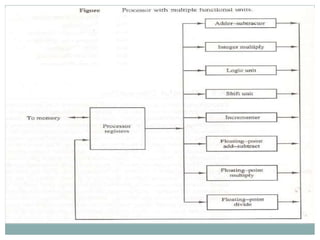
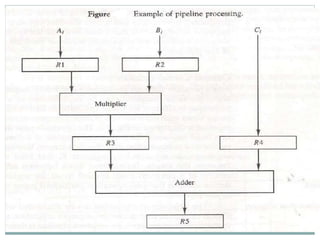
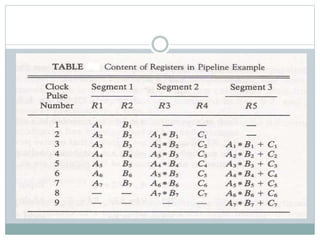
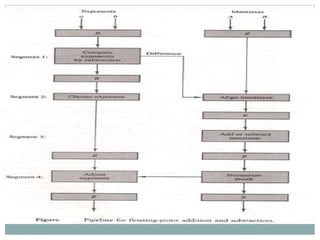
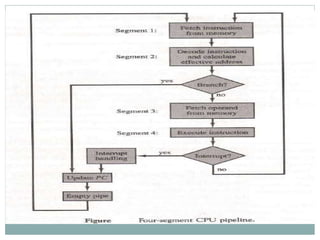
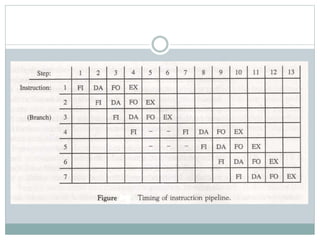
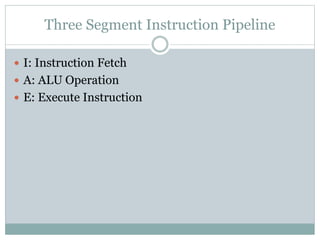
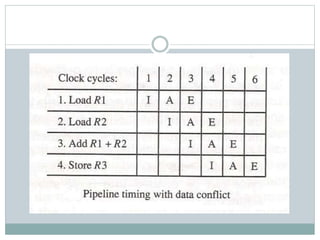
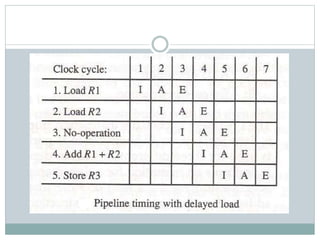
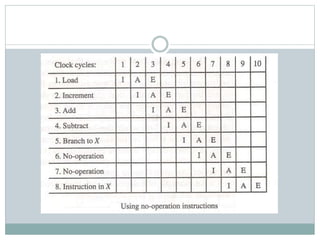
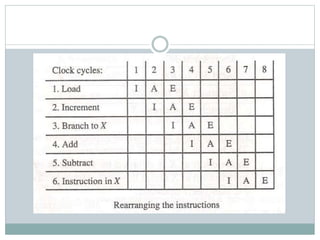
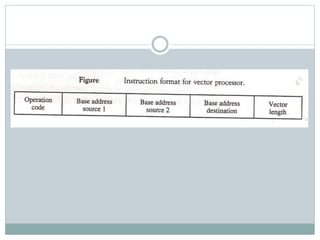
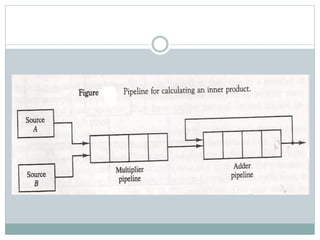
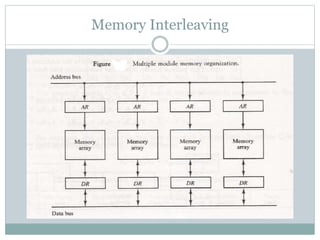
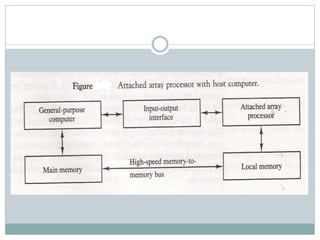
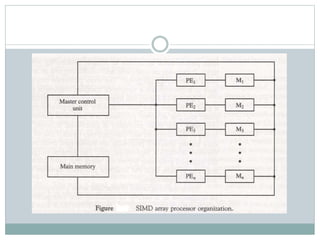
The document discusses parallel processing techniques, categorizing computers based on Flynn's classification, which includes SISD, SIMD, MISD, and MIMD structures. It explains pipelining as a method to improve instruction and data processing efficiency through simultaneous operations, and delves into instruction pipelines and vector processing for complex computations. Additionally, the document highlights array processors and their function in enhancing computer performance through parallelism.