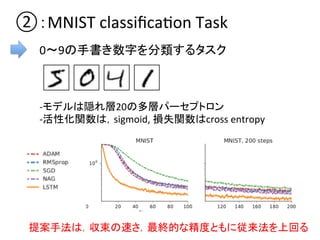
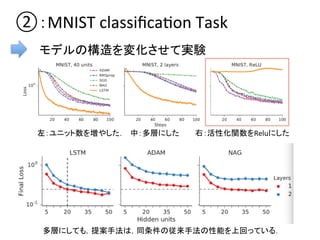
第2回NIPS読み会の発表資料です.learning to learn by gradient decent by gradient decent. OptimizerをLSTMとして表現し,逆誤差伝播によりそれを最適化. 目的関数の成分ごと独立に,パラメタを共有したLSTMで最適化を行うことで最適化すべきOptimizerのパラメタ数を小さく抑える.







![・No
Free
Lunch
Theorems
for
OpDmizaDon
全ての問題に対して高性能な最適化アルゴリズムは存在しない.
[Wolpert
and
Macready
1997]
解くべき問題の性質に応じて,利用する最適化アルゴリズムを
使い分ける必要がある.](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-8-320.jpg)
![・現状,gはヒューリスティックに作り込まれている
勾配法をベースに,高次元で,非凸な目的関数に対しても良い
性能を示すような最適化アルゴリズムは多く“作り込まれて”いる
・momentumSGD
[Nesterov
1983,
Tseng
1998]
・Adagrad
[Duchi
et
al.
2011]
・RMSprop
[Tieleman
and
Hinton
2012]
・ADAM
[Kingma
and
Ba
2015]
参考:hap://postd.cc/opDmizing-‐gradient-‐descent/
例: 勾配降下法(一番単純な場合)
-‐ナイーブすぎて,これは多くの場合うまくいかない](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-9-320.jpg)
![・問題意識
問題に応じて,データから自動で最適な変換 g を学習さ
せることはできないだろうか?
-‐もっとTask
specificに
g
を作り込むことができれば性能は上がる
(
No
Free
Lunch
Theorem
[Wolpert
and
Macready
1997]
)
-‐現状,g
はある程度の汎用性を持つ形で作られている](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-10-320.jpg)

![・”Meta-‐Learning”という系譜
OpDmizer
g
をデータから学習するという話は昔からあって,Meta-‐
learning(learning
to
learn)という一連の流れとして位置づけられる.
①,変換 g の関数形自体を遺伝的プログラミングを用いて最適化
[Y.Bengio
et
al
1995]
②,変換 g をパラメタ φ
で特徴付けられたRNNの出力としてとらえ,
誤差の微分情報を用いてφを更新する[S.
Hochreiter
et
al
2001]
微分をするか,しないか](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-12-320.jpg)
![・問題設定:[S.
Hochreiter
et
al
2001],[M.Andrychowicz
et
al. 2016]
L(φ)がφに関して微分可能であれば,OpDmizer
g(φ)
を,
期待損失 L(φ) の微分情報を用いて逆誤差伝播で最適
化できる.
-‐
OpDmizer
g
をパラメータφで直接特徴付ける g(∇f, φ)
-‐ そのため,OpDmizeeの最適なパラメタθ*は,θ(f, φ)と書ける
-‐ そのため,期待損失関数 L(φ) はφの関数として書ける](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-13-320.jpg)
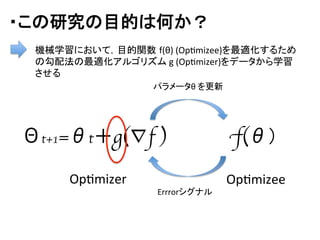
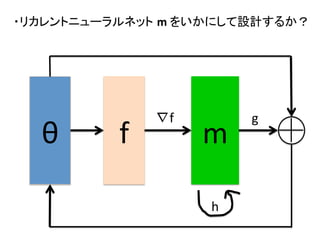
![・問題設定:[S.
Hochreiter
et
al
2001],[M.Andrychowicz
et
al. 2016]
-‐Opimizerのupdate
step
gtをリカレントニューラルネットワーク
m
の出力として表現
-‐計算グラフを遡ることで,RNNのパラメタφが更新可能
を仮定](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-14-320.jpg)


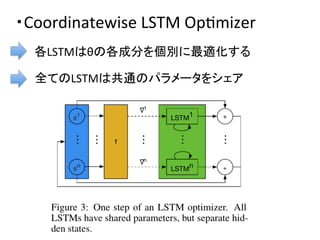
![・[S.
Hochreiter
et
al
2001]ではFully
connected
LSTM
-‐
θ
の次元が大きいと,LSTMのパラメタ数が大きくなり,
最適化が難しいし,計算的にも重い.
-‐ Deep
neural
networkのようなパラメタθの次元が大きい
問題に対して適用することは難しかった.(θの次元は数万〜)](https://image.slidesharecdn.com/2nips-170226094440/85/2-nips-Learning-to-learn-by-gradient-decent-by-gradient-decent-18-320.jpg)











![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ODT: Online Decision Transformer](https://cdn.slidesharecdn.com/ss_thumbnails/20220318-220322065805-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)







