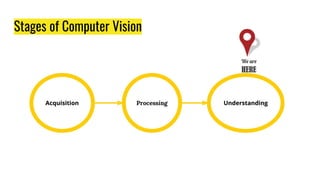
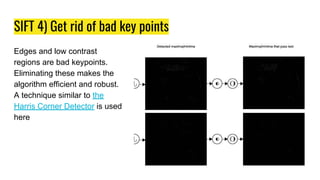
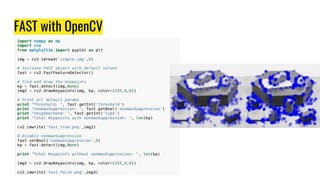
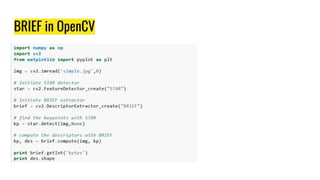
This document provides an overview of digital image processing techniques including feature detection, description, and matching. It discusses Harris corner detection, SIFT, SURF, FAST, BRIEF, and ORB feature detectors. It also covers brute force and FLANN-based feature matching as well as using feature matching and homography to find objects between images. Finally, it outlines an assignment on panorama stitching or bag-of-features image classification and a course project deadline.






































































































































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)










