Active Object Localizationwith
Deep Reinforcement Learning
1
2016. 7.
김홍배, 한국항공우주연구원
第32回CV勉強会「ICCV2015読み会」, 皆川卓也
2.
소개 논문
ActiveObject Localization with Deep Reinforcement Learning
• Juan C. Caicedo, and Svetlana Lazebnik
• 물체검출 작업에 Deep Q-Network을 사용
2
3.
DEEP Q-NETWORK (DQN)
Q Learning이라는 강화학습 알고리즘에 Convolutional Neural
Network을 적용
아래 논문에서 기계에 컴퓨터게임을 하는 방법을 학습시켜 3/7로
인간을 이김
• Mnih, V., et al., “Playing Atari with Deep Reinforcement
Learning”, NIPS Deep Learning Workshop, 2013
• Mnih, V., et al., “Human-level control through deep
reinforcement learning”, Nature, 518 (7540), 529–533. 2015
3
4.
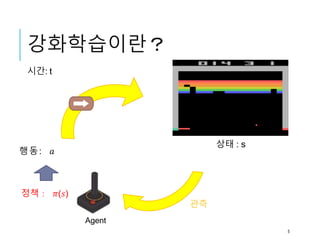
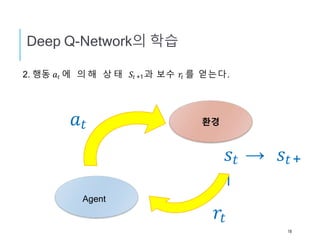
강화학습이란 ?
「어떤 환경에있어서 Agent가 현재의 상태를 관
측하여 취하여야 하는 행동(Action)을 결정하는 문
제를 다루는 기계학습의 일종. Agent는 행동을 선
택함으로써 보수(Reward) 를 얻는다. 강화학습은
일련의 행동을 통하여 보수가 가장 많게 얻을 수 있
도록 정책(policy)을 학습한다.」(Wikipedia)
4
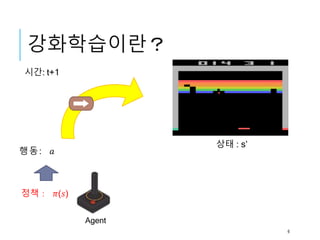
시간 : t+1
관측
보수: 𝑟𝑡
학습으로 구함
강화학습이란?
정책: 𝜋(𝑠')
상태 : s’
Agent
7
8.
어떻게 정책을 학습할까?
아래와 같이 보수의 합의 기대치가 최대가 되도록 지금의 행동을 결정
𝑅𝑡 = 𝑟𝑡 + 𝛾𝑟𝑡 +1 + 𝛾2 𝑟𝑡 +2 + ⋯ + 𝛾 𝑇−𝑡 𝑟 𝑇
보수의 합
감쇄율
장래의 보수
𝜋∗(𝑠) = argmax 𝔼[𝑅𝑡 |𝑠𝑡 = 𝑠, 𝑎𝑡= 𝑎]
𝑎
상태 s일때、보수의 합의 기대치가 최대가
되도록 행동 a를 선택
강화학습이란?
8
9.
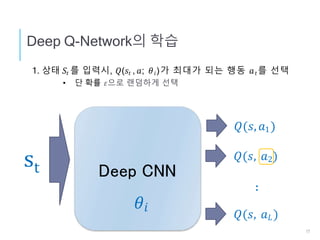
Q LEARNING
𝑄∗(𝑠, a)
상태s、행동 a의 조합의 “좋고” “나쁨”을
점수로 가르쳐주는 함수
상태 s일때、보수의 합의 기대치가 최대가 되도록 행동 a를 선택
𝜋∗(𝑠) = argmax 𝔼 𝑅𝑡 |𝑠𝑡 = 𝑠, 𝑎𝑡= 𝑎
𝑎
상태 s에서 행동 a를 취할 경우, 이후로 최적인 행동
을 계속 취할 경우에 얻게 되는 보수의 합의 기대치
𝜋를 대신해서 함수 Q를 학습
9
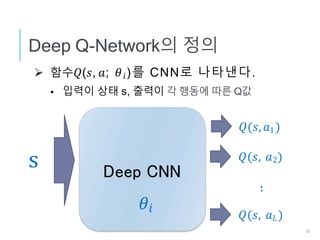
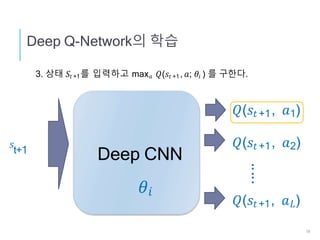
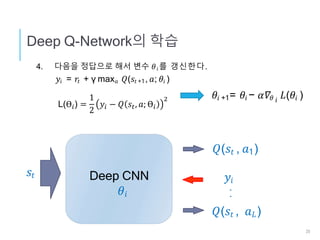
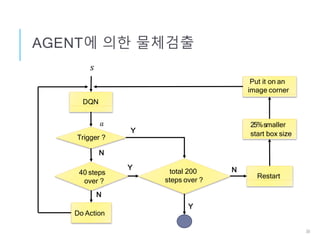
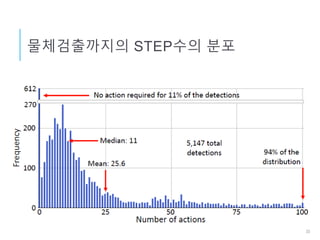
DQN로 물체검출
Agent: Bounding Box
행동, a : Bounding Box의 이동/형상변경
상태, s : Box내의 이미지 특징 벡터 + 행동이력
보수, r : 정답(Ground Truth)과의 오버랩비율
22
23.
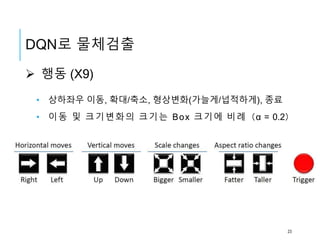
행동 (X9)
•상하좌우 이동, 확대/축소, 형상변화(가늘게/넙적하게), 종료
• 이동 및 크기변화의 크기는 Box 크기에 비례(α = 0.2)
DQN로 물체검출
23
24.
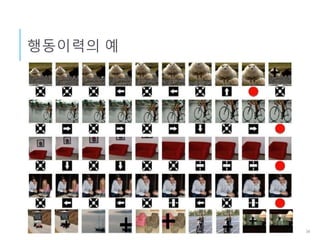
상태
• BoundingBox내 이미지로부터 특징 벡터를 구함
CNN에서 구한 4,096x1 벡터
• 과거의 행동이력
직전 10회의 행동까지
각각의 행동은 9x1 Binary 벡터로 표시
(취한 행동에 “1”, 나머지는 “0”)
10 x 9 = 90x1 벡터
• 4096+90 = 4186x1 벡터를 DQN의 입력으로 한다.
DQN로 물체검출
24
25.
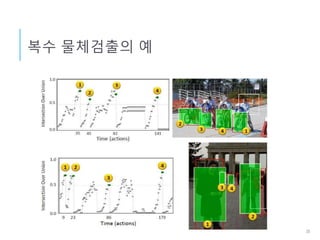
보수
b
g
𝐼𝑜𝑈 𝑏,𝑔 =
𝑎𝑟𝑒𝑎(𝑏 ∩ 𝑔)
𝑎𝑟𝑒𝑎(𝑏 ∪ 𝑔)
𝑅 𝑎( 𝑠, 𝑠‘) = 𝑠𝑖𝑔𝑛 (𝐼𝑜𝑈(𝑏′, 𝑔) − 𝐼𝑜𝑈(𝑏, 𝑔))
Agent
Ground Truth
정답과의 오버랩 비율
(Intersection over Union)
Trigger(종료)이외의행동에대한보수
오버랩 비율이 커지면 1 , 작아지면 - 1
DQN로 물체검출
25
26.
b
g 𝐼𝑜𝑈 𝑏,𝑔 =
𝑎𝑟𝑒𝑎(𝑏 ∩ 𝑔)
𝑎𝑟𝑒𝑎(𝑏 ∪ 𝑔)
Agent
Ground Trut
h
오버랩 비율이 임계치, 𝜏 이상이면 +𝜂、이하면 −𝜂
+𝜂 𝑖𝑓 𝐼𝑜𝑈 𝑏, 𝑔 ≥ 𝜏
−𝜂 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
보수
정답과의 오버랩 비율
Trigger(종료)에대한보수
𝑅w( 𝑠, 𝑠‘) =
DQN로 물체검출
26
27.
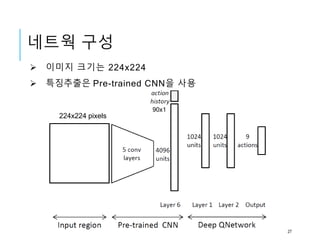
네트웍 구성
이미지크기는 224x224
특징추출은 Pre-trained CNN을 사용
90x1
224x224 pixels
27
28.
Agent의 학습
Ε-GREEDY알고리즘
확률 ε로 랜덤하게 행동을 선택
• 그 이외에는 가장 Q값이 큰 행동으로
• 본 방법에서는 학습시 정답 데이터를 알고 있으므로
보수가 “+”인 행동 중에서 랜덤하게 선택
ε 은 학습이 진행됨에 따라 작아진다.
28
29.
Experience Replay
과거의 (𝑠 𝑡, 𝑎 𝑡, 𝑟𝑡, 𝑠𝑡 +1)를 replay-memory에 보존
DQN의 학습 시, 보존된 replay-memory로부터
랜덤하게 선택된 미니뱃치로 재학습
Agent의 학습
29






![어떻게 정책을 학습할까 ?
아래와 같이 보수의 합의 기대치가 최대가 되도록 지금의 행동을 결정
𝑅𝑡 = 𝑟𝑡 + 𝛾𝑟𝑡 +1 + 𝛾2 𝑟𝑡 +2 + ⋯ + 𝛾 𝑇−𝑡 𝑟 𝑇
보수의 합
감쇄율
장래의 보수
𝜋∗(𝑠) = argmax 𝔼[𝑅𝑡 |𝑠𝑡 = 𝑠, 𝑎𝑡= 𝑎]
𝑎
상태 s일때、보수의 합의 기대치가 최대가
되도록 행동 a를 선택
강화학습이란?
8](https://image.slidesharecdn.com/q-learning001-160714082644/85/Q-Learning-CNN-Object-Localization-8-320.jpg)



![Q LEARNING
𝑄∗(𝑠, 𝑎) = 𝑟𝑡 + 𝛾 max 𝑄∗(𝑠′, 𝑎′)
𝑅𝑡 = 𝑟𝑡 + 𝛾𝑟𝑡+1 + 𝛾2 𝑟𝑡+2 + ⋯ + 𝛾 𝑇−𝑡 𝑟𝑇
보수의 합
𝑅𝑡 = 𝑟𝑡 + 𝛾𝑅𝑡+1
𝑄∗(𝑠, 𝑎) = 𝔼 [𝑅𝑡 |𝑠𝑡 = 𝑠, 𝑎𝑡= 𝑎]
𝑎에 의해 바뀐 상태𝑎′
12](https://image.slidesharecdn.com/q-learning001-160714082644/85/Q-Learning-CNN-Object-Localization-12-320.jpg)

















![[DL輪読会]Deep Neural Networks as Gaussian Processes](https://cdn.slidesharecdn.com/ss_thumbnails/dl0216okamoto2162-180323031830-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Pycon 2015] 오늘 당장 딥러닝 실험하기 제출용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2015-150913033231-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






















































