Triple-GANのまとめ
l Triple-GANはGenerator とDiscriminator に加えて Classifier を導入
した
l これにより半教師あり学習が可能となった
l 学習後の Generator はこれまでのモデルよりリアルな画像を生成し
た
l 学習後の Classifier はこれまでのモデルより識別性能が上がった
l このしくみは特に少ない教師データで学習する際に威力を発揮する
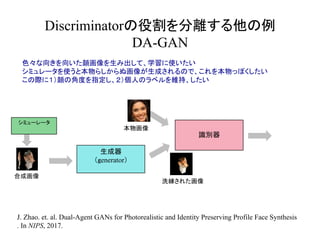
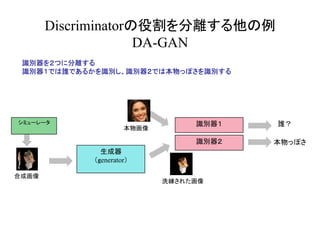
半教師あり学習の他の例
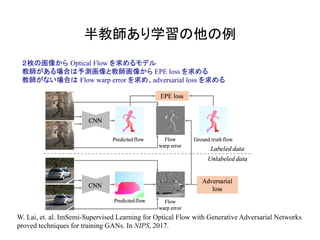
2枚の画像から Optical Flowを求めるモデル
教師がある場合は予測画像と教師画像から EPE loss を求める
教師がない場合は Flow warp error を求め、adversarial loss を求める
W. Lai, et. al. ImSemi-Supervised Learning for Optical Flow with Generative Adversarial Networks
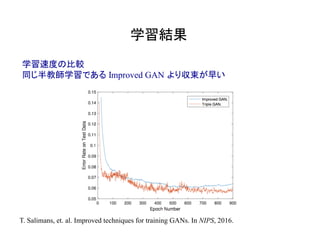
proved techniques for training GANs. In NIPS, 2017.



















































![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] Learning from Simulated and Unsupervised Images through Adversarial T...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks1708281-170907071224-thumbnail.jpg?width=640&height=640&fit=bounds)


















