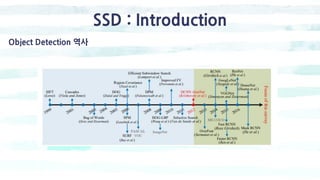
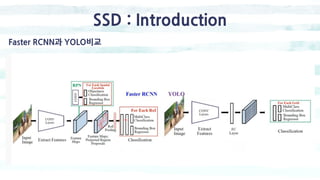
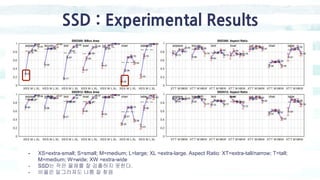
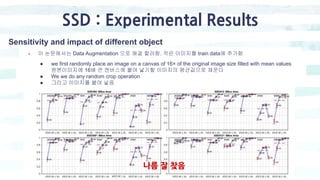
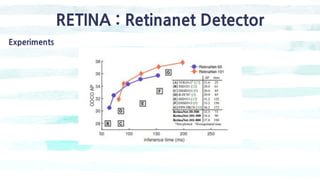
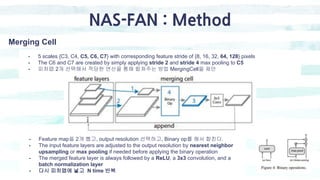
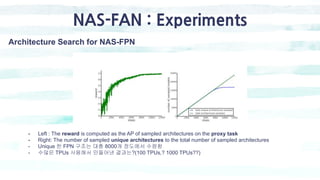
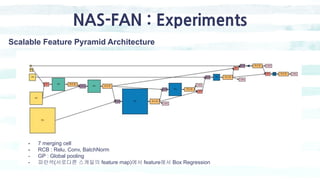
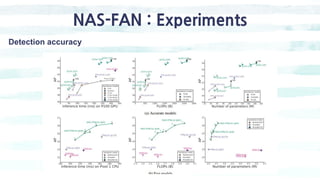
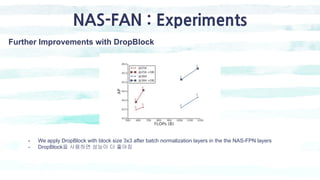
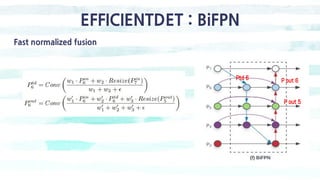
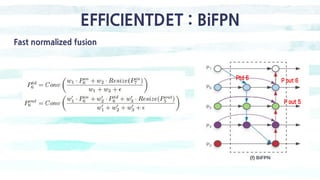
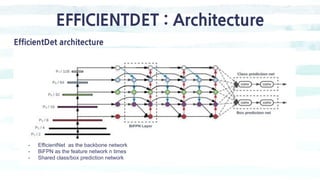
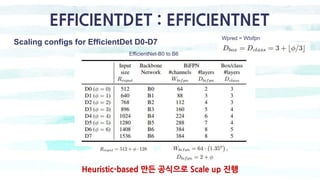
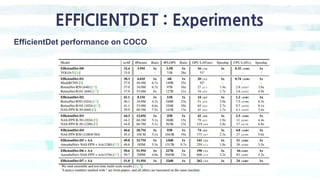
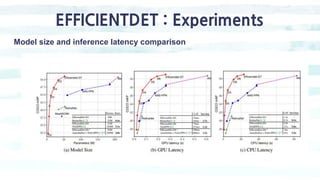
The document summarizes the SSD object detection model. SSD is a single-shot detector that performs object detection by predicting bounding boxes and class probabilities from multiple feature maps extracted from a base network. SSD improves speed over two-stage detectors like Faster R-CNN by performing detection in one stage without region proposals. It achieves this by using default bounding boxes of different scales and aspect ratios on multiple feature maps to detect objects. The document explains SSD's model architecture, training procedure, and experimental results, showing that SSD achieves real-time speeds while maintaining accuracy compared to other detectors.






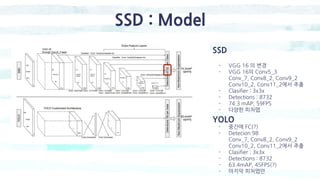

![SSD : Model
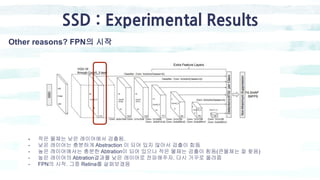
Convolutional predictors for detection 좀더 자세히
- Classifier : Conv: 3x3x(4x(Classes+4))
- 구조 : 첫번째 박스[(4개(dx, dy, dh, dw), 20개(Poscal voc기준 20 class), + 1개(bg)]
두번째, 세번째 , ~6번재박스까지
- 출력 채널 : 150 = 6 x (21 = 4)](https://image.slidesharecdn.com/singleshotmultiboxdetectors-200128112416/85/Single-shot-multiboxdetectors-10-320.jpg)











![RETINA : Focal loss
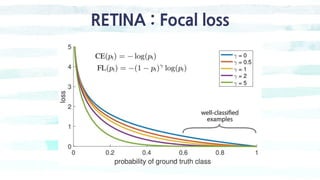
Focal Loss
- We introduce the focal loss starting from the cross entropy (CE) loss for binary classification
● y ∈ {±1} specifies the ground-truth class
● p ∈ [0, 1] is the model’s estimated probability for the class with label y = 1](https://image.slidesharecdn.com/singleshotmultiboxdetectors-200128112416/85/Single-shot-multiboxdetectors-27-320.jpg)




























































![[Paper] DetectoRS for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/paperdetectorsobjectdetection-210320013551-thumbnail.jpg?width=640&height=640&fit=bounds)



































