Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
9,097 views
[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks
2017/2/22 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
18
Save
Share
Embed
Embed presentation
Download
Downloaded 104 times
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
敵対的生成ネットワーク(GAN)
by
cvpaper. challenge
PPTX
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
PPTX
2017:10:20論文読み会"Image-to-Image Translation with Conditional Adversarial Netwo...
by
ayaha osaki
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PDF
【論文読み会】Self-Attention Generative Adversarial Networks
by
ARISE analytics
PPTX
StyleGAN解説 CVPR2019読み会@DeNA
by
Kento Doi
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
敵対的生成ネットワーク(GAN)
by
cvpaper. challenge
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
2017:10:20論文読み会"Image-to-Image Translation with Conditional Adversarial Netwo...
by
ayaha osaki
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
【論文読み会】Self-Attention Generative Adversarial Networks
by
ARISE analytics
StyleGAN解説 CVPR2019読み会@DeNA
by
Kento Doi
What's hot
PPTX
【DL輪読会】LAR-SR: A Local Autoregressive Model for Image Super-Resolution
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PDF
CycleGANによる異種モダリティ画像生成を用いた股関節MRIの筋骨格セグメンテーション
by
奈良先端大 情報科学研究科
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...
by
Deep Learning JP
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
PDF
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
PPTX
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
ConvNetの歴史とResNet亜種、ベストプラクティス
by
Yusuke Uchida
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PDF
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
【DL輪読会】LAR-SR: A Local Autoregressive Model for Image Super-Resolution
by
Deep Learning JP
機械学習モデルの判断根拠の説明
by
Satoshi Hara
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
CycleGANによる異種モダリティ画像生成を用いた股関節MRIの筋骨格セグメンテーション
by
奈良先端大 情報科学研究科
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...
by
Deep Learning JP
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
ConvNetの歴史とResNet亜種、ベストプラクティス
by
Yusuke Uchida
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
Similar to [DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks
PPTX
[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial...
by
Deep Learning JP
PDF
Image-to-Image Translation with Conditional Adversarial Networksの紹介
by
KCS Keio Computer Society
PDF
社内論文読み会 20180316 - Unpaired Image-to-Image Translation using Cycle-Consistent...
by
Kazuhiro Ota
PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
by
harmonylab
PDF
Few-Shot Unsupervised Image-to-Image Translation
by
Kento Doi
PDF
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
PPTX
Unsupervised image to-image translation networks
by
Yamato OKAMOTO
PDF
文献紹介:Toward Multimodal Image-to-Image Translation
by
Toru Tamaki
PDF
[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)
by
Deep Learning JP
PPTX
[DL輪読会]Unsupervised Cross-Domain Image Generation
by
Deep Learning JP
PDF
20180622 munit multimodal unsupervised image-to-image translation
by
h m
PDF
論文輪読: Generative Adversarial Text to Image Synthesis
by
mmisono
PDF
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
PDF
CycleGANについて
by
yohei okawa
PPTX
Unsupervised Image-to-Image Translation Networksの紹介
by
KCS Keio Computer Society
PDF
[IBIS2017 講演] ディープラーニングによる画像変換
by
Satoshi Iizuka
PPTX
Bridging between Vision and Language
by
Shion Honda
PDF
4. CycleGANの画像変換と現代美術への応用
by
幸太朗 岩澤
PPTX
[DL輪読会]Freehand-Sketch to Image Synthesis 2018
by
Deep Learning JP
PDF
論文紹介:Panoptic-aware Image-to-Image Translation
by
Toru Tamaki
[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial...
by
Deep Learning JP
Image-to-Image Translation with Conditional Adversarial Networksの紹介
by
KCS Keio Computer Society
社内論文読み会 20180316 - Unpaired Image-to-Image Translation using Cycle-Consistent...
by
Kazuhiro Ota
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network
by
harmonylab
Few-Shot Unsupervised Image-to-Image Translation
by
Kento Doi
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
Unsupervised image to-image translation networks
by
Yamato OKAMOTO
文献紹介:Toward Multimodal Image-to-Image Translation
by
Toru Tamaki
[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)
by
Deep Learning JP
[DL輪読会]Unsupervised Cross-Domain Image Generation
by
Deep Learning JP
20180622 munit multimodal unsupervised image-to-image translation
by
h m
論文輪読: Generative Adversarial Text to Image Synthesis
by
mmisono
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
CycleGANについて
by
yohei okawa
Unsupervised Image-to-Image Translation Networksの紹介
by
KCS Keio Computer Society
[IBIS2017 講演] ディープラーニングによる画像変換
by
Satoshi Iizuka
Bridging between Vision and Language
by
Shion Honda
4. CycleGANの画像変換と現代美術への応用
by
幸太朗 岩澤
[DL輪読会]Freehand-Sketch to Image Synthesis 2018
by
Deep Learning JP
論文紹介:Panoptic-aware Image-to-Image Translation
by
Toru Tamaki
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
Recently uploaded
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks
1.
Image-to-Image Translation with Conditional Adversarial NetworksPhillip
Isola Jun-Yan Zhu Tinghui Zhou Alexei A. Efros Berkeley AI Research (BAIR) Laboratory University of California, Berkeley 2017/1/13 河野 慎
2.
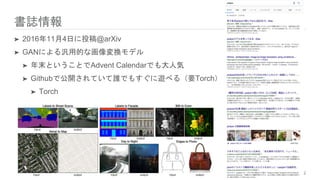
書誌情報 ➤ 2016年11月4日に投稿@arXiv ➤ GANによる汎用的な画像変換モデル ➤
年末ということでAdvent Calendarでも大人気 ➤ Githubで公開されていて誰でもすぐに遊べる(要Torch) ➤ Torch 2
3.
INTRODUCTION ➤ 言語の翻訳と同様に画像の”翻訳”をしたい ➤ 言語は一対一対応した写像とは限らないため難しい ➤
画像にも同様なタスクが多数存在する ➤ many-to-one (Computer Vision) ➤ 写真から輪郭,セグメント,セマンティックラベルへ写像 ➤ one-to-many(Computer Graphics) ➤ ラベルやユーザのスパースな入力から本物のような画像へ写像 ➤ いずれもタスクも”ピクセルからピクセルを予測する”点で共通 ➤ これらの問題を扱えるフレームワークを提案することが目標 3
4.
INTRODUCTION ➤ 画像予測タスクでは,CNNがたくさん使われてきた ➤ 学習プロセス自体は自動であるものの,効果的な損失関数を設計する必要がある ➤
うまく設計しないとダメ ➤ 例:ユークリッド距離→ぼやけた画像を生成しがち ➤ 平均的な数値を出そうとするためにぼやける(強弱があまりない) ➤ 一方,GANが最近うまくいってる ➤ ぼやけた画像は”本物”に似てないため,生成されにくい ➤ データに適用した損失を学習することが可能 ➤ 従来様々な損失関数を必要としたタスクに適用することが可能と言える 4
5.
RELATED WORK ➤ 構造に関する損失関数 ➤
画像変換はピクセルごとの分類もしくは回帰問題と言える ➤ 入力画像が与えられた時に出力されるピクセルは独立と仮定される ”非構造な”出力空間として扱ってしまう ➤ 一方で条件付きGANなら,構造に関する損失関数を学習する ➤ 様々な既存手法も提案されてきた ➤ 確率場やSSIM(Structual Similarity),特徴マッチング,ノンパラ損失関数, 畳み込み擬似事前分布?,共分散を用いた損失関数 ➤ 提案する条件付きGANは上のいかなる構造も学習することができる 5
6.
RELATED WORK ➤ 条件付きGAN ➤
既存研究では,様々な条件付けが行われてきた ➤ 離散ラベル,文章,画像 ➤ 画像による条件付きGAN ➤ 画像修復,地図から画像予測,ユーザによる画像操作,将来のフレーム予測,将 来の状態予測,写真生成,画風変換 ➤ いずれも特定のタスクに特化したものであり,自分たちのは汎用的で, 設定も簡単である ➤ また,構造もGに”U-NET”,Dに”PatchGAN”を適用しているため新しい 6
7.
提案モデル(PIX2PIX) ➤ 条件付きGAN(DiscriminatorとGeneratorの両方に条件付ける) ➤ Gにおいて, ➤
zがない場合:デルタ関数しか表現できない(決定論的) ➤ zがある場合:先行研究では,入力に用いている ➤ 実験で,有効性を見いだすことができなかった ➤ Dropoutを中間層に入れて,ノイズzとする 7
8.
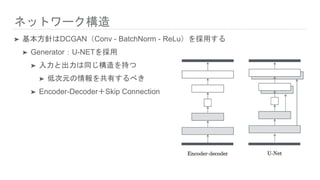
ネットワーク構造 ➤ 基本方針はDCGAN(Conv -
BatchNorm - ReLu)を採用する ➤ Generator:U-NETを採用 ➤ 入力と出力は同じ構造を持つ ➤ 低次元の情報を共有するべき ➤ Encoder-Decoder+Skip Connection
9.
ネットワーク構造 ➤ Discriminator:PatchGANを採用 ➤ L1ノルムやL2ノルムは画像をぼかす ➤
高周波数ではなく低周波数を正確にキャプチャする ➤ Dは高周波数のキャプチャに専念すれば良くなる ➤ 局所に注目させることが大事→パッチを見ていけば良い ➤ N×Nのパッチが”本物”か”偽物”かを見分ける ➤ パッチ径よりも遠いピクセル間の独立を仮定し,画像をマルコフ確率場としてモデル化する ➤ この仮定はテクスチャやスタイルのモデル化によく使われている ➤ PatchGANはテクスチャ・スタイルの損失関数として理解可能
10.
最適化と推論について ➤ 最適化:ミニバッチSGD+Adam ➤ 推論時も学習時と同じく行う ➤
ドロップアウト・BatchNormalizationの両方 ➤ バッチサイズ=1の時,BNはinstance normalizationとして扱われ, 画像生成の時に効果的であることが示されている ➤ 解くタスクによってバッチサイズを変える ➤ サイズは1か4
11.
実験 ➤ 様々なタスクに取り組む ➤ Semantic
labels ⇄写真(Cityscapes) ➤ Arcitechural labels→写真(CMP Facedes) ➤ 地図⇄航空写真(Google Maps) ➤ 白黒写真→カラー写真(ImageNet) ➤ 輪郭→写真(靴やカバンの画像) ➤ スケッチ→写真(人が書いたスケッチと写真) ➤ 昼→夜
12.
評価方針 ➤ 定性的評価 ➤ Amazon
Mechanical Turkによる比較実験 ➤ 生成画像を人が本物と思い込ませられたら良い ➤ AMTで50人×50回(練習10回+本番40回) ➤ 本物と偽物画像がそれぞれ1秒ずつ表示されて,そのあと本物を選択する ➤ 定量的評価 ➤ 生成した画像をFCNに入力した時の精度 ➤ もし本物のように生成できて入れば,FCNが正しく分類するはず
13.
目的関数の分析 ➤ 条件付きとL1が有効であるかどうか
14.
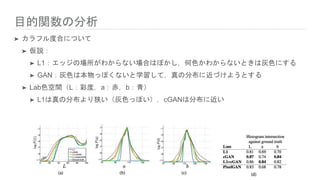
目的関数の分析 ➤ カラフル度合について ➤ 仮説: ➤
L1:エッジの場所がわからない場合はぼかし,何色かわからないときは灰色にする ➤ GAN:灰色は本物っぽくないと学習して,真の分布に近づけようとする ➤ Lab色空間(L:彩度,a:赤,b:青) ➤ L1は真の分布より狭い(灰色っぽい),cGANは分布に近い
15.
GENERATORの構造の分析 ➤ SkipConnectionが有効であるかどうか ➤ L1だけで学習した場合も有効に働いていることがわかる
16.
DISCRIMINATOR(PATCHGAN)の分析 ➤ パッチサイズN×Nを変えたときの効果 ➤ パッチサイズはDのレイヤ数で調節する ➤
空間的なシャープさは変わらない→カラフル度合いが変わる ➤ L1の時は灰色だが,1×1(PixelGAN)のとき赤くなる→分布と対応している ➤ 70×70の時が一番見た目も精度も良い
17.
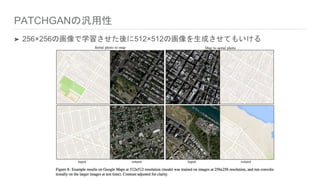
PATCHGANの汎用性 ➤ 256×256の画像で学習させた後に512×512の画像を生成させてもいける
18.
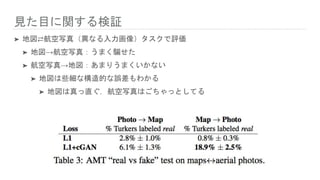
見た目に関する検証 ➤ 地図⇄航空写真(異なる入力画像)タスクで評価 ➤ 地図→航空写真:うまく騙せた ➤
航空写真→地図:あまりうまくいかない ➤ 地図は些細な構造的な誤差もわかる ➤ 地図は真っ直ぐ,航空写真はごちゃっとしてる
19.
見た目に関する検証 ➤ 白黒→カラー(同じ入力画像)タスクで評価 ➤ そこそこうまくいくものの,タスク特化した手法にはかなわない
20.
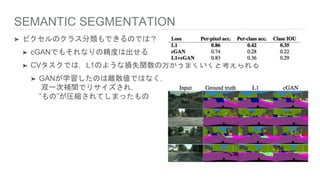
SEMANTIC SEGMENTATION ➤ ピクセルのクラス分類もできるのでは? ➤
cGANでもそれなりの精度は出せる ➤ CVタスクでは,L1のような損失関数の方がうまくいくと考えられる ➤ GANが学習したのは離散値ではなく, 双一次補間でリサイズされ, ”もの”が圧縮されてしまったもの
21.
そのほかの生成例
22.
そのほかの生成例
23.
そのほかの生成例
24.
そのほかの生成例
25.
そのほかの生成例
26.
そのほかの生成例
27.
失敗例 27
28.
まとめ ➤ なんでもできるGANの提案 ➤ 様々な出力が可能 ➤
タスク依存の目的関数を設定する必要がない ➤ ソースコード:https://github.com/phillipi/pix2pix ➤ 生成例:https://phillipi.github.io/pix2pix/ ➤ 例によってアニメ:http://kusanohitoshi.blogspot.jp/2016/12/deep-learning.html ラーメン:http://qiita.com/octpath/items/acaf5b4dbcb4e105a8d3
Download






















![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/alpha-gan-inpl-180417074219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial...](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170428-170428030525-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180514071433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)





![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Freehand-Sketch to Image Synthesis 2018](https://cdn.slidesharecdn.com/ss_thumbnails/hozumi110918-181109001844-thumbnail.jpg?width=640&height=640&fit=bounds)


























