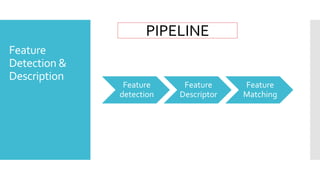
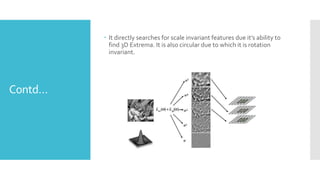
The document discusses image processing techniques, focusing on feature detection, description, and matching. It elaborates on various methods such as global vs. local feature representation, Harris corner detection, SIFT, SURF, and LBP, each with its own mechanism for identifying and describing image features. Additionally, it covers feature matching strategies including brute-force and FLANN-based methods to establish correspondences between image features.

































































![Computer Vision - Unit-II [Repaired].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computervision-unit-iirepaired-251223052721-8dd262a0-thumbnail.jpg?width=640&height=640&fit=bounds)









![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











