[Kaiser etal., 2018][Roy et al., 2018]
◦ posterior: VQ-VAEにより𝑥𝑥, 𝑦𝑦から離散潜在変数𝑧𝑧の系列を生成 (訓練時のみ)
◦ prior: Transformerにより𝑥𝑥から𝑧𝑧を予測
◦ decoder: Transformerにより𝑥𝑥, 𝑧𝑧から𝑦𝑦を予測
◦ 各関数は独立に学習(すなわち、全体の尤度最大化には直接結びつかない)
FlowSeq [Ma et al., 2019]
◦ Generative flowを使った変分学習
◦ 潜在変数のrefinementはしていない(やろうと思えばできるはず)
19
Roy et al., Theory and Experiments on Vector Quantized Autoencoders, arXiv preprint
arXiv:1805.11063, 2018.
Kaiser et al., Fast Decoding in Sequence Models using Discrete Latent Variables, ICML 2018.
Ma et al., FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow,
EMNLP 2019.


![ 機械翻訳
質問応答
対話応答
要約生成
画像/動画像キャプショニング
3
https://headline.okazakilab.org/
https://support.apple.com
/ja-jp/HT204389
https://www.amazon.co.jp
/dp/B00X4WHP5E https://robo.meicom.jp/use/first.html
[Vinyals et al., 2015]](https://image.slidesharecdn.com/non-autoregressivenmt-200617081817/75/Non-autoregressive-text-generation-3-2048.jpg)


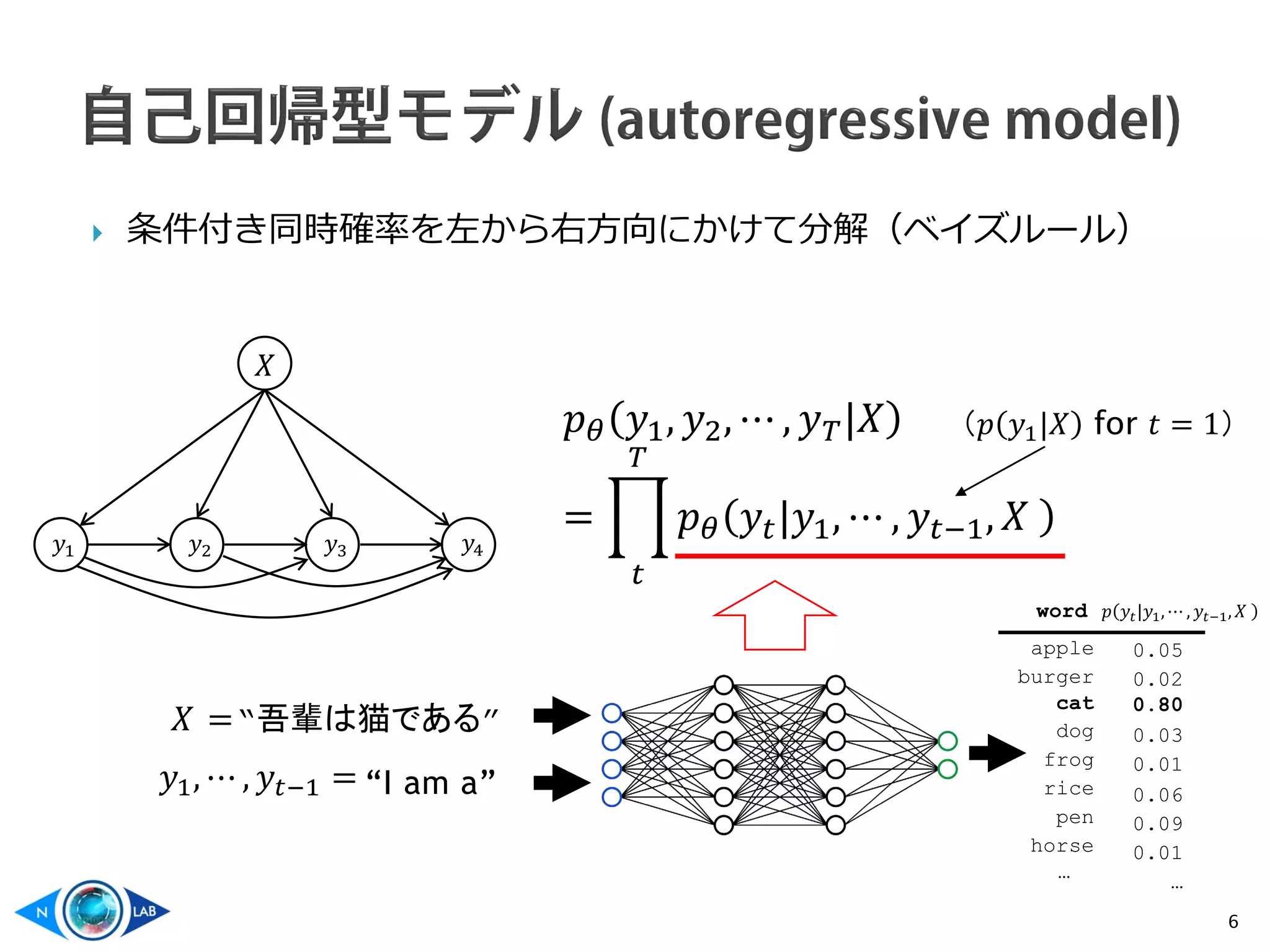
![ 深層学習の発展により、非常に優れた性能を発揮するように
7Transformer
RNN (LSTM)
[Vaswani+, 2017]
[Sutskever+, 2014]](https://image.slidesharecdn.com/non-autoregressivenmt-200617081817/75/Non-autoregressive-text-generation-7-2048.jpg)




![ 非自己回帰型のモデルでうまくいっている?
低解像度の特徴マップからの
アップサンプリング
◦ 階層的な潜在表現になっている
◦ 全体のラフな構造を先に決定し、
徐々にローカルな部分を決めていく
12
生成ネットワーク識別ネットワーク
PGGAN [Karras et al., ICLR 2018]
生成された画像の例 (PGGAN)](https://image.slidesharecdn.com/non-autoregressivenmt-200617081817/75/Non-autoregressive-text-generation-12-2048.jpg)


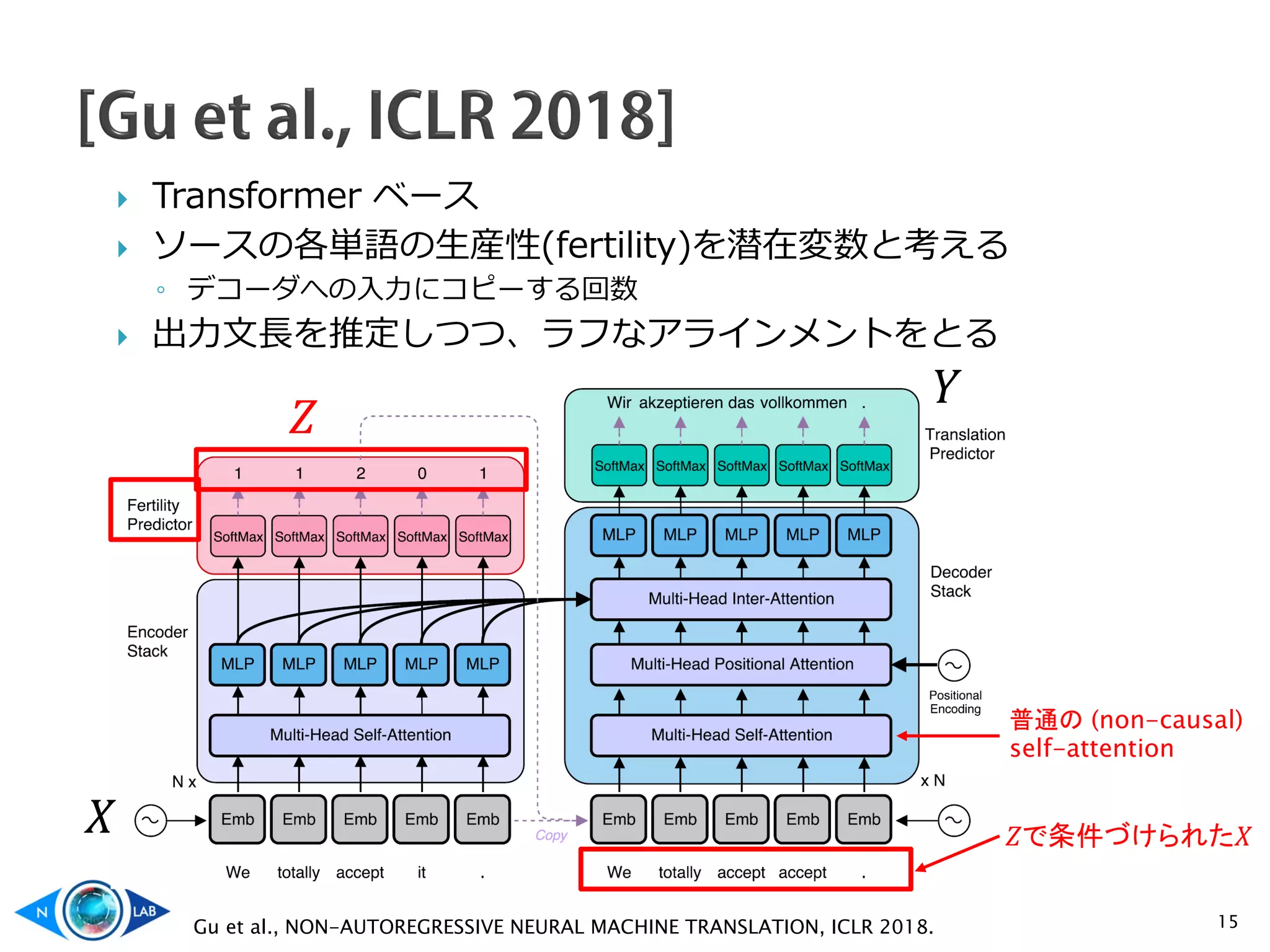

![ 穴埋め [Ghazvininejad et al., EMNLP 2019][Lawrence et al., EMNLP 2019]
◦ 自信のない部分にマスクをかけ、繰り返しながら埋めていく
17
Mask-Predict [Ghazvininejad et al., EMNLP 2019]
編集操作(挿入・削除など)[Stern et al., ICML 2019][Welleck et al.,
ICML 2019] [Gu et al., TACL 2019][Gu et al., NeurIPS 2019]
◦ 動的に出力文のサイズを調整しつつ編集
Insertion Transformer [Stern et al., ICML 2019]](https://image.slidesharecdn.com/non-autoregressivenmt-200617081817/75/Non-autoregressive-text-generation-17-2048.jpg)

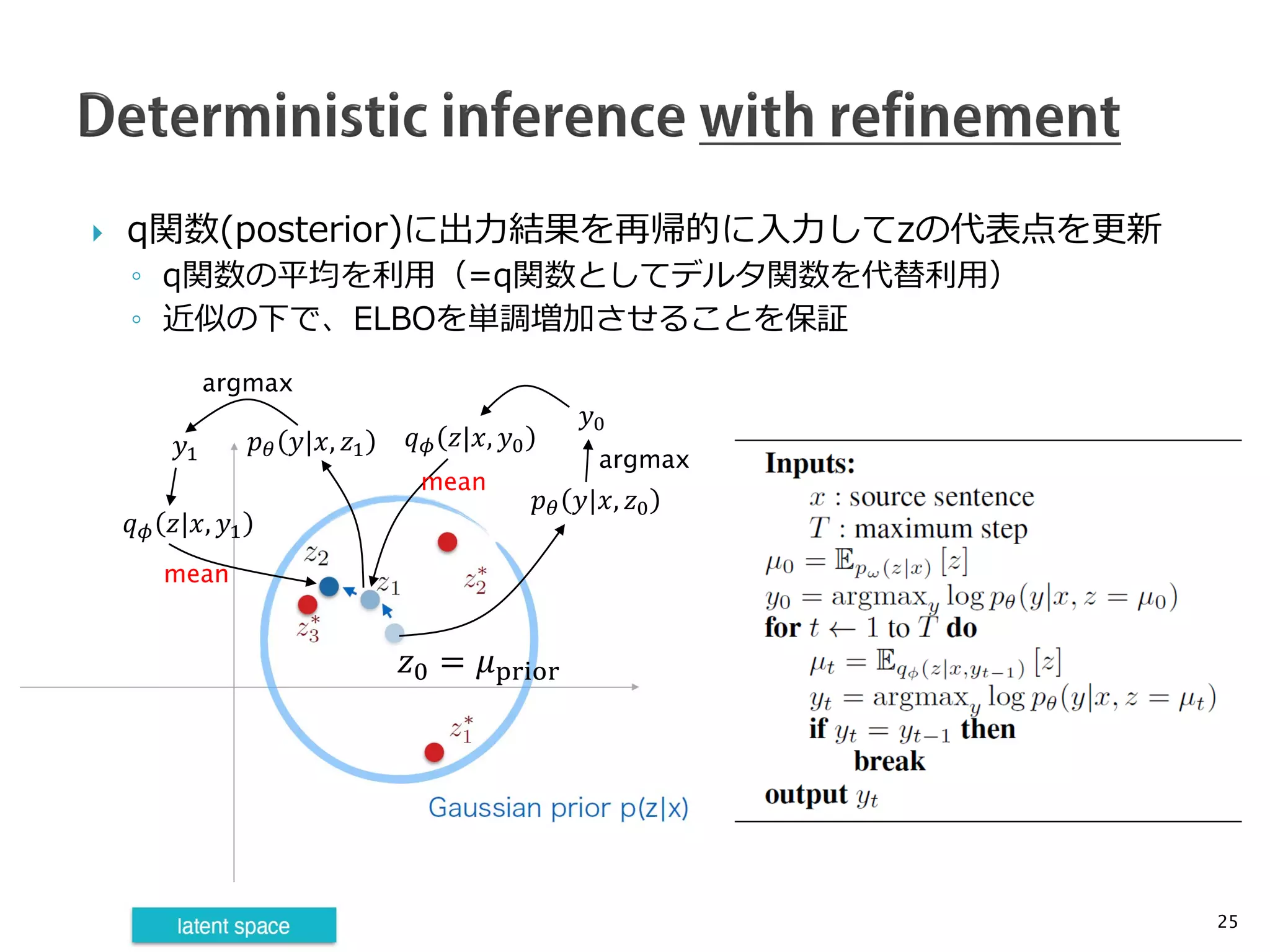
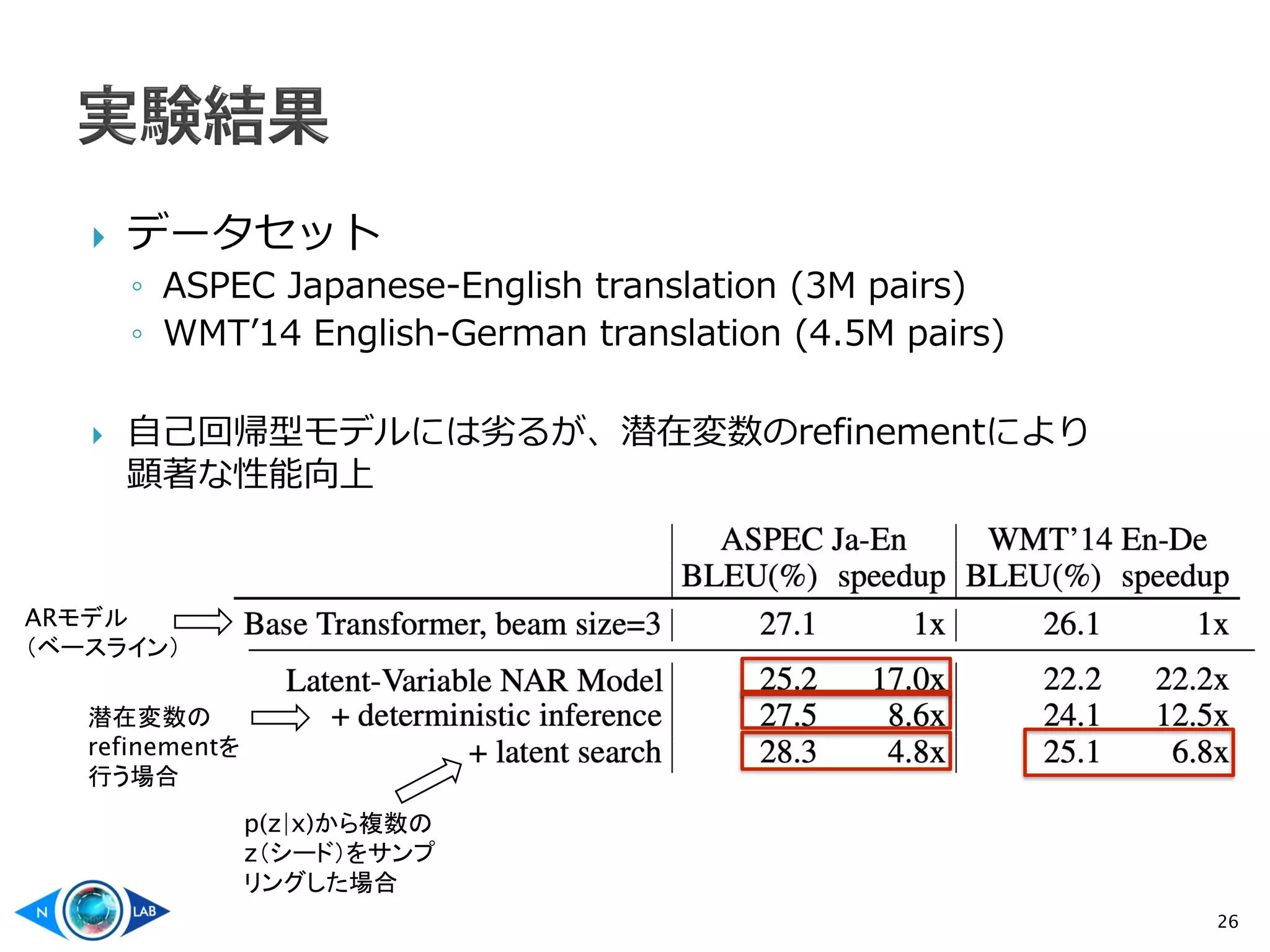
![ [Kaiser et al., 2018][Roy et al., 2018]
◦ posterior: VQ-VAEにより𝑥𝑥, 𝑦𝑦から離散潜在変数𝑧𝑧の系列を生成 (訓練時のみ)
◦ prior: Transformerにより𝑥𝑥から𝑧𝑧を予測
◦ decoder: Transformerにより𝑥𝑥, 𝑧𝑧から𝑦𝑦を予測
◦ 各関数は独立に学習(すなわち、全体の尤度最大化には直接結びつかない)
FlowSeq [Ma et al., 2019]
◦ Generative flowを使った変分学習
◦ 潜在変数のrefinementはしていない(やろうと思えばできるはず)
19
Roy et al., Theory and Experiments on Vector Quantized Autoencoders, arXiv preprint
arXiv:1805.11063, 2018.
Kaiser et al., Fast Decoding in Sequence Models using Discrete Latent Variables, ICML 2018.
Ma et al., FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow,
EMNLP 2019.](https://image.slidesharecdn.com/non-autoregressivenmt-200617081817/75/Non-autoregressive-text-generation-19-2048.jpg)













![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)







![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)








![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)























