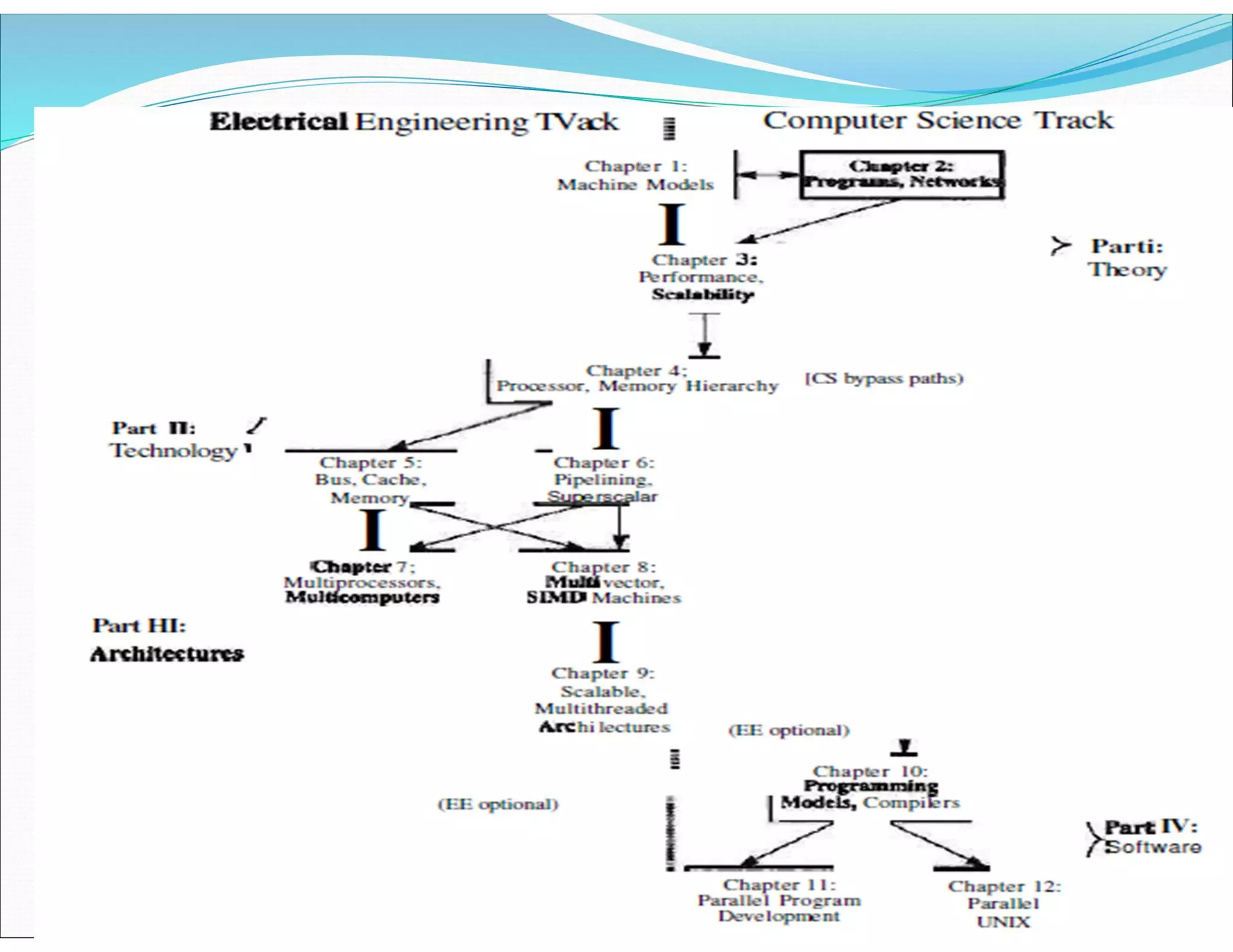
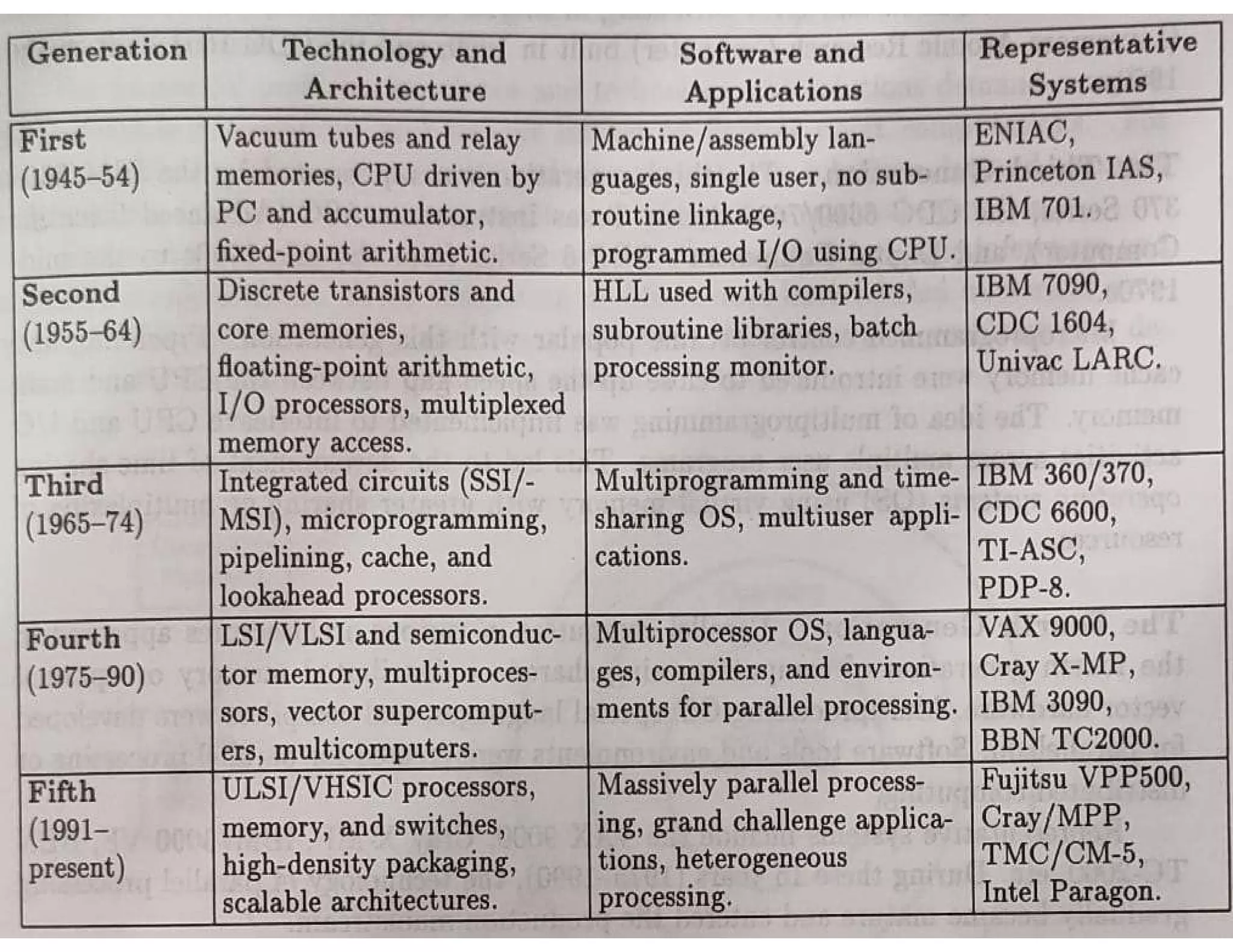
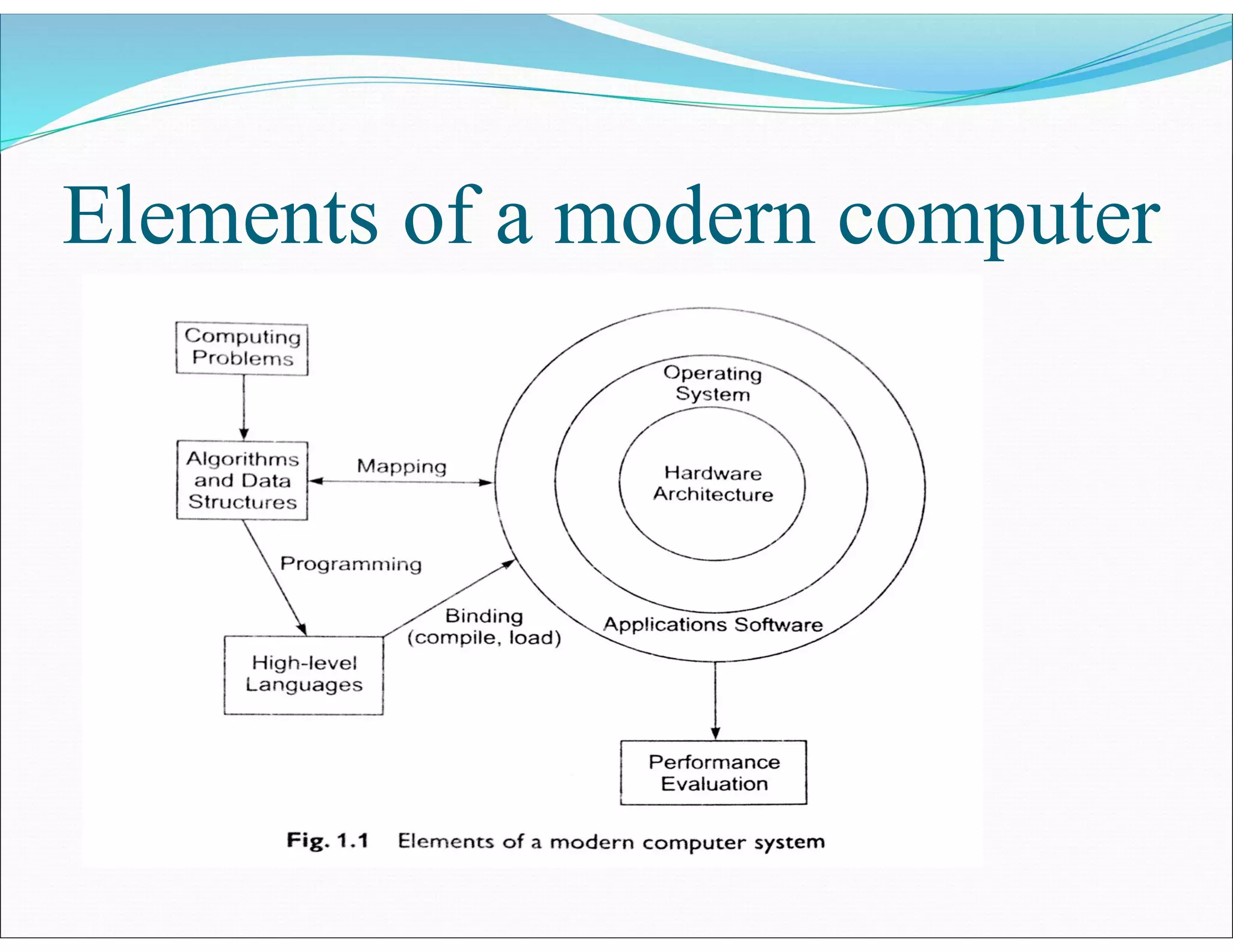
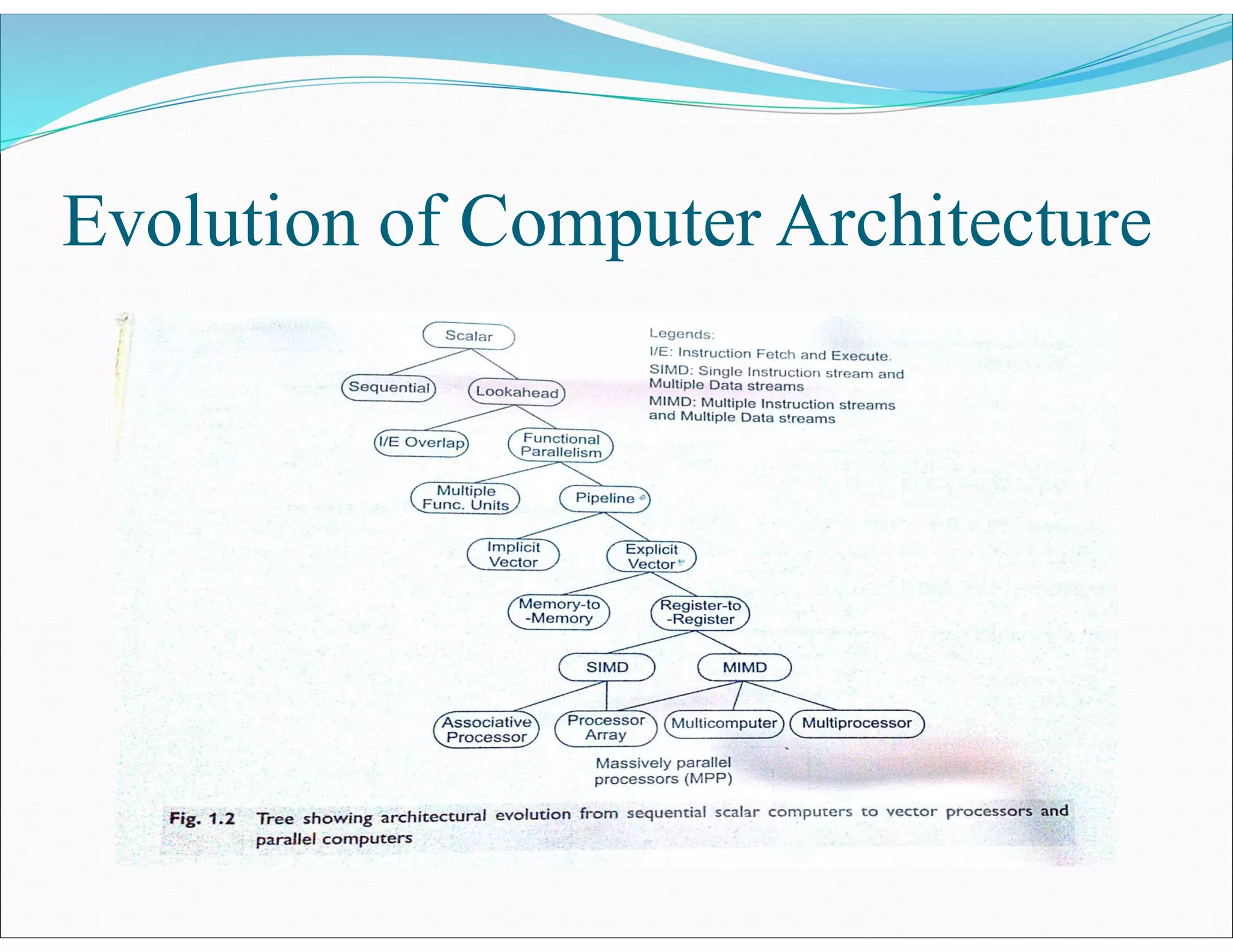
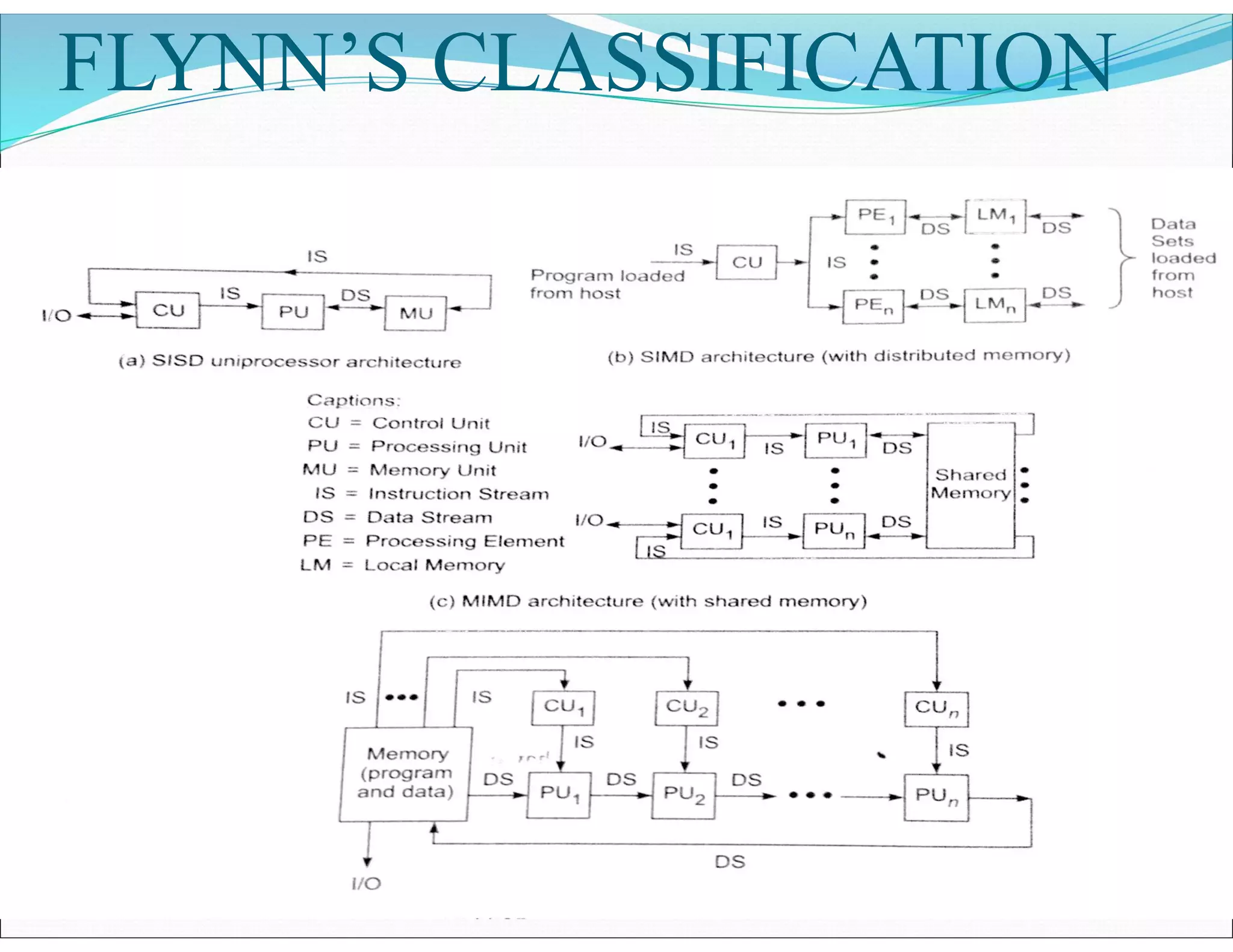
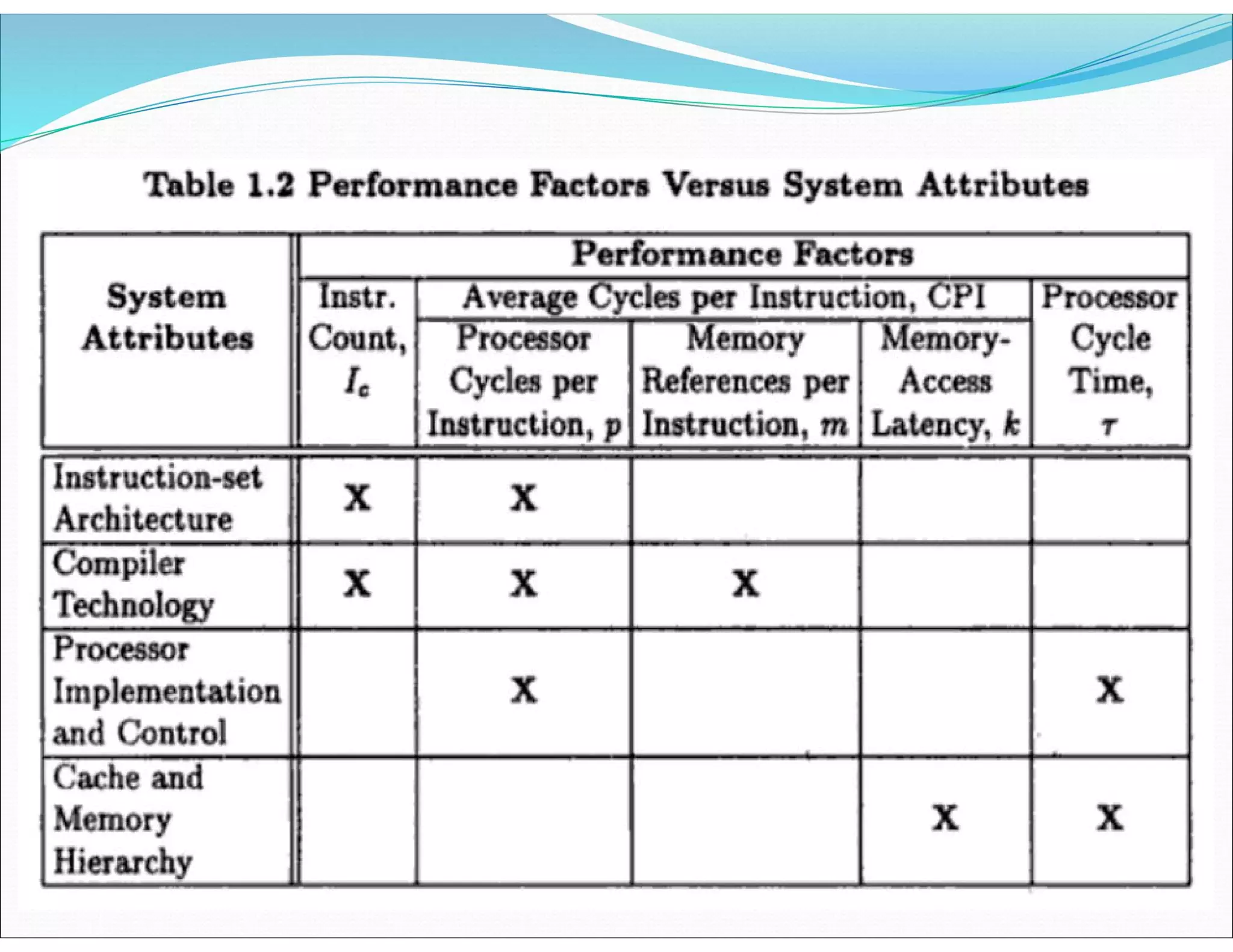
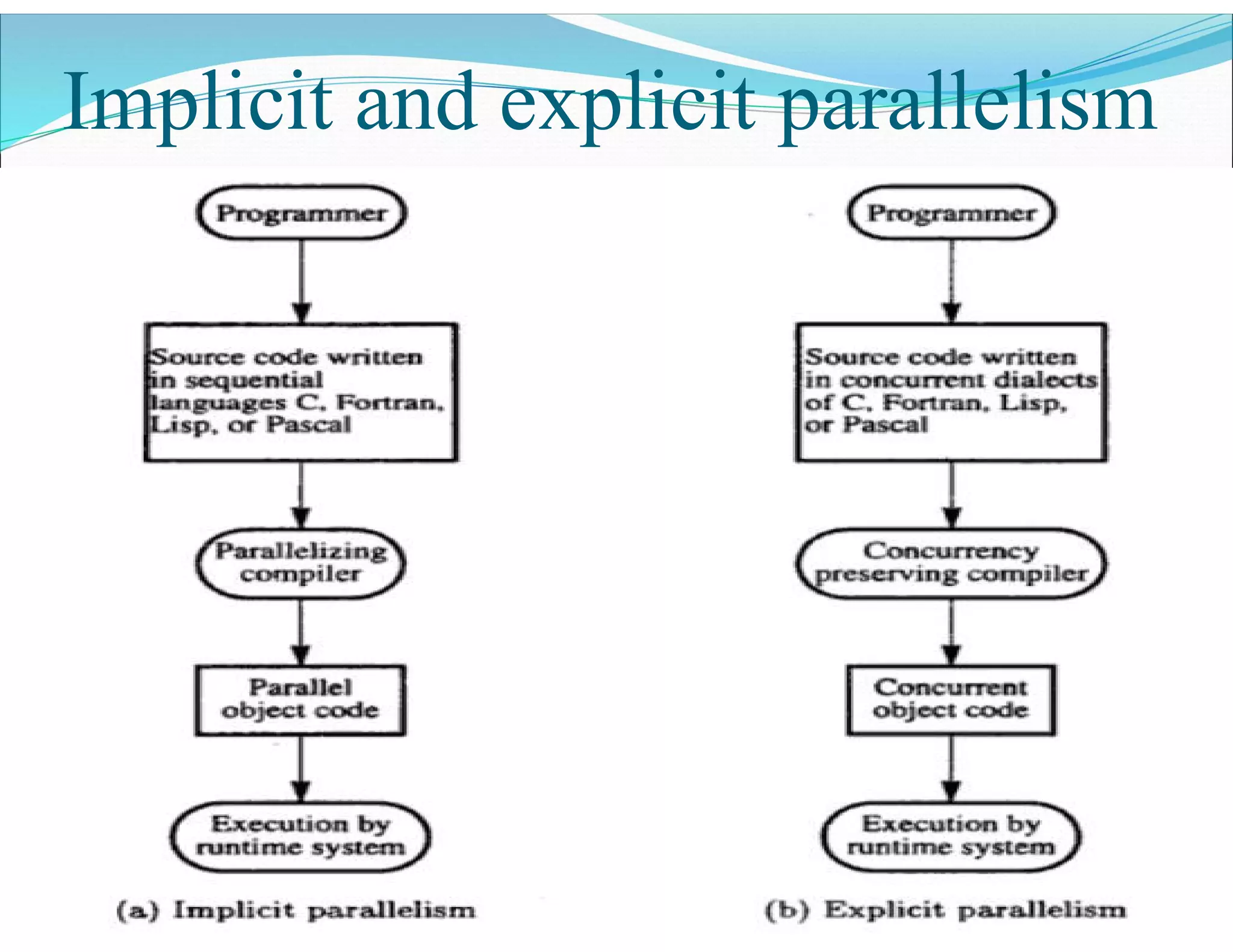
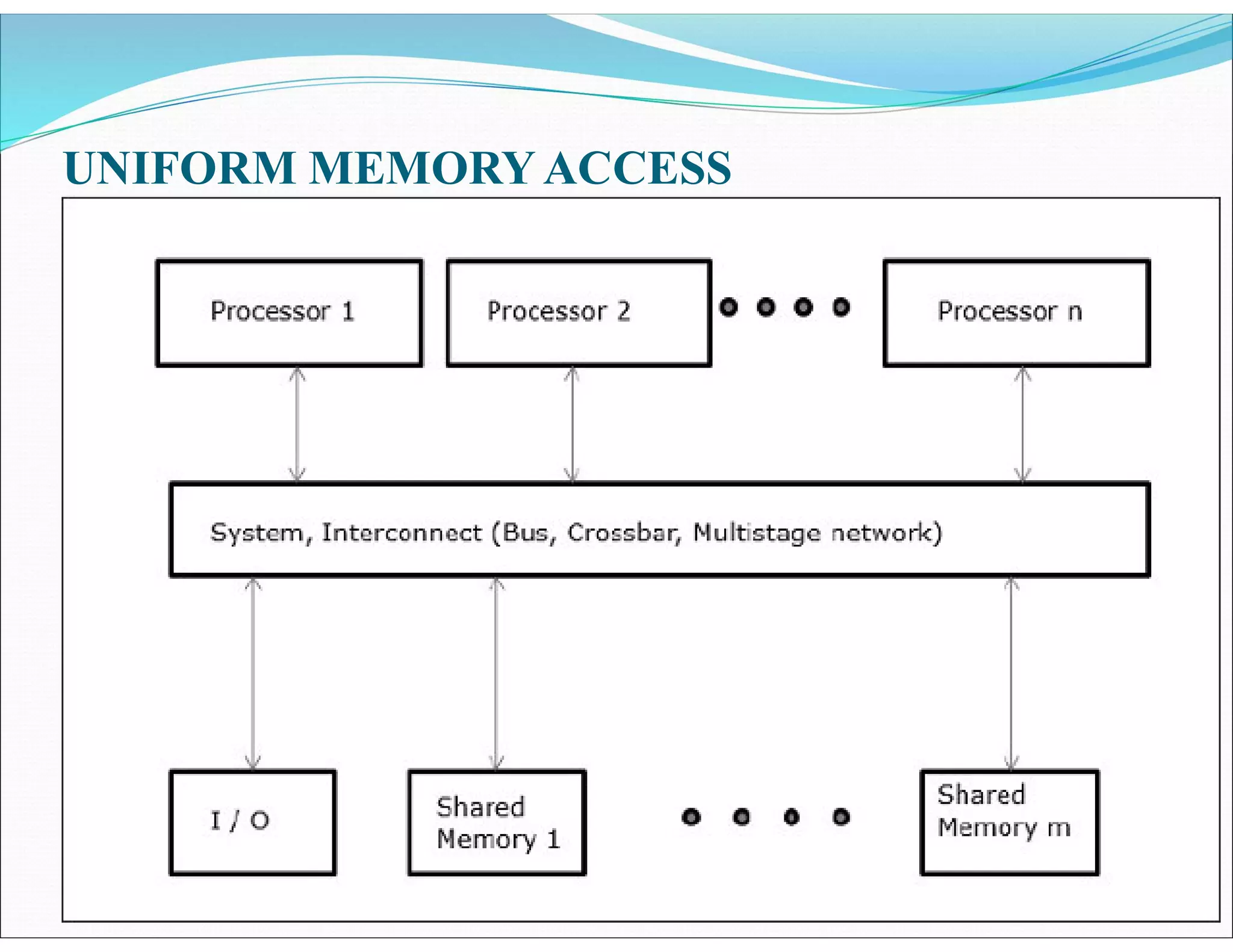
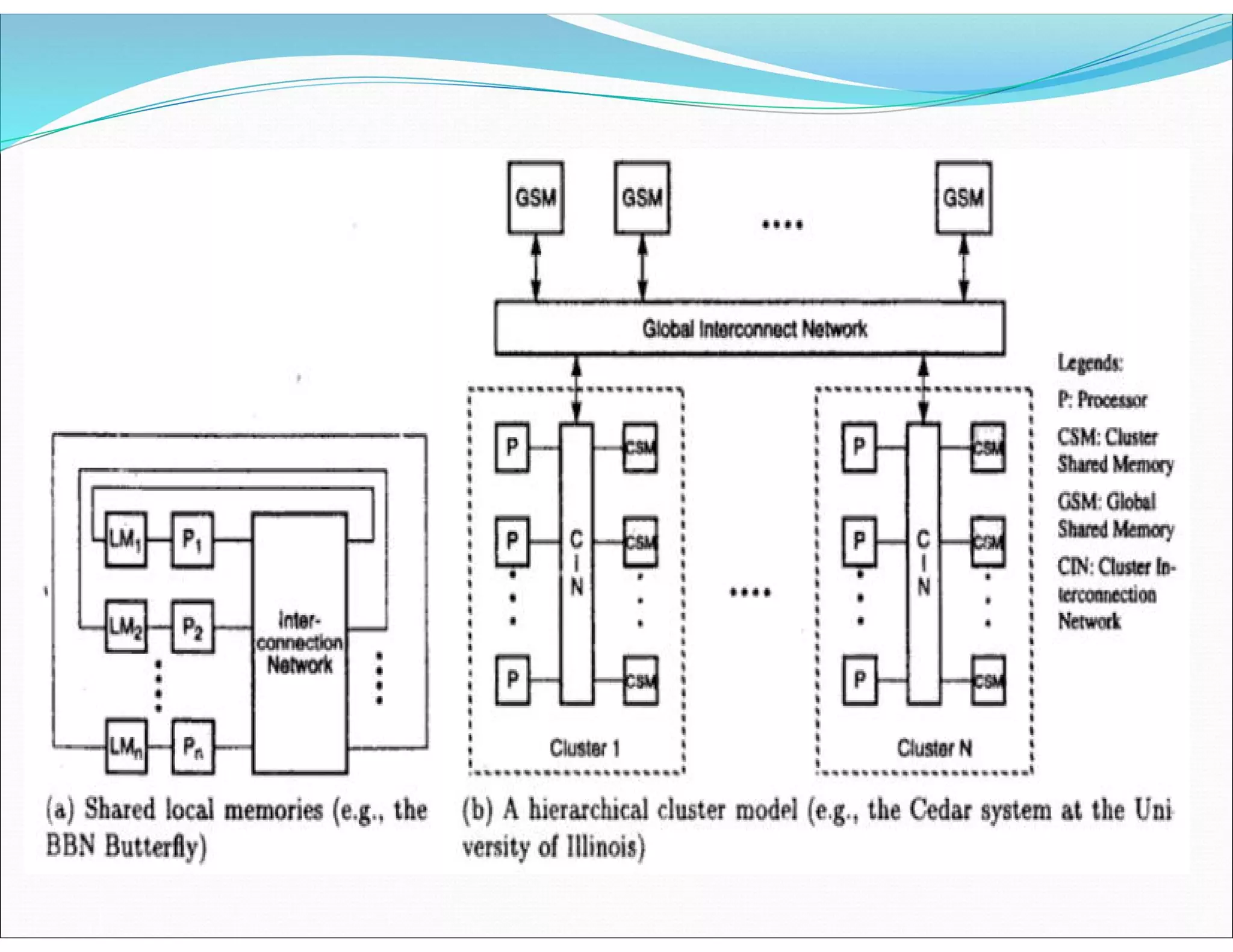
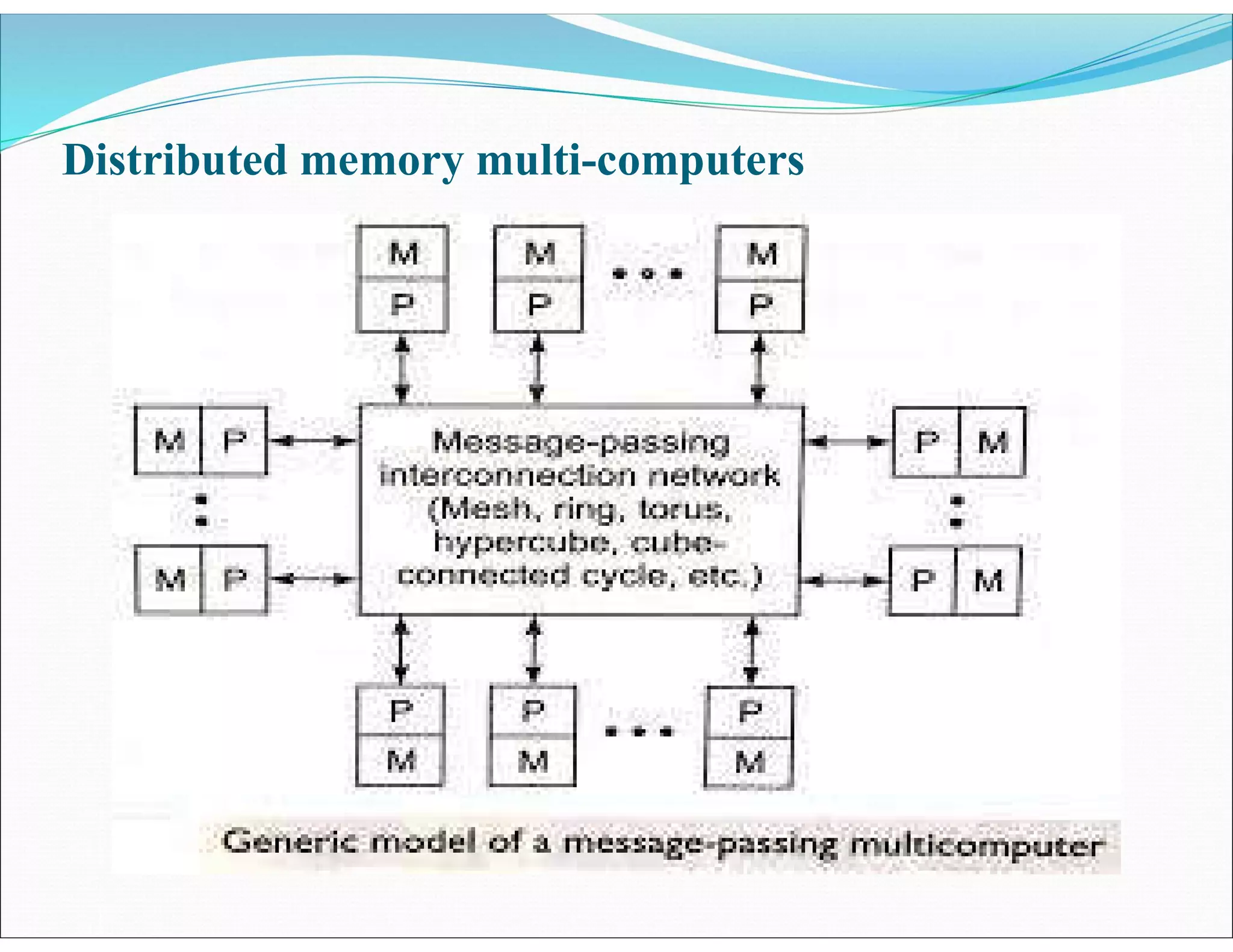
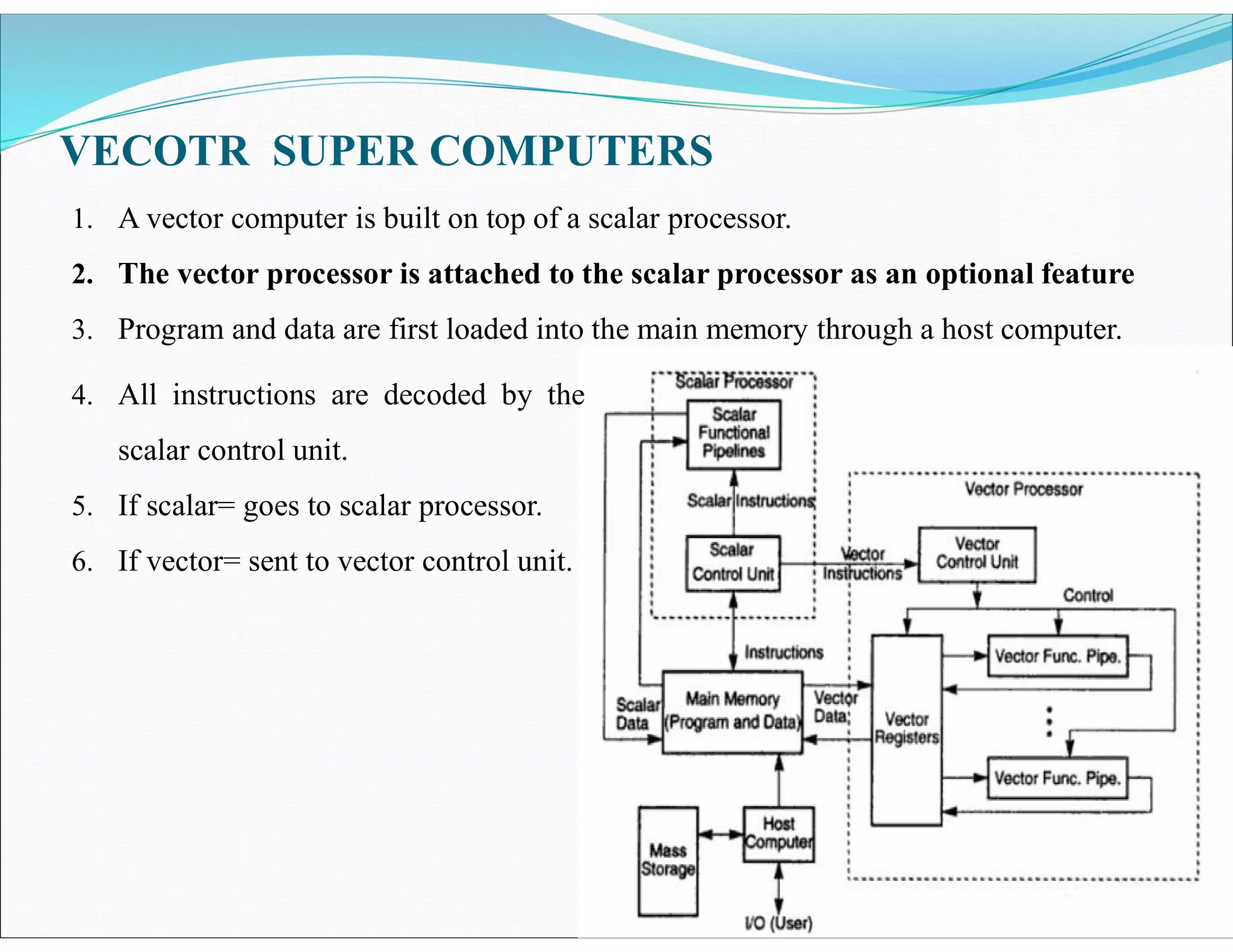
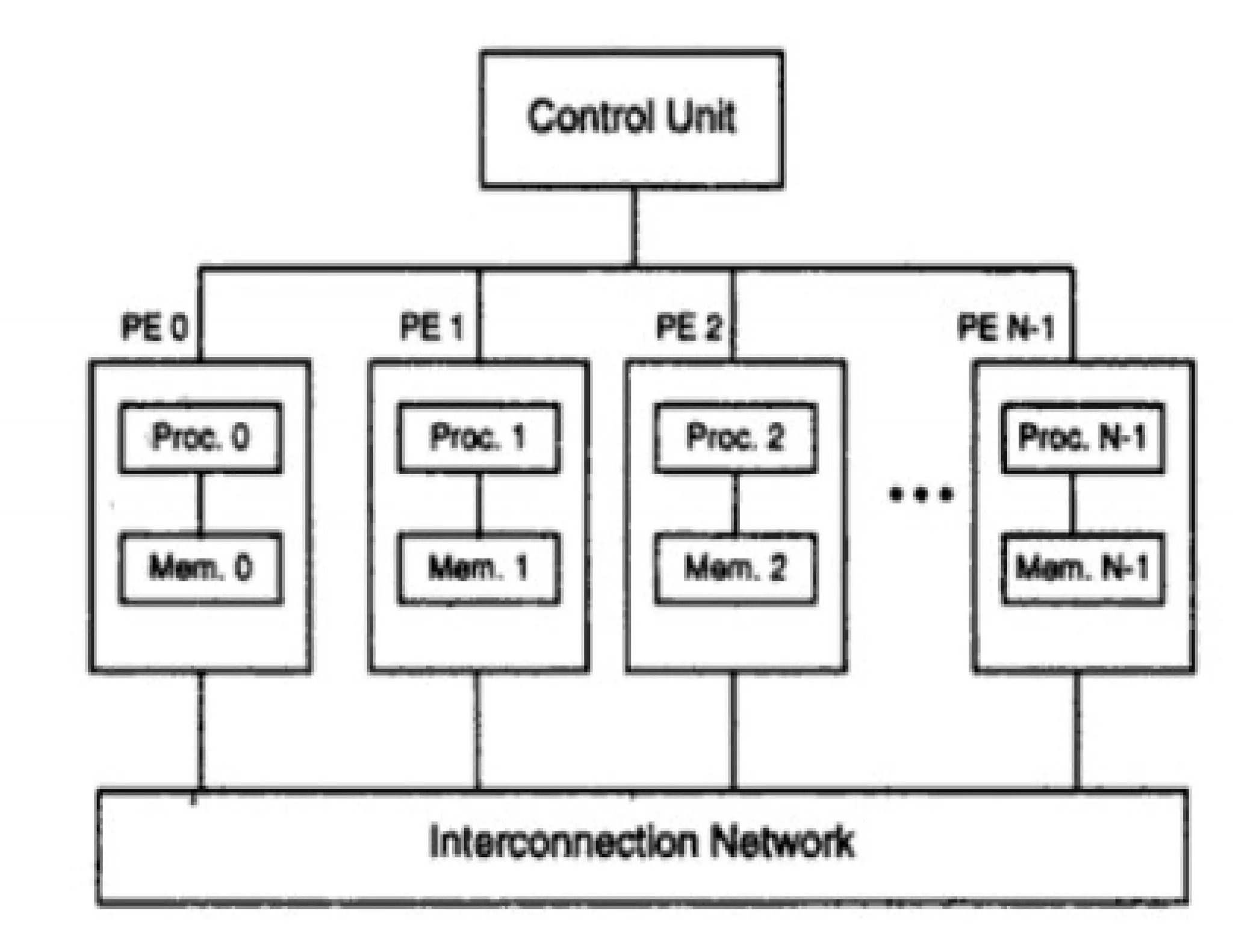
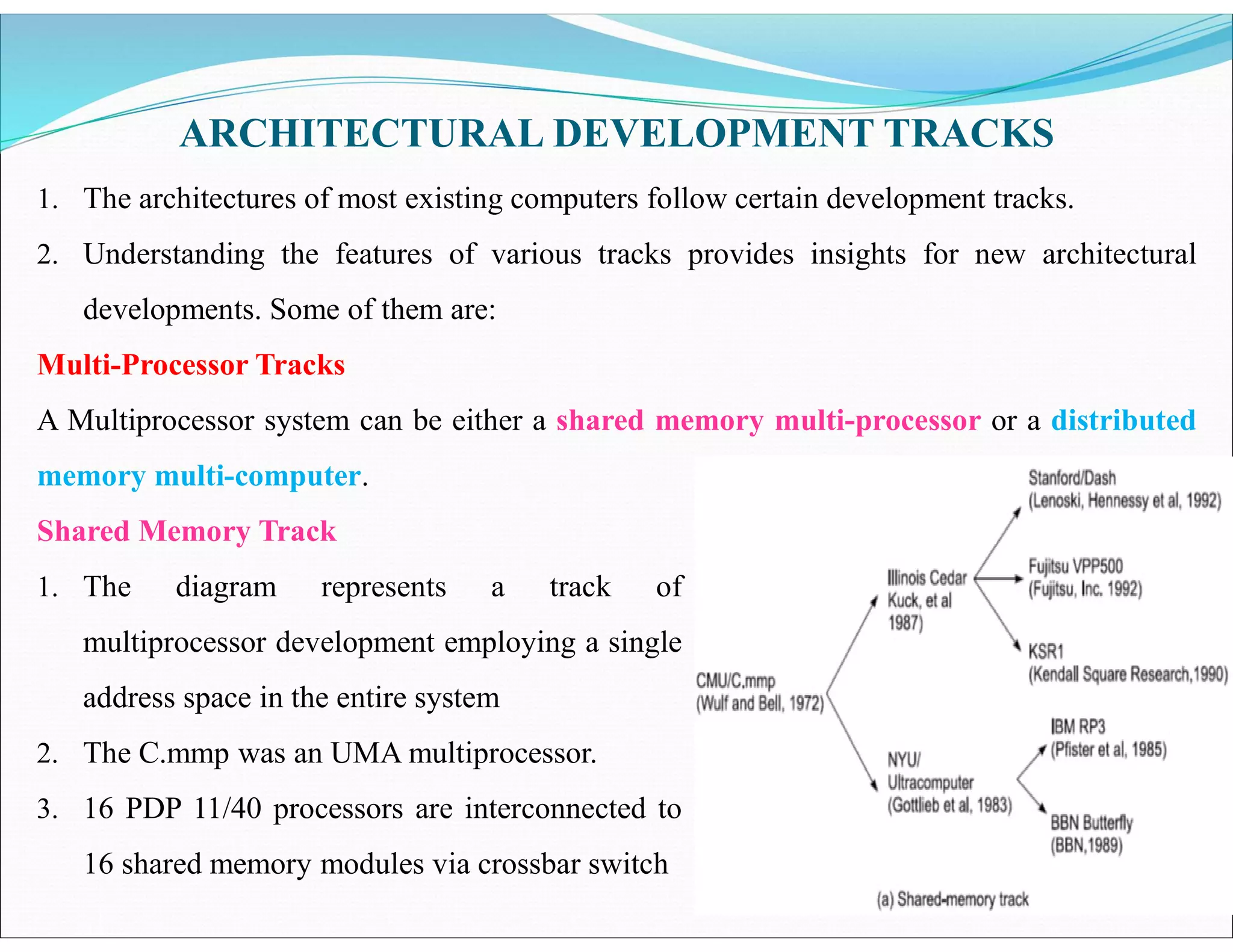
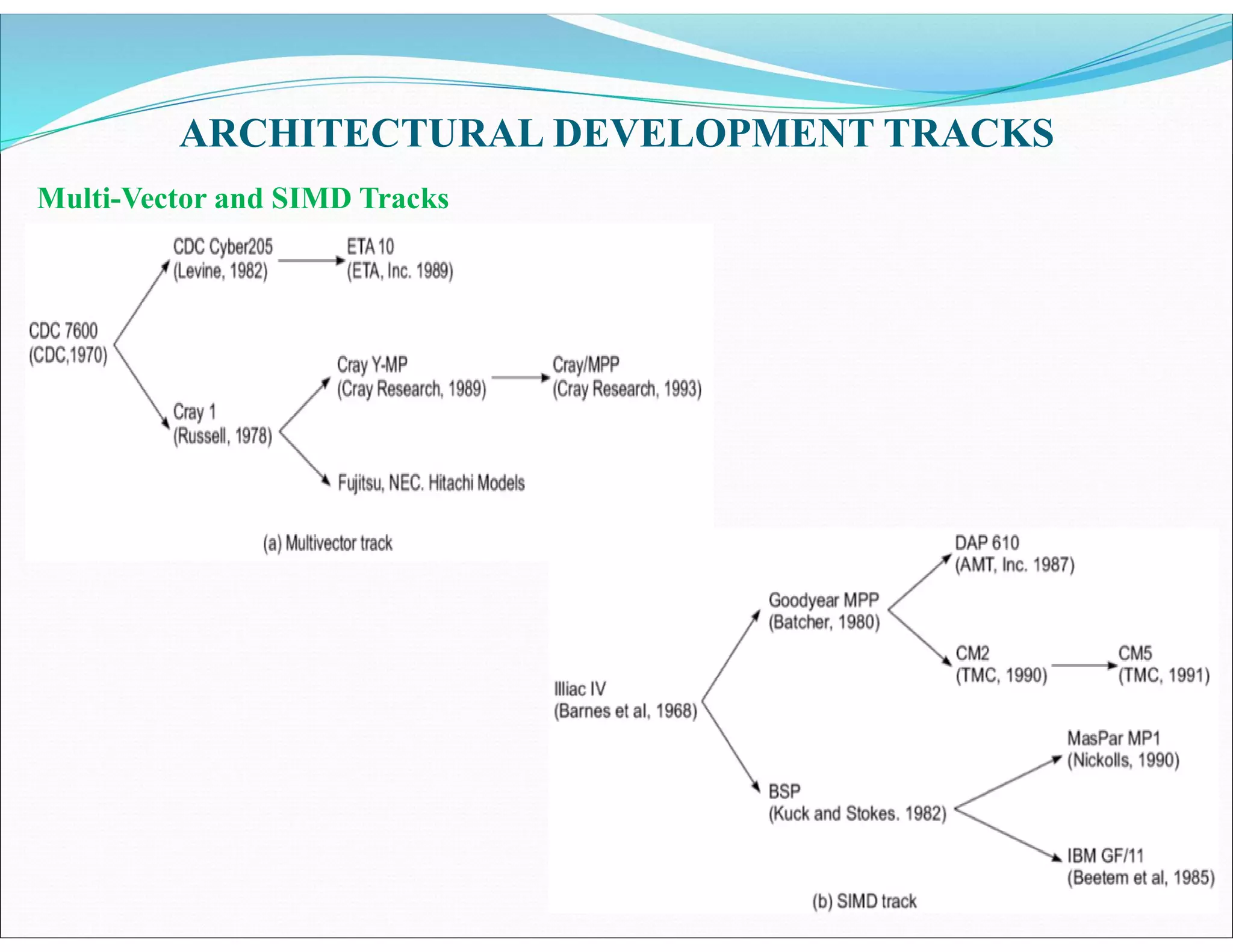
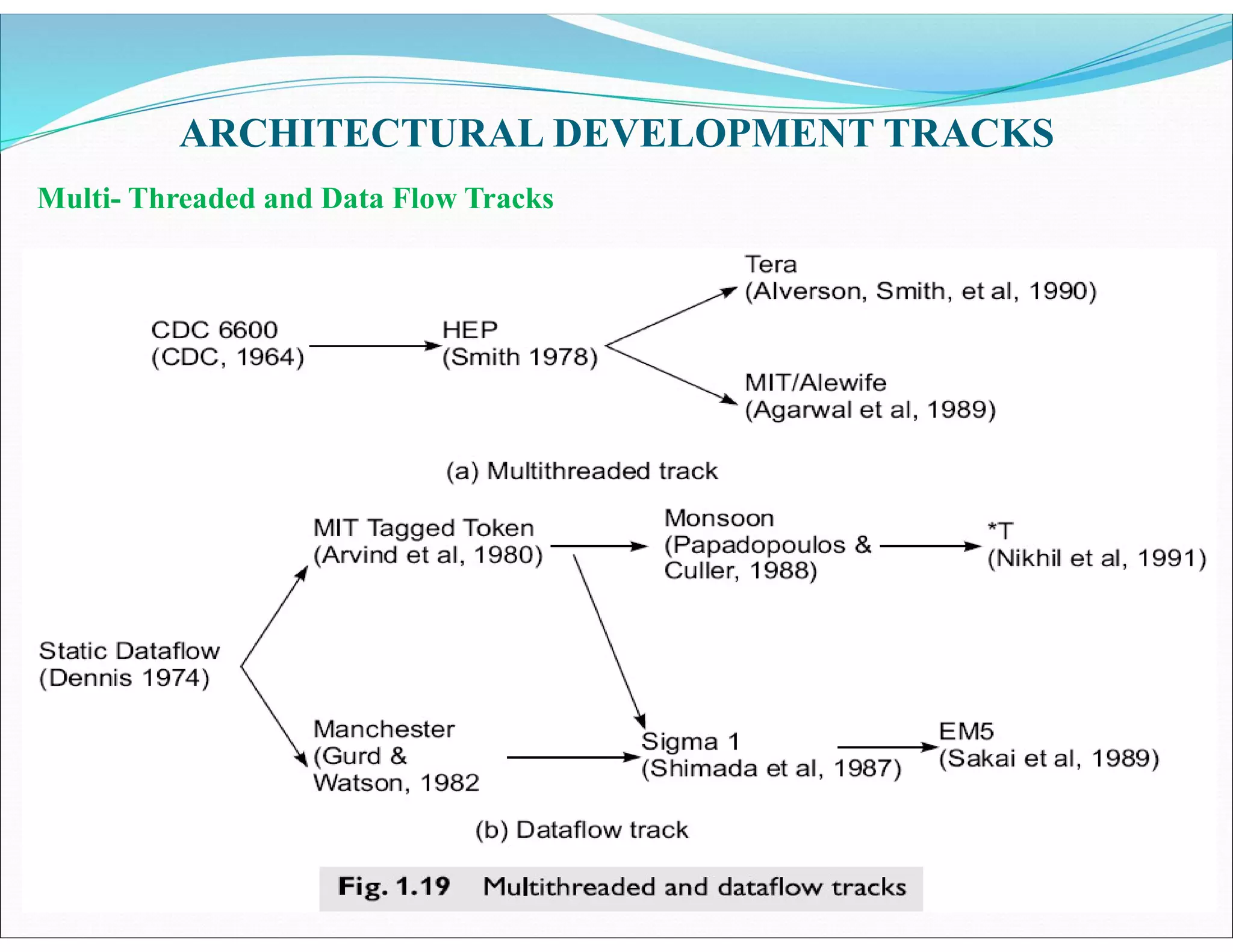
The document outlines essential elements of modern computer architecture, including computing problems, algorithms, hardware resources, and operating systems. It discusses the evolution of computer architecture, performance factors affecting system attributes, and classifications of parallel computing systems. Key concepts such as multi-processors, memory architecture models, PRAM models, and VLSI complexity are also reviewed.