Download to read offline

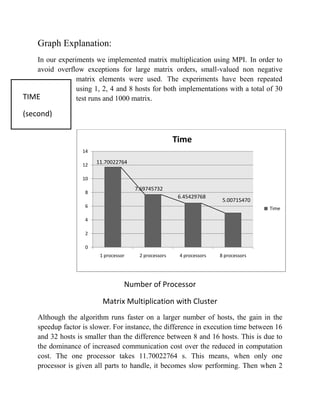


This document discusses four implementations of parallel matrix multiplication on a cluster. It proposes a master-worker model using dynamic block distribution and MPI. Experiments were conducted on a cluster using matrices of size n×n. The performance of the implementations was analyzed and an analytical model was developed that can accurately predict parallel performance. The model considers the matrix multiplication C=A×B with matrices of size n×n on a cluster with p workstations. Experiments showed that increasing the number of nodes from 1 to 8 decreased completion time but with diminishing returns due to communication overhead.
































































































