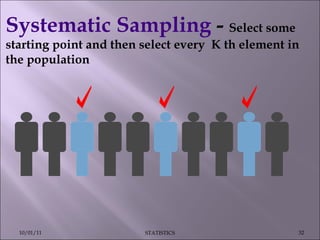
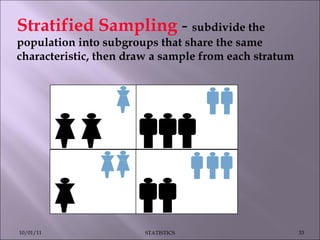
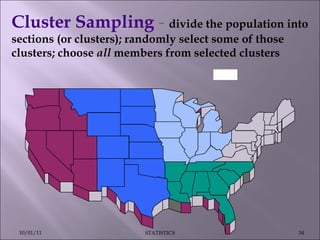
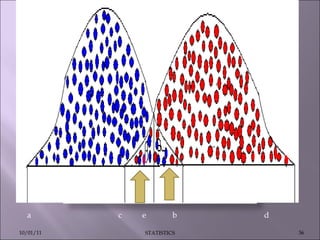
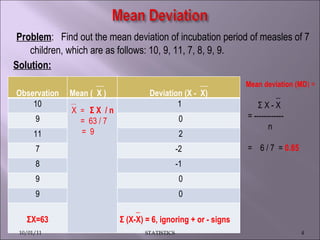
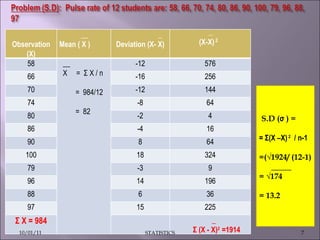
This document discusses various statistical concepts such as measures of central tendency, measures of dispersion, standard deviation, normal distribution, and tests of significance. It provides examples and formulas to calculate range, mean deviation, standard deviation, z-scores, confidence intervals, and the chi-square test. Biological variation is common and various statistical methods can be used to analyze data and find patterns in large datasets.





![Calculate the mean ↓ Calculate difference between each observation and mean ↓ Square the differences ↓ Sum the squared values ↓ Divide the sum of squares by the no. observations (n) to get ‘mean square deviation’ or variances (σ 2 ) . [For sample size < 30, it will be divided by (n-1)] ↓ Find the square root of variance to get Root-Means-Square-Deviation or S.D ( σ) 10/01/11 STATISTICS](https://image.slidesharecdn.com/presentation1groupb-111001011106-phpapp02/85/Presentation1group-b-6-320.jpg)













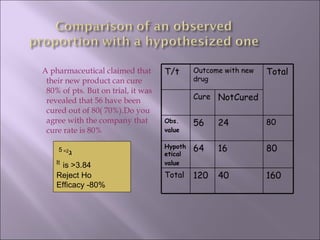
![Comparison of Proportions of >=2 samples Observed proportion with a hypothesized one ( goodness of fit ) Paired observations (McNemar test) LIMITATIONS – Yates’ correction reqd. if the expected value in each cell is <5 ∑ { O-E - ½} 2 E Or, =[(ad –bc)- n/2]2 Χ N (a+b)(c+d)(a+c)(b+d) B. In tables larger than 2 Χ 2, Yates’ correction not applicable C. Does n’t measure the strength, but tells of presence or absence of any association D. Statistical finding of relation doesnot indicate cause and effect](https://image.slidesharecdn.com/presentation1groupb-111001011106-phpapp02/85/Presentation1group-b-28-320.jpg)