Download to read offline































![• To monitor the time-series continuously and alert for potential incidents on time
• The algorithm first computes the Fourier Transform of the original data. Then it computes
the spectral residual of the log amplitude of the transformed signal before applying the Inverse
Fourier Transform to map the sequence back from the frequency to the time domain. This
sequence is called the saliency map. The anomaly score is then computed as the relative
difference between the saliency map values and their moving averages. If the score is above a
threshold, the value at a specific timestep is flagged as an outlier.
• There are several parameters for SR algorithm. To obtain a model with good performance, we
suggest to tune windowSize and threshold at first, these are the most important parameters to
SR. Then you could search for an appropriate judgementWindowSize which is no larger than
windowSize. And for the remaining parameters, you could use the default value directly.
• Time-Series Anomaly Detection Service at Microsoft [https://arxiv.org/pdf/1906.03821.pdf]
Spectrum Residual Cnn (SrCnn)](https://image.slidesharecdn.com/2021-211103222116/85/Anomaly-Detection-with-Azure-and-net-37-320.jpg)






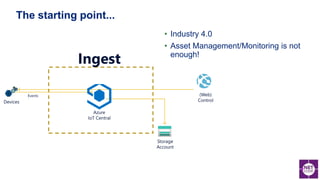
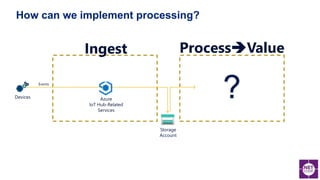
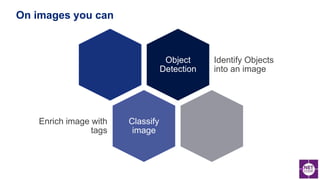
The document discusses various aspects of anomaly detection in data, particularly in the context of time series and image classification using machine learning techniques. It reviews prevalent models and frameworks, including deep learning architectures and custom solutions for computer vision, and emphasizes the importance of integrating machine learning into .NET applications. Additionally, it highlights key concepts like the statistical significance of anomalies and various algorithms for detecting outliers.























































































