Download to read offline


![Define the conditional probability mass function of X given that Y = y by
fX|Y (x|y) =
f(x, y)
fY (y)
=
f(x, y)
∞
−∞
f(x, y)dx
and the associated conditional expectation is given by
E(X|Y = y) =
∞
−∞
xfX|Y (x|y)dx.
5.1 Example 1
Suppose the joint density of X and Y is given by
f(x, y) =
6xy(2 − x − y), 0 < x < 1, 0 < y < 1
0, otherwise.
Let us compute the conditional expectation of X given Y = y where 0 < y < 1.
If y ∈ (0, 1) we have for x ∈ (0, 1) that
fX|Y (x|y) =
f(x, y)
fY (y)
=
f(x, y)
∞
−∞
f(x, y)dx
=
6xy(2 − x − y)
1
0
6xy(2 − x − y)dx
=
6xy(2 − x − y)
4 − 3y
Then
E(X|Y = y) =
5 − 4y
8 − 6y
where y ∈ (0, 1).
5.2 Example 2
Consider the triangle in the plane R whose vertices are (0, 0), (0, 1) and (1, 0).
Let X and Y be continuous random variables for which the joint density is given by
f(x, y) =
2, 0 ≤ x ≤ 1, 0 ≤ y ≤ 1, x + y ≤ 1
0, otherwise.
Let us compute the conditional expectation of X given Y = y where 0 ≤ y ≤ 1. 0 ≤ y ≤ 1 tells us that
x ∈ [0, 1 − y] and so
fX|Y (x|y) =
2
1−y
0
2dx
=
1
1 − y
. Then
E(X|Y = y) =
1−y
0
x(1 − y)−1
dx =
1 − y
2
.
6 Discrete-Time Markov Chains & Transition Matrix
Let X1, X2,..., be independent RVs each taking values -1 and 1 with probabilities q = 1 − p and p where
p ∈ (0, 1).
Define the random walk
Sn = a +
n
i=1
Xi
by the position of the movement after n steps having started at S0 = a (in most cases a = 0).
For p = 1
2 , q = 1 − p = 1
2 and so we would have a symmetric random walk.
3](https://image.slidesharecdn.com/fc3843dc-c6b2-428e-8958-33fde26a1083-161120222457/75/Probable-3-2048.jpg)




![10 More Examples of DTMC
A mobile robot randomly moves along a circular path divided into three sectors. At every sampling instant
the robot with probability p to move clockwise and with probability 1 − p to move counter-clockwise.
During the sampling interval the robot accomplishes the length of a sector.
• Define a discrete Markov chain for the random walk of the robot.
• Study the stationary probability that the robot is localized in each sector for p ∈ [0, 1].
State X = sector occupied by the robot ∈ {1, 2, 3}. The transition matrix reads
0 p 1 − p
1 − p 0 p
p 1 − p 0
For p = 0 we have
8](https://image.slidesharecdn.com/fc3843dc-c6b2-428e-8958-33fde26a1083-161120222457/75/Probable-8-2048.jpg)


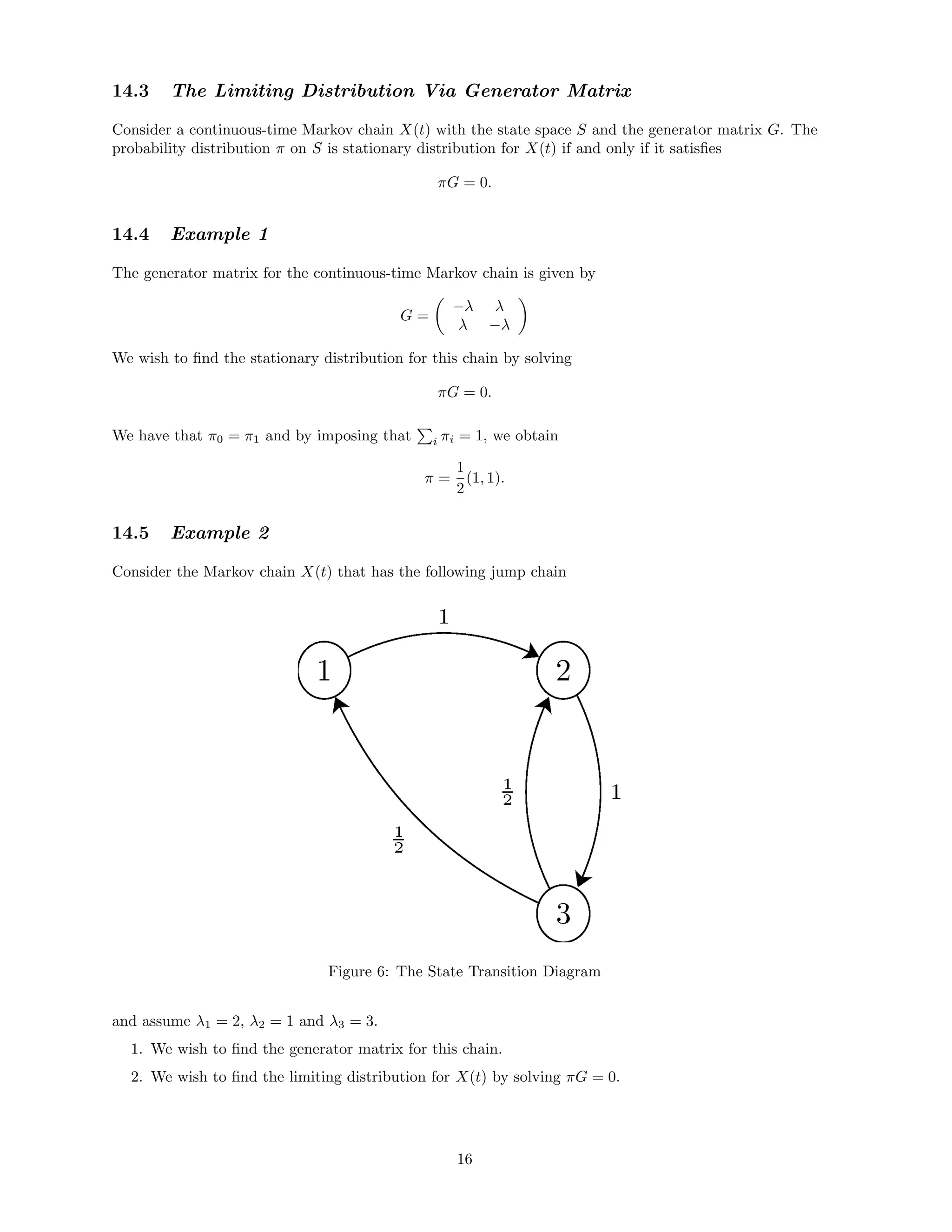
![12.2 The Solution: Part 1
There are two states in the chain and none of them are absorbing as λ0 = λ1 = λ 0. The jump chain
must therefore have the following transition matrix
P =
0 1
1 0
where the state-transition diagram of the embedded (jump) chain is
Figure 3: The State Transition Diagram
12.3 The Solution: Part 2
The Markov chain has a simple structure. Lets find P00(t). By definition
P00(t) = P(X(t) = 0|X(0) = 0), ∀t ∈ [0, ∞).
Assuming that X(0) = 0, X(t) will be 0 if and only if we have an even number of transitions in the time
interval [0, t]. The time between each transition is an eλ
random variable. Therefore, the transitions
occur according to a Poisson process with parameter λ.
We find
P00(t) =
∞
n=0
e−λt (λt)2n
(2n)!
= e−λt
∞
n=0
(λt)2n
(2n)!
= e−λt eλt
+ e−λt
2
=
1
2
+
1
2
e−2λt
P01(t) = 1 − P00(t) =
1
2
−
1
2
e−2λt
.
11](https://image.slidesharecdn.com/fc3843dc-c6b2-428e-8958-33fde26a1083-161120222457/75/Probable-11-2048.jpg)









1. A random variable (RV) is a function that maps outcomes of a random phenomenon to numerical values. For a function X to be an RV, the set P(x) = {ω: X(ω) ≤ x} must be an event with a well-defined probability P for any x. 2. Conditional probability P(A|B) is the probability of event A occurring given that event B has occurred. It is defined as P(A ∩ B)/P(B). 3. The law of total probability states that for mutually exclusive and exhaustive events B1, B2, ..., the probability of event A is the sum of the probabilities of A given each Bi multiplied by




















































































