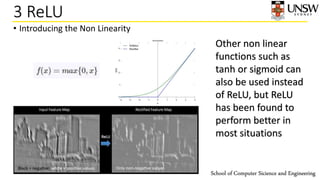
The document discusses convolutional neural networks (CNNs). It begins with an introduction and overview of CNN components like convolution, ReLU, and pooling layers. Convolution layers apply filters to input images to extract features, ReLU introduces non-linearity, and pooling layers reduce dimensionality. CNNs are well-suited for image data since they can incorporate spatial relationships. The document provides an example of building a CNN using TensorFlow to classify handwritten digits from the MNIST dataset.