Download as PDF, PPTX


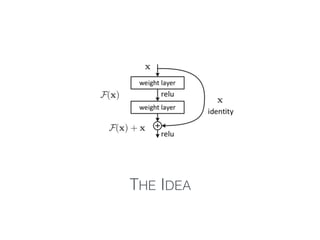

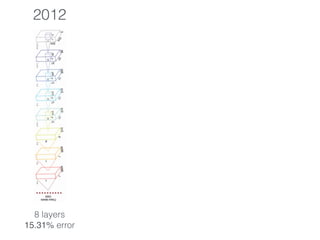

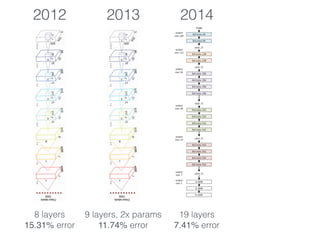
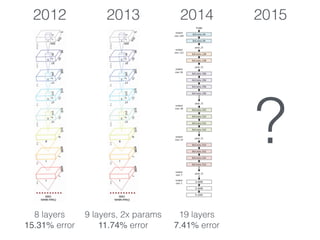
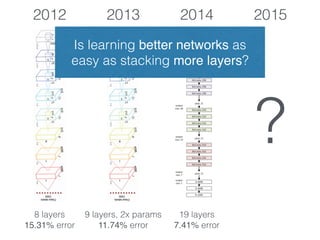
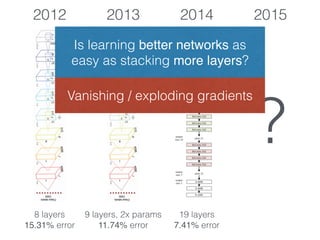
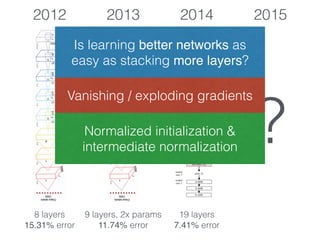
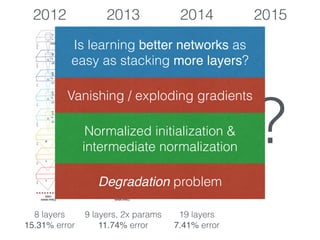

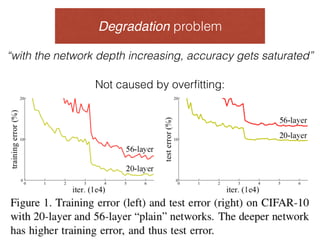
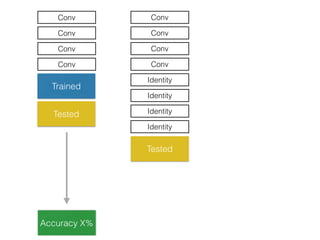
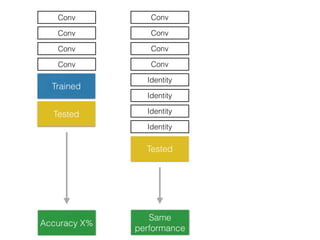
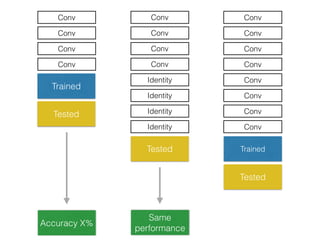
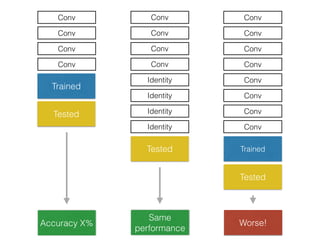
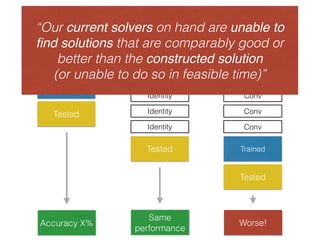
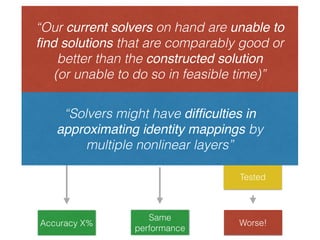

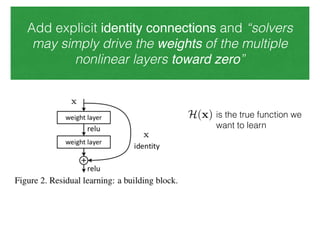
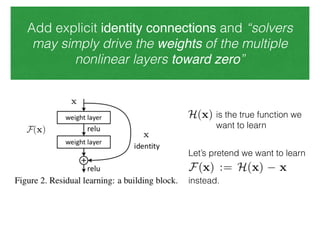
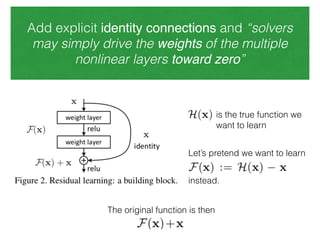
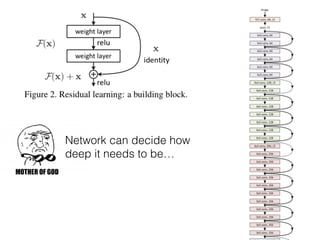
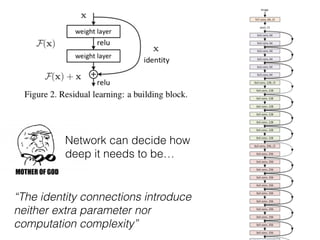
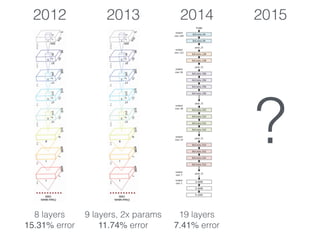





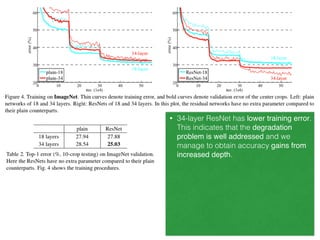
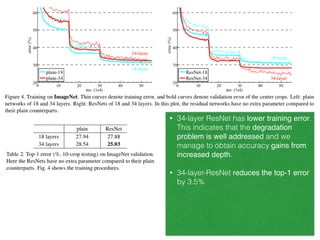
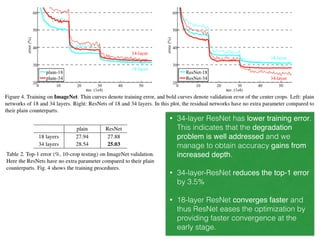

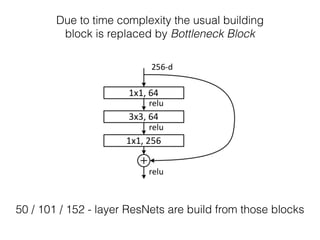
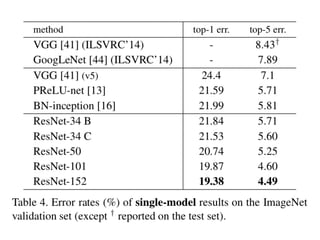
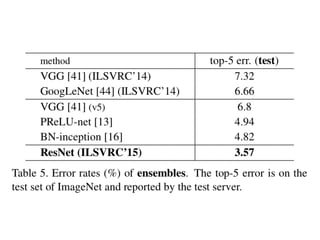


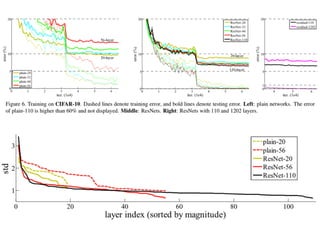
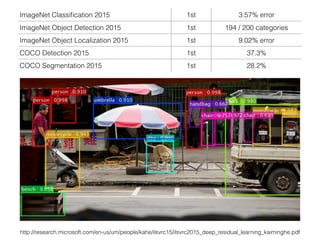

The document discusses deep residual learning for image recognition, detailing the evolution of neural network architectures and their performance on various benchmarks such as ILSVRC and MS COCO. It emphasizes the challenges of vanishing gradients and degradation problems with increased depth, proposing identity connections to mitigate these issues. The findings indicate that ResNet architectures, particularly deeper variants, can achieve lower error rates and improved training accuracy by addressing the degradation problem effectively.






















![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Learning What and Where to Draw (NIPS’16)](https://cdn.slidesharecdn.com/ss_thumbnails/20170120misono-170215035536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]bridging the gaps between residual learning, recurrent neural networks...](https://cdn.slidesharecdn.com/ss_thumbnails/dlbridgingthegapsbetweenresiduallearningrecurrentneuralnetworksandvisualcortex-160809011746-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20160113-170222033302-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]bayesian dark knowledge](https://cdn.slidesharecdn.com/ss_thumbnails/dlbayesiandarkknowledge-160819032303-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170303-170308031242-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Regularization with stochastic transformations and perturbations for d...](https://cdn.slidesharecdn.com/ss_thumbnails/regularizationwithstochastictransformationsandperturbationsfordeepsemi-supervisedlearning-170215034444-thumbnail.jpg?width=640&height=640&fit=bounds)
























































