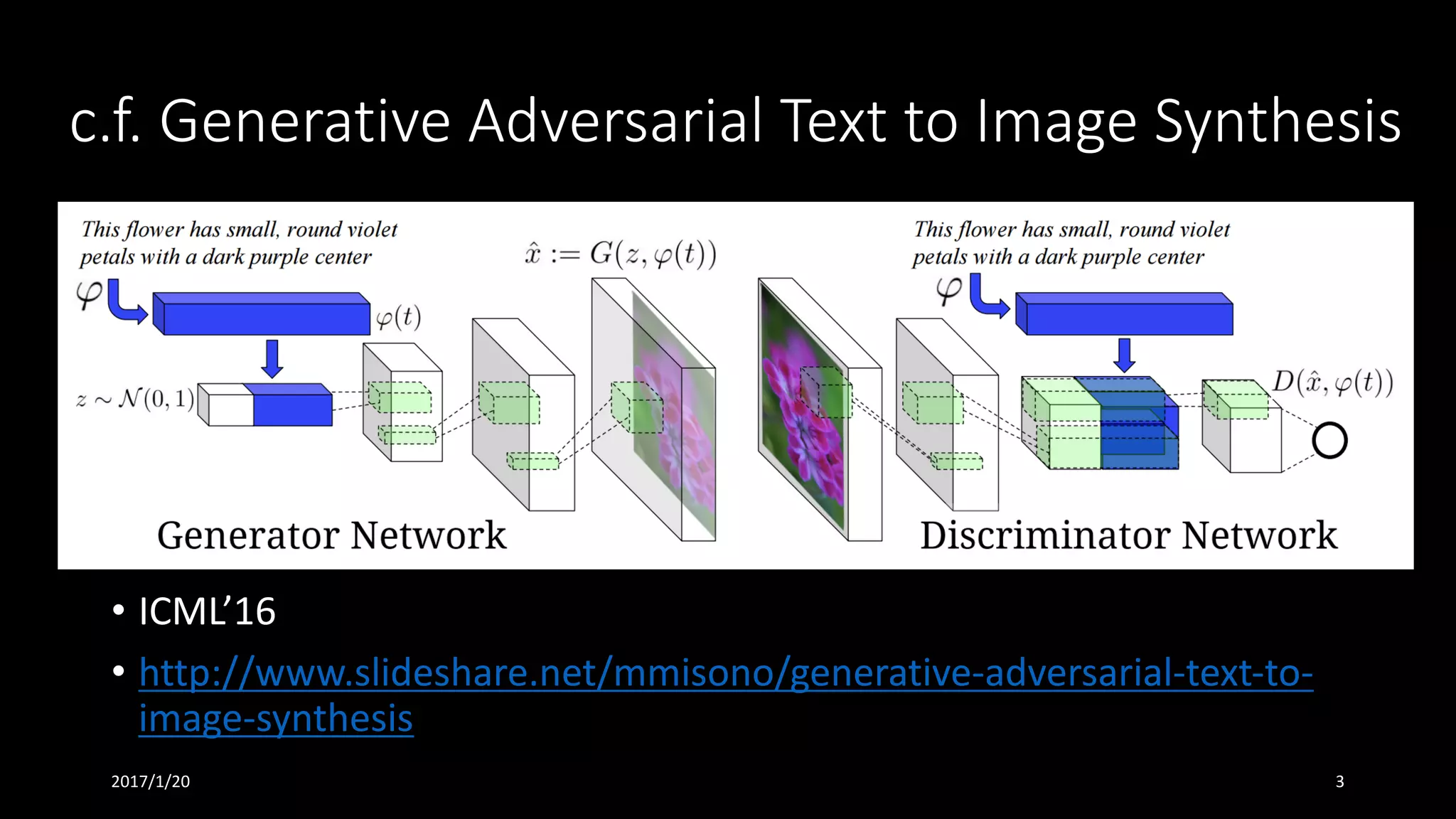
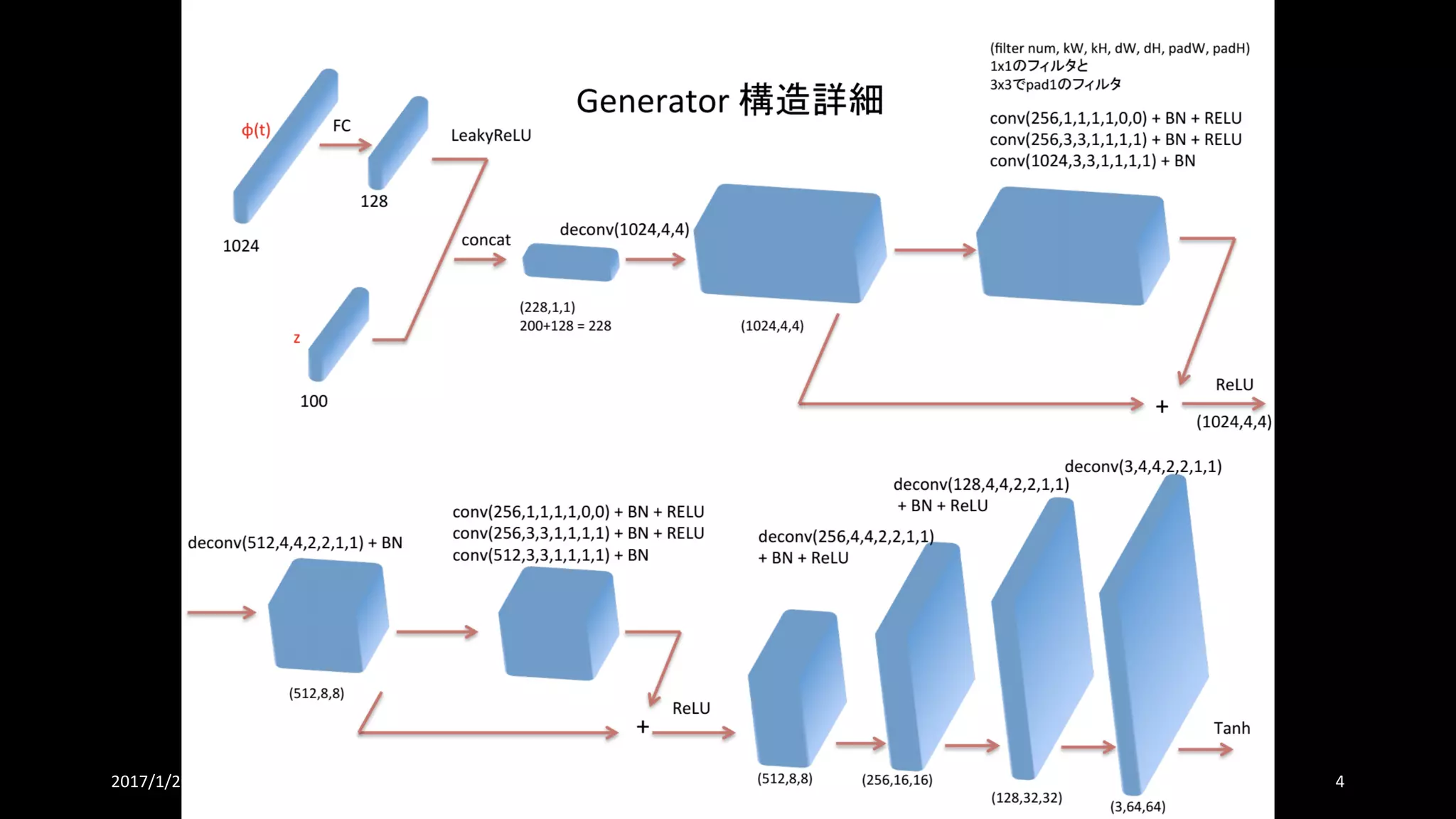
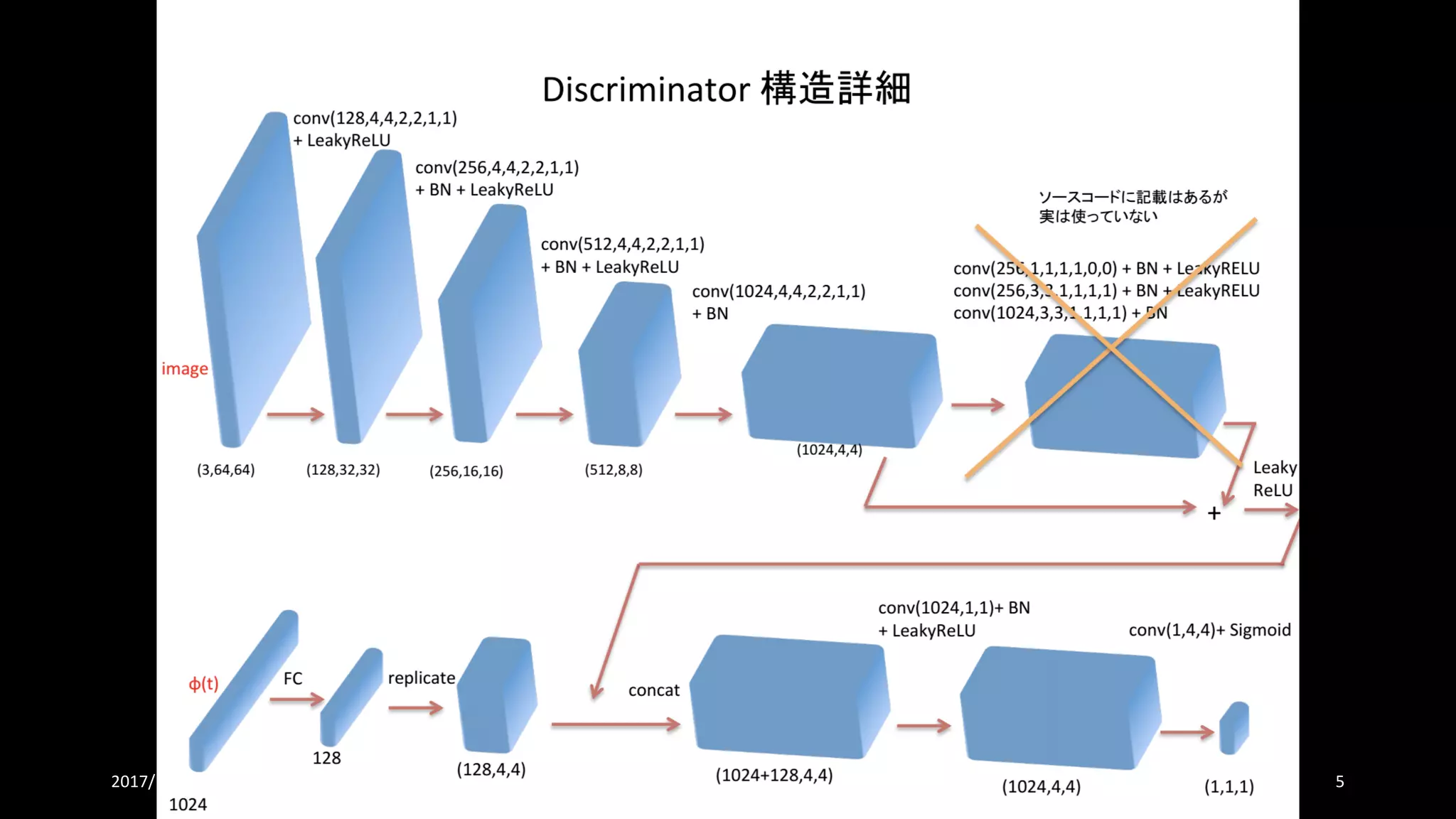
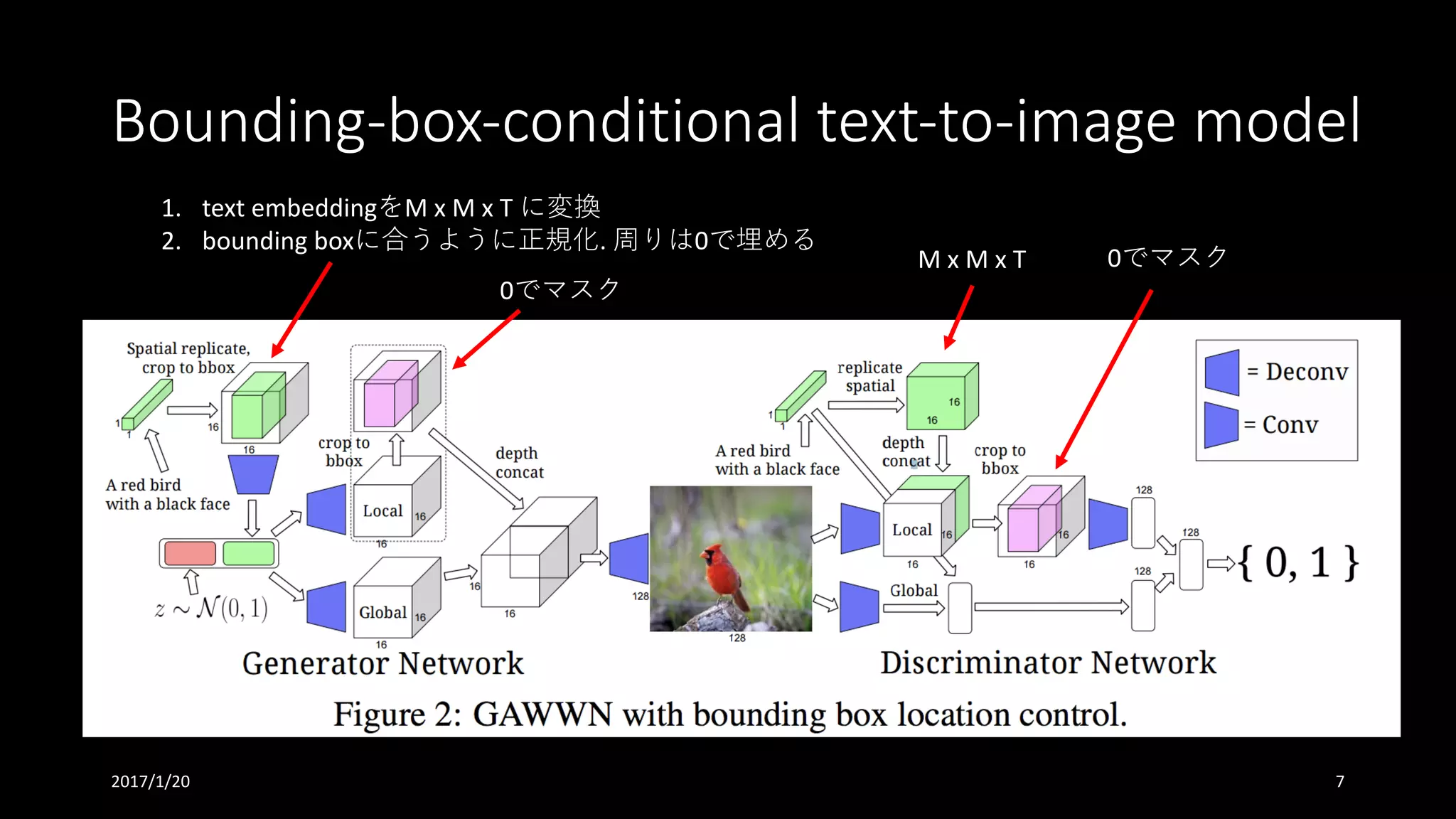
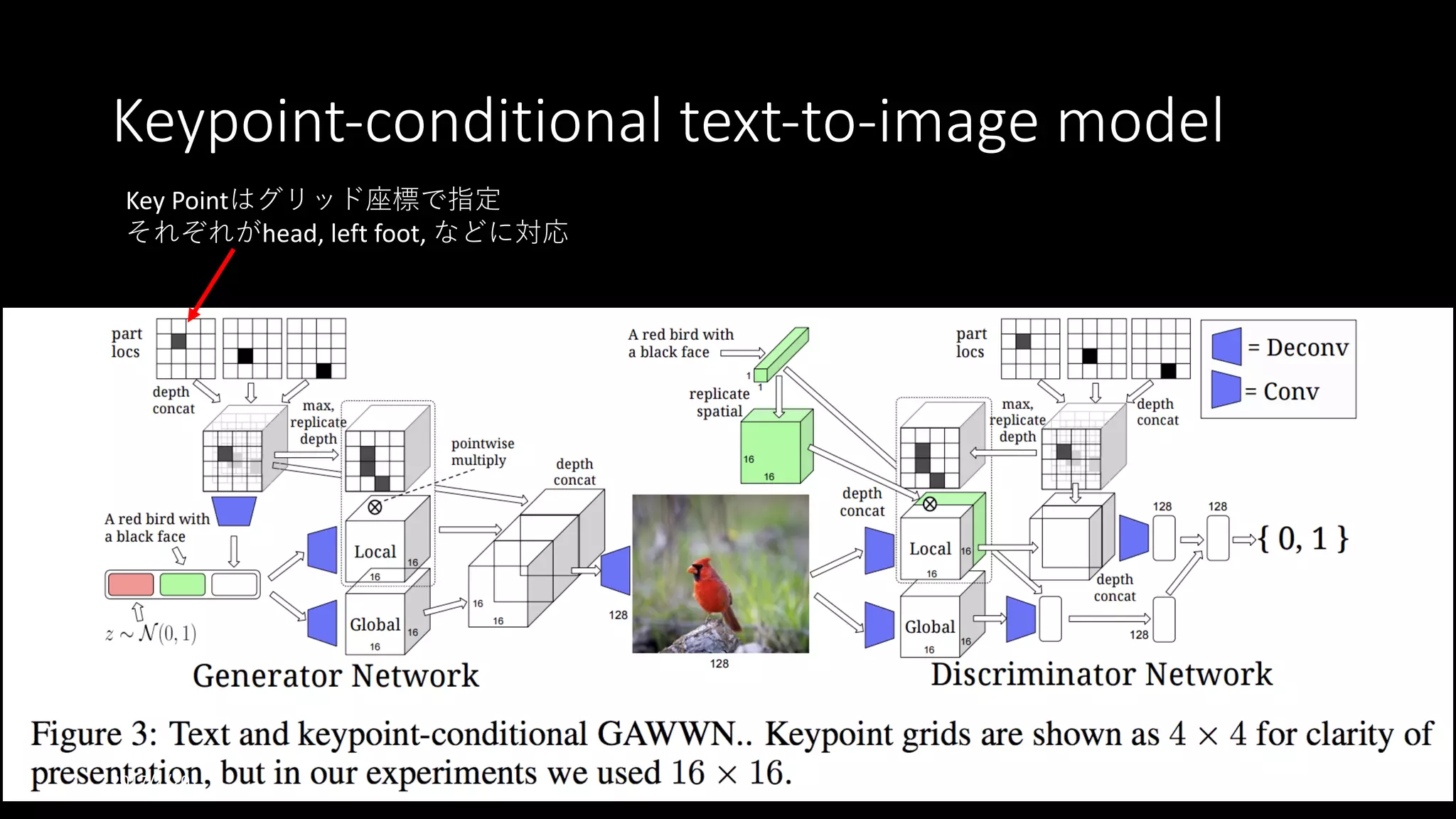
書誌情報
• Learning What and Where to Draw
• Scott Reed (Google), ZeynepAkata (MPI), Santosh Mohan (umich),
Samuel Tenka (umich), Bernt Schiele (MPI), Honglak Lee (umich)
• NIPS‘16 (Conference Event Type: Poster)
• https://papers.nips.cc/paper/6111-learning-what-and-where-to-draw
2017/1/20 2

















![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180514071433-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Freehand-Sketch to Image Synthesis 2018](https://cdn.slidesharecdn.com/ss_thumbnails/hozumi110918-181109001844-thumbnail.jpg?width=640&height=640&fit=bounds)
































