Downloaded 10 times


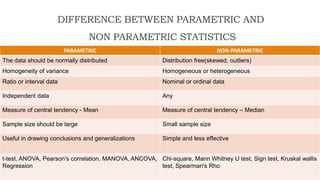






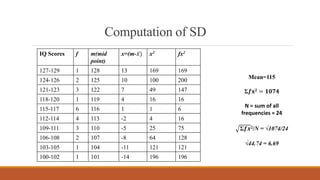
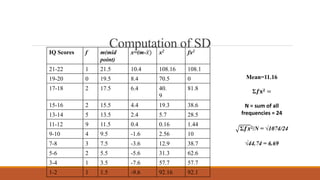
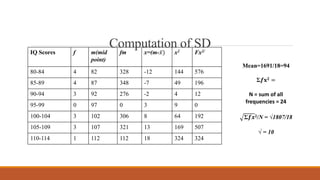








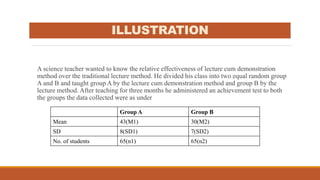

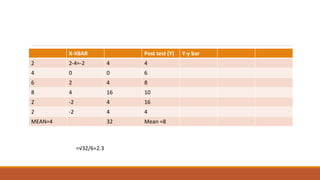


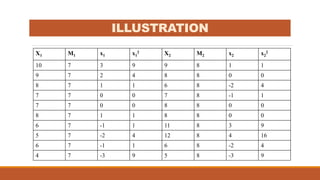





Standard deviation (SD) is a measure of variability or dispersion of data from the mean. It is calculated as the square root of the average of the squared deviations from the mean. The t-test is used to determine if there is a statistically significant difference between the means of two groups, and requires calculation of the standard error of the difference between the means. There are different procedures for the t-test depending on whether the samples are independent or correlated, large or small. The null hypothesis of no difference between means is tested against the alternative hypothesis at a chosen significance level.


























































![Human genome project [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/humangenomeprojectautosaved-210929062307-thumbnail.jpg?width=640&height=640&fit=bounds)




























