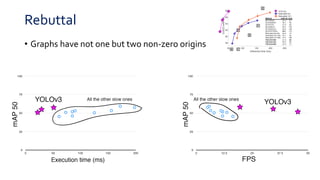
YOLOv3 makes the following incremental improvements over previous versions of YOLO:
1. It predicts bounding boxes at three different scales to detect objects more accurately at a variety of sizes.
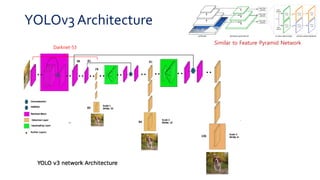
2. It uses Darknet-53 as its feature extractor, which provides better performance than ResNet while being faster to evaluate.
3. It predicts more bounding boxes overall (over 10,000) to detect objects more precisely, as compared to YOLOv2 which predicts around 800 boxes.












![ThingsWeTriedThat Didn’tWork
• Anchor box x, y offset predictions
Using the normal anchor box prediction mechanism where you predict the x,
y offset as a multiple of the box width or height
• Linear x, y predictions instead of logistic
• Focal loss
Focal loss droppedYOLOv3’s mAP about 2 points
• Dual IOU thresholds and truth assignment
Faster R-CNN uses two IOU thresholds during training. If a prediction
overlaps the ground truth by 0.7 it is as a positive example, by [0.3-0.7] it is
ignored, less than 0.3 for all ground truth objects it is a negative example.](https://image.slidesharecdn.com/pr12yolov3-191117141544/85/PR-207-YOLOv3-An-Incremental-Improvement-17-320.jpg)


















![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)








































































