NAIST ICML読み会の発表資料です。 https://ahclab.naist.jp/wiki/Jornal/Conference_paper_reading [論文]: http://jmlr.org/proceedings/papers/v48/lie16.html




![2016/7/16 2016ⒸSeitaro Shinagawa AHC-lab NAIST
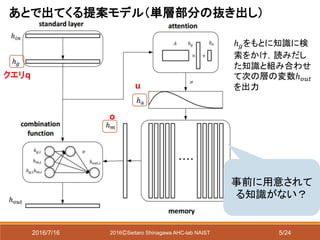
外部メモリを導入している先行研究
End-To-End Memory Networks [Sukhbaatar, S, 2015]
https://papers.nips.cc/paper/5846-end-to-end-memory-networks.pdf
𝒖 B 𝒒
𝒄 𝒏 C 𝒙 𝟏 𝒙 𝟐 𝒙 𝒏𝒄𝒊𝒄 𝟏
𝒎 𝒏 A𝒎𝒊𝒎 𝟏
𝑝𝑖 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝒎𝑖 ⋅ 𝒖
𝒐 =
𝑖
𝑝𝑖 ⋅ 𝒄𝒊
𝑎 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑊 𝑜 + 𝑢
Embed
matrix
検索用の
知識
知識データ
ベース
クエリ
回答用の
知識
記憶、質問、回答の一連のプロセスを
end-to-endで学習させることができる
4/24](https://image.slidesharecdn.com/160716icmlpaperreading-160716123510/85/20160716-ICML-paper-reading-Learning-to-Generate-with-Memory-4-320.jpg)
![2016/7/16 2016ⒸSeitaro Shinagawa AHC-lab NAIST
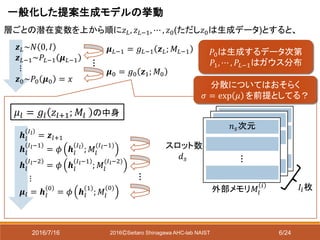
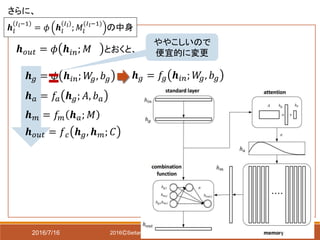
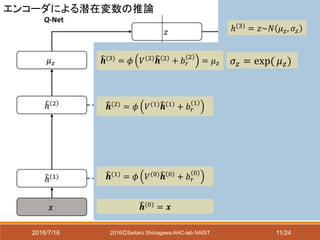
具体例 潜在変数層1つ(𝐿 = 1),
メモリ枚数2枚(𝐼1 = 2)の場合
𝒉 3
= 𝑧~𝑁 𝜇 𝑧, 𝜎𝑧
𝒉 𝑔
2
= 𝑓𝑔 𝑊𝑔
2
𝒉 3 + 𝑏 𝑔
2
𝒉 𝑎
2
= 𝑓𝑎 𝐴 2 𝒉 𝑔
2
+ 𝑏 𝐴
2
𝒉 𝑚
2
= 𝑀(2) 𝒉 𝑎
2
𝒉 2 = 𝑓𝑐 𝒉 𝑔
2
, 𝒉 𝑚
2
; 𝐶
𝑓𝑐 𝒉 𝑔
2
, 𝒉 𝑚
2
; 𝐶 = 𝒉 𝑔
2
+ 𝒉 𝑚
2
とするのが素直だが、Ladder
Network[Rasmus 2015]
を参考に別の関数を使う
𝑓𝑎はシグモイド関数か
ソフトマックス関数
(実験ではソフトマックス)
次で説明
8/24](https://image.slidesharecdn.com/160716icmlpaperreading-160716123510/85/20160716-ICML-paper-reading-Learning-to-Generate-with-Memory-8-320.jpg)

![2016/7/16 2016ⒸSeitaro Shinagawa AHC-lab NAIST
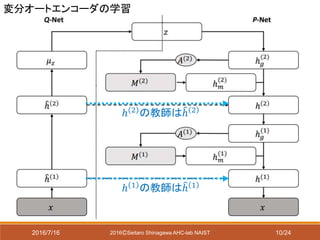
local reconstruction error
(Ladder Network [Rasmus 2015]に倣っ
たらしい)
変分下限
変分下限と目的関数
= 𝔼 𝑞 𝒛|𝒙;𝜽 𝑟
log 𝑝 𝒙|𝒛; 𝜽 𝑔 − 𝐾𝐿 𝑞 𝒛|𝒙; 𝜽 𝒓 ||𝑝 𝒛; 𝜽 𝑔
対数尤度 正則化項
目的関数
変分下限
?
変分下限は最大化
したいのでここは多分
マイナス?
12/24](https://image.slidesharecdn.com/160716icmlpaperreading-160716123510/85/20160716-ICML-paper-reading-Learning-to-Generate-with-Memory-12-320.jpg)
![2016/7/16 2016ⒸSeitaro Shinagawa AHC-lab NAIST
実験設定
MNIST(手書き文字認識)
訓練用50000, 確認用10000, テスト用10000
28x28 pixel/画像
OCR-letters(光学文字認識)
訓練用32152, 確認用10000, テスト用10000
16x8 pixel/画像
Frey faces datasets
1965
28x20 pixel/画像
分布にBernoulli分布を仮定
分布にGaussian分布を仮定
𝑓𝑎にソフトマックスを使うという
話と矛盾
付録Dを除くとあったので
Dのみソフトマックス
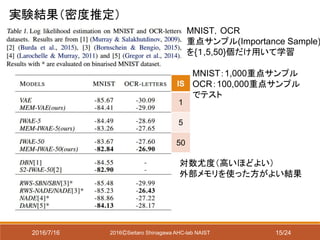
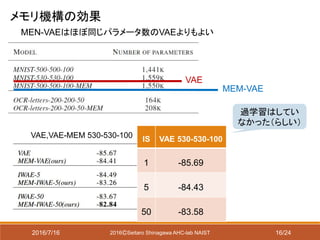
以下の学習手法について比較
VAE:普通の変分オートエンコーダ
IWAE[Burda 2015]:重要度重みを考慮した対数尤度の推定
MEM-VAE:外部メモリ付きVAE
𝑓𝑎と 𝑓𝑐にそれぞれsigmoid関数とelement-wise MLPを用いる
MEM-IWAE:外部メモリ付きIWAE
13/24](https://image.slidesharecdn.com/160716icmlpaperreading-160716123510/85/20160716-ICML-paper-reading-Learning-to-Generate-with-Memory-13-320.jpg)




![2016/7/16 2016ⒸSeitaro Shinagawa AHC-lab NAIST
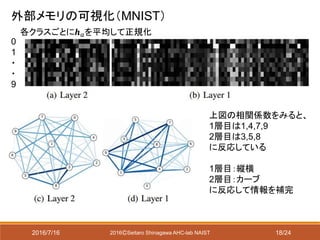
欠損値代入タスク(画像修復タスク)
MNISTで実験
ノイズの種類
RECT-12 中心12x12 pixelを欠損
RAND-0.6 各ピクセルを確率0.6で欠損
HALF 左半分を欠損
欠損部分はランダムな値で初期化
欠損画像を入力して生成した出力を次の入力とする
これを100epoch繰り返す
欠損値の修復の方法
MSEによる比較
21/24
http://arxiv.org/pdf/1401.4082v3.pdf[Rezende 2014]
欠損してないピクセルも変動し
てしまうので非欠損ピクセルを
固定でBPするのもあり?](https://image.slidesharecdn.com/160716icmlpaperreading-160716123510/85/20160716-ICML-paper-reading-Learning-to-Generate-with-Memory-21-320.jpg)

















![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)










