+
Related Work
n 古典的なアプローチ
n データとラベルの結合分布のモデル化
n GMM
n HMM
n ラベルありデータとなしデータのマージン最大化
n TSVM
n S3VM
n これらの半教師学習はサンプル間の類似度を利用
n あるラベルなしデータがAのラベルデータに似ていれば、そのデー
タはAとみなす
17/02/09
2
4.
+
Related Work
n 半教師deeplearning
n ConvNetの性能をあげるためにラベルなしデータをつかう
n convnetのフィルターをpretrainするなど
n ほかの論文でのアプローチ
n predictive sparse decomposition
n resion embedding
n ladder networks
17/02/09
3
+
Experiments and Results
n MNIST
n 100サンプルでstate of the art
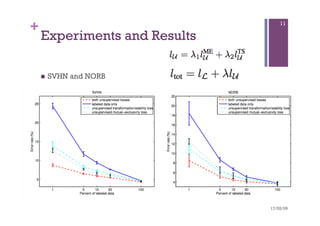
n SVHN and NORB
n CIFAR10
n state of the art
n CIFAR100
n state of the art
n ImageNet
17/02/09
9
+
実際に実装してみた(ができなかっ
た)
n MNISTでやってみた
n データオーグメンテーションによるlossTS関数の最小化
n lossME関数の最小化
n クロスエントロピーによるラベルあり損失関数の最小化
n tensorflowをつかった
n 一部kerasを使っている
n できなかったが、誰かアドバイスをくれることを願ってgithub
にあげた
n https://github.com/HironoOkamoto/hoge/blob/master/semi
%20supervised%20mnist%20tensorflow-12.ipynb
17/02/09
12







![+
Experiments and Results
n MNIST
n 100サンプルではstate of the art
n 全ラベルでは、誤差0.24が最高精度[40]
17/02/09
10](https://image.slidesharecdn.com/regularizationwithstochastictransformationsandperturbationsfordeepsemi-supervisedlearning-170215034444/85/DL-Regularization-with-stochastic-transformations-and-perturbations-for-deep-semi-supervised-learning-11-320.jpg)









![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]High-Quality Self-Supervised Deep Image Denoising](https://cdn.slidesharecdn.com/ss_thumbnails/high-qualityself-superviseddeepimagedenoising-200501014639-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)






















