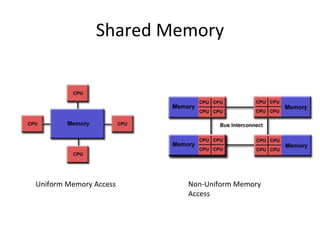
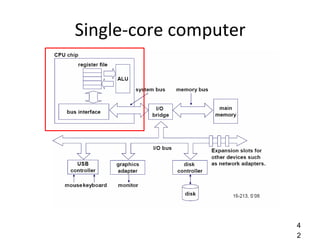
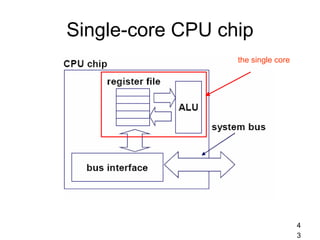
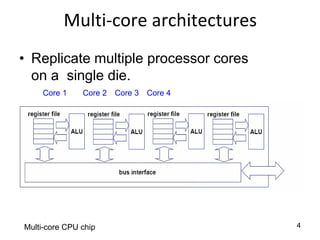
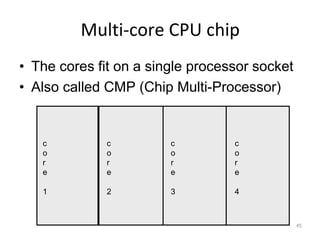
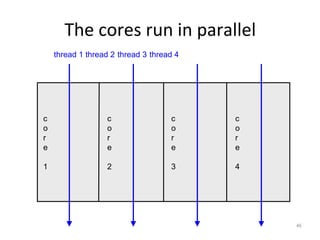
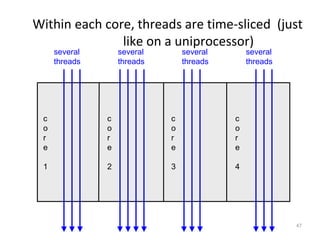
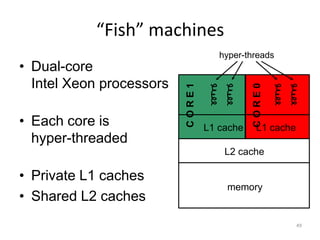
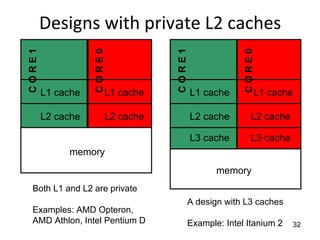
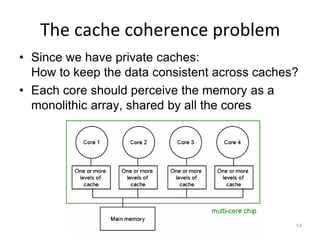
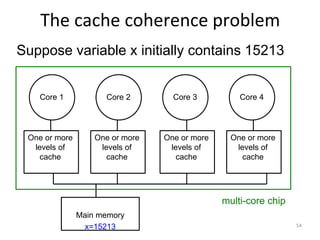
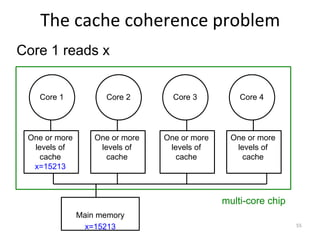
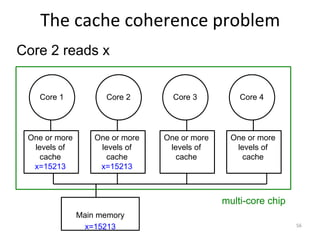
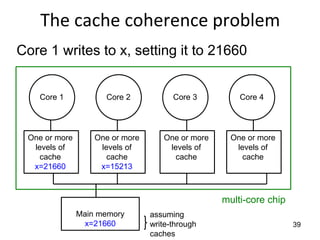
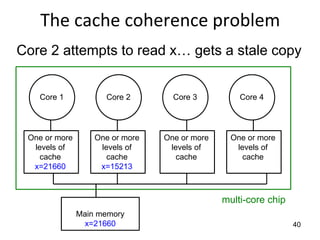
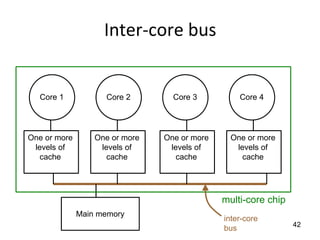
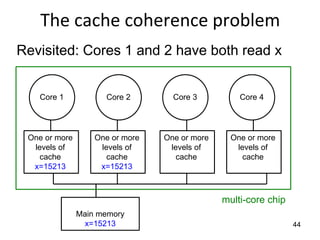
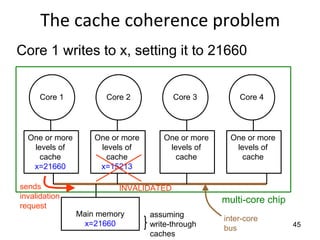
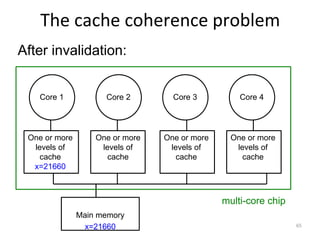
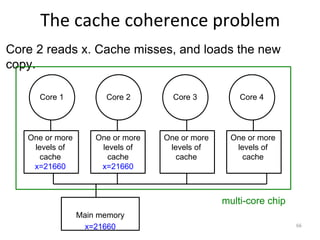
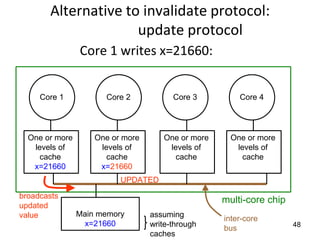
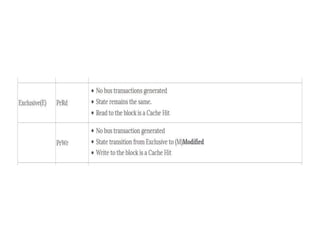
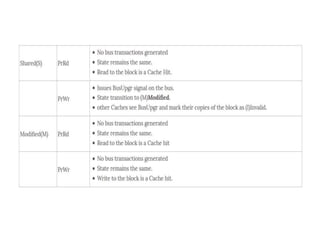
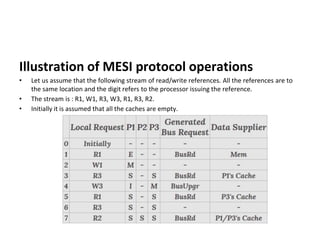
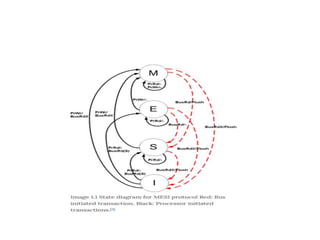
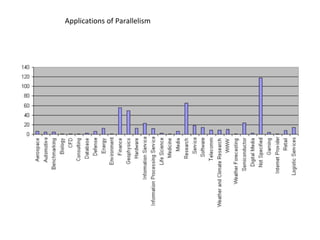
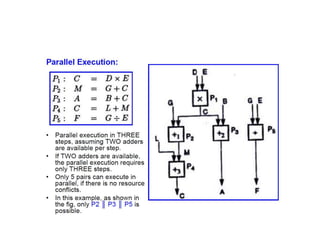
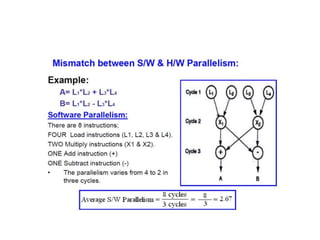
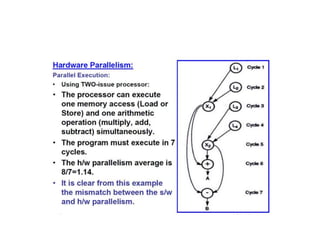
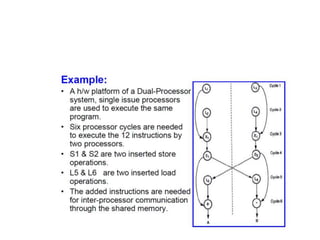
This document provides an overview of parallelism and parallel computing architectures. It discusses the need for parallelism to improve performance and throughput. The main types of parallelism covered are instruction level parallelism, data parallelism, and task parallelism. Flynn's taxonomy is introduced for classifying computer architectures based on their instruction and data streams. Common parallel architectures like SISD, SIMD, MIMD are explained. The document also covers memory architectures for multi-processor systems including shared memory, distributed memory, and cache coherency protocols.








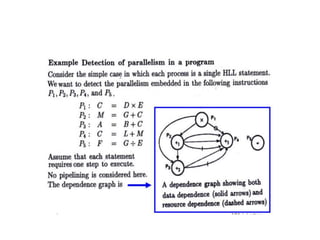
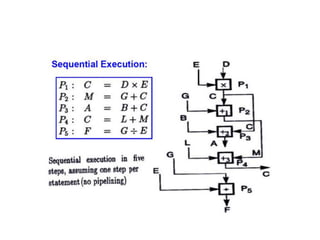






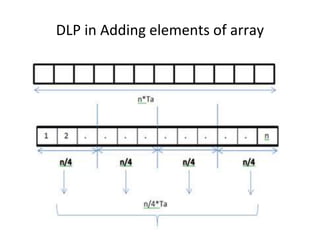
![DLP in matrix multiplication
• A[m x n] dot B [n x k] can be finished in O(n) instead of
O(m∗n∗k ) when executed in parallel using m*k processors.](https://image.slidesharecdn.com/unit4-221114180624-f496cf09/85/unit-4-pptx-23-320.jpg)