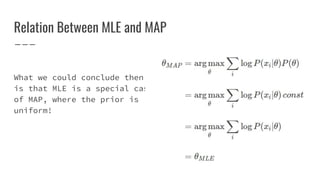
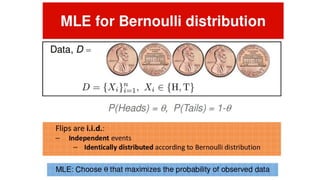
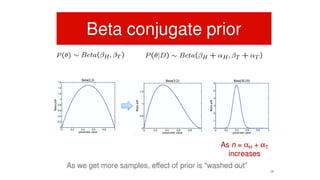
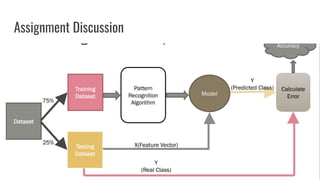
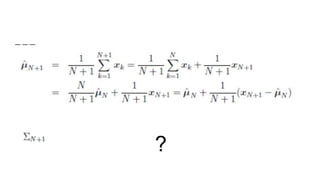This document provides an overview of pattern recognition techniques including Bayesian decision classifiers, Bayes rule, and methods for estimating parameters like maximum likelihood estimation (MLE) and maximum a posteriori estimation (MAP). It discusses how MLE estimates parameters as fixed values by maximizing the likelihood function, while MAP includes a prior distribution and maximizes the posterior. MAP is a generalization of MLE, reducing to MLE when the prior is uniform. The document also lists problems and experiments but does not provide details.