,
num_classes=1000)
with tf.variable_scope("losses"):
cls_loss = slim.losses.softmax_cross_entropy(net, y)
reg_loss = tf.add_n(slim.losses.get_regularization_losses())
loss_op = type_loss + reg_loss
with tf.variable_scope("opt"):
opt = tf.train.AdamOptimizer(0.001).minimize(loss_op)
self.load_from_path(ckpt_path=VGG_PATH, exclude=["vgg_16/fc8"])
...](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-78-320.jpg)
![X = tf.placeholder(tf.float32, [None, 224, 224, 3], name="X")
y = tf.placeholder(tf.int32, [None, 8], name="y")
is_training = tf.placeholder(tf.bool, name="is_training")
with slim.arg_scope(vgg.vgg_arg_scope()):
net, end_pts = vgg.vgg_16(X, is_training=is_training,
num_classes=1000)
with tf.variable_scope("losses"):
cls_loss = slim.losses.softmax_cross_entropy(net, y)
reg_loss = tf.add_n(slim.losses.get_regularization_losses())
loss_op = type_loss + reg_loss
with tf.variable_scope("opt"):
opt = tf.train.AdamOptimizer(0.001).minimize(loss_op)
self.load_from_path(ckpt_path=VGG_PATH, exclude=["vgg_16/fc8"])
...
fc8
trainable=False](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-79-320.jpg)
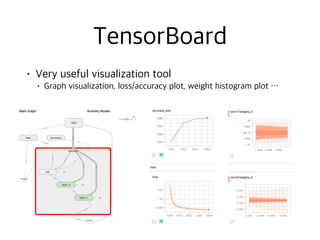

![import tensorflow as tf
slim = tf.contrib.slim
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
max_steps = 10000
batch_size = 128
lr = 0.001
keep_prob = 0.5
weight_decay = 0.0004
logs_path = "/tmp/tensorflow_logs/example"
def my_arg_scope(is_training, weight_decay):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
biases_initializer=tf.zeros_initializer,
stride=1, padding="SAME"):
with slim.arg_scope([slim.dropout],
is_training=is_training) as arg_sc:
return arg_sc](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-82-320.jpg)
![def my_net(x, keep_prob, outputs_collections="my_net"):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
with slim.arg_scope([slim.conv2d, slim.max_pool2d],
outputs_collections=outputs_collections):
net = slim.conv2d(x, 64, [3, 3], scope="conv1")
net = slim.max_pool2d(net, [2, 2], scope="pool1")
net = slim.conv2d(net, 128, [3, 3], scope="conv2")
net = slim.max_pool2d(net, [2, 2], scope="pool2")
net = slim.conv2d(net, 256, [3, 3], scope="conv3")
# global average pooling
net = tf.reduce_mean(net, [1, 2], name="pool3", keep_dims=True)
net = slim.dropout(net, keep_prob, scope="dropout3")
net = slim.conv2d(net, 1024, [1, 1], scope="fc4")
net = slim.dropout(net, keep_prob, scope="dropout4")
net = slim.conv2d(net, 10, [1, 1],
activation_fn=None, scope="fc5")
end_points =
slim.utils.convert_collection_to_dict(outputs_collections)
return tf.reshape(net, [-1, 10]), end_points](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-83-320.jpg)
![def my_net(x, keep_prob, outputs_collections="my_net"):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
with slim.arg_scope([slim.conv2d, slim.max_pool2d],
outputs_collections=outputs_collections):
net = slim.conv2d(x, 64, [3, 3], scope="conv1")
net = slim.max_pool2d(net, [2, 2], scope="pool1")
net = slim.conv2d(net, 128, [3, 3], scope="conv2")
net = slim.max_pool2d(net, [2, 2], scope="pool2")
net = slim.conv2d(net, 256, [3, 3], scope="conv3")
# global average pooling
net = tf.reduce_mean(net, [1, 2], name="pool3", keep_dims=True)
net = slim.dropout(net, keep_prob, scope="dropout3")
net = slim.conv2d(net, 1024, [1, 1], scope="fc4")
net = slim.dropout(net, keep_prob, scope="dropout4")
net = slim.conv2d(net, 10, [1, 1],
activation_fn=None, scope="fc5")
end_points =
slim.utils.convert_collection_to_dict(outputs_collections)
return tf.reshape(net, [-1, 10]), end_points](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-84-320.jpg)
![x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
is_training = tf.placeholder(tf.bool)
with slim.arg_scope(my_arg_scope(is_training, weight_decay)):
net, end_pts = my_net(x, keep_prob)
pred = slim.softmax(net, scope="prediction")
with tf.variable_scope("losses"):
cls_loss = slim.losses.softmax_cross_entropy(net, y)
reg_loss = tf.add_n(slim.losses.get_regularization_losses())
loss_op = cls_loss + reg_loss
with tf.variable_scope("Adam"):
opt = tf.train.AdamOptimizer(lr)
# Op to calculate every variable gradient
grads = tf.gradients(loss_op, tf.trainable_variables())
grads = list(zip(grads, tf.trainable_variables()))
# Op to update all variables according to their gradient
apply_grads = opt.apply_gradients(grads_and_vars=grads)
with tf.variable_scope("accuracy"):
correct_op = tf.equal(tf.argmax(net, 1), tf.argmax(y, 1))
acc_op = tf.reduce_mean(tf.cast(correct_op, tf.float32))](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-85-320.jpg)
![x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
is_training = tf.placeholder(tf.bool)
with slim.arg_scope(my_arg_scope(is_training, weight_decay)):
net, end_pts = my_net(x, keep_prob)
pred = slim.softmax(net, scope="prediction")
with tf.variable_scope("losses"):
cls_loss = slim.losses.softmax_cross_entropy(net, y)
reg_loss = tf.add_n(slim.losses.get_regularization_losses())
loss_op = cls_loss + reg_loss
with tf.variable_scope("Adam"):
opt = tf.train.AdamOptimizer(lr)
# Op to calculate every variable gradient
grads = tf.gradients(loss_op, tf.trainable_variables())
grads = list(zip(grads, tf.trainable_variables()))
# Op to update all variables according to their gradient
apply_grads = opt.apply_gradients(grads_and_vars=grads)
with tf.variable_scope("accuracy"):
correct_op = tf.equal(tf.argmax(net, 1), tf.argmax(y, 1))
acc_op = tf.reduce_mean(tf.cast(correct_op, tf.float32))](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-86-320.jpg)
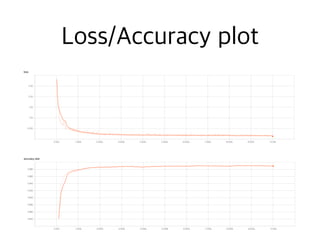
![# Create a summary to monitor loss and accuracy
summ_loss = tf.summary.scalar("loss", loss_op)
summ_acc = tf.summary.scalar("accuracy_test", acc_op)
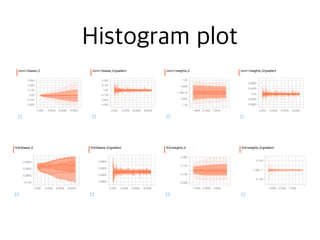
# Create summaries to visualize weights and grads
for var in tf.trainable_variables():
tf.summary.histogram(var.name, var, collections=["my_summ"])
for grad, var in grads:
tf.summary.histogram(var.name + "/gradient", grad,
collections=["my_summ"])
summ_wg = tf.summary.merge_all(key="my_summ")
sess = tf.Session()
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter(logs_path,
graph=sess.graph)](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-87-320.jpg)
![for step in range(max_steps):
batch_X, batch_y = mnist.train.next_batch(batch_size)
_, loss, plot_loss, plot_wg = sess.run([apply_grads, loss_op,
summ_loss, summ_wg],
feed_dict={x: batch_X, y: batch_y, is_training: True})
summary_writer.add_summary(plot_loss, step)
summary_writer.add_summary(plot_wg, step)
if (step+1) % 100 == 0:
plot_acc = sess.run(summ_acc, feed_dict={x: mnist.test.images,
y: mnist.test.labels,
is_training: False})
summary_writer.add_summary(plot_acc, step)
print("Optimization Finished!")
test_acc = sess.run(acc_op, feed_dict={x: mnist.test.images,
y: mnist.test.labels,
is_training: False})
print("Test accuracy: {:.3f}".format(test_acc))](https://image.slidesharecdn.com/tensorflow-tutorial-170208055732/85/TensorFlow-Tutorial-88-320.jpg)
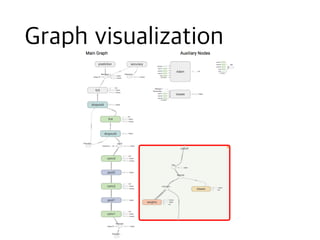
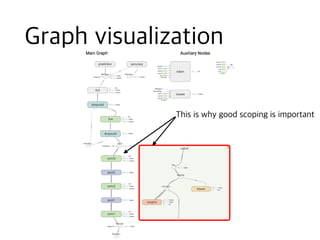





















![[신경망기초] 합성곱신경망](https://cdn.slidesharecdn.com/ss_thumbnails/2-180604135842-thumbnail.jpg?width=640&height=640&fit=bounds)