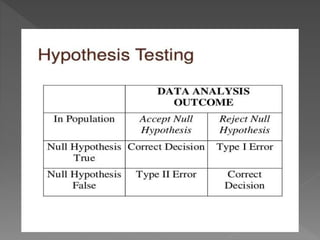
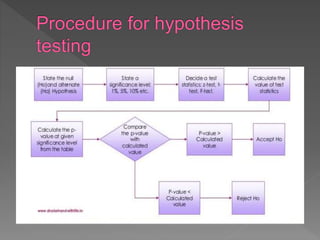
The document discusses hypotheses in research. A hypothesis is a testable statement about the relationship between two variables. Researchers propose a null hypothesis, which states there is no relationship between the variables, and an alternative or experimental hypothesis, which predicts a relationship. Statistical tests are used to analyze data and determine whether to reject the null hypothesis in favor of the alternative hypothesis. The document provides examples of different types of hypotheses and statistical tests used, including t-tests and z-tests.












































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)