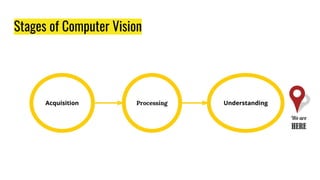
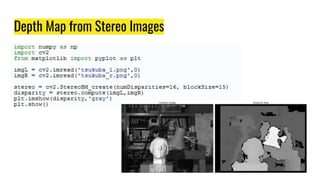
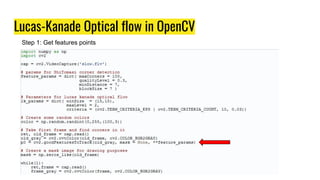
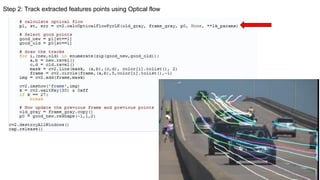
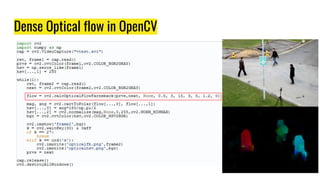
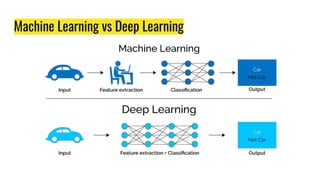
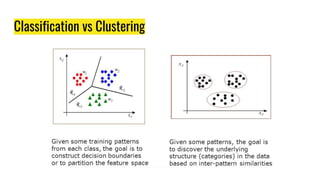
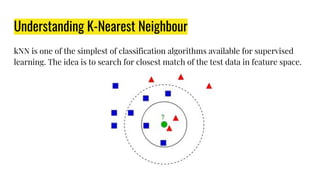
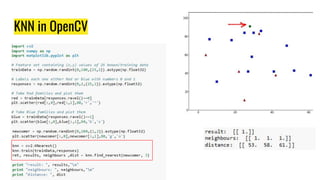
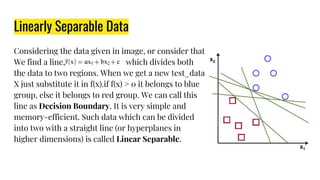
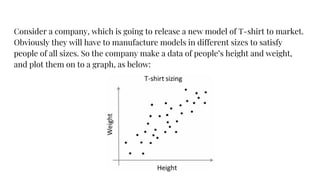
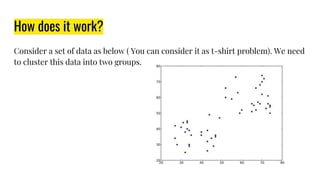
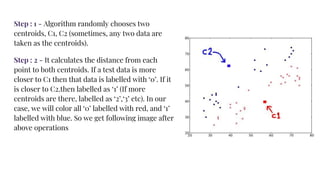
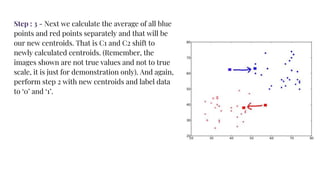
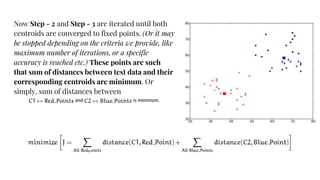
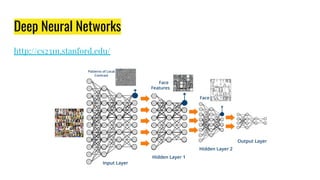
The document provides an agenda for a practical session on digital image processing. It discusses stages of computer vision including stereo images, optical flow, and machine learning techniques like classification and clustering. Stereo vision and depth maps from stereo images are explained. Optical flow concepts like the Lucas-Kanade method are covered. Machine learning algorithms like KNN, SVM, and K-means clustering are also summarized. The document concludes with information about a project, assignment, and notable AI companies in Egypt.