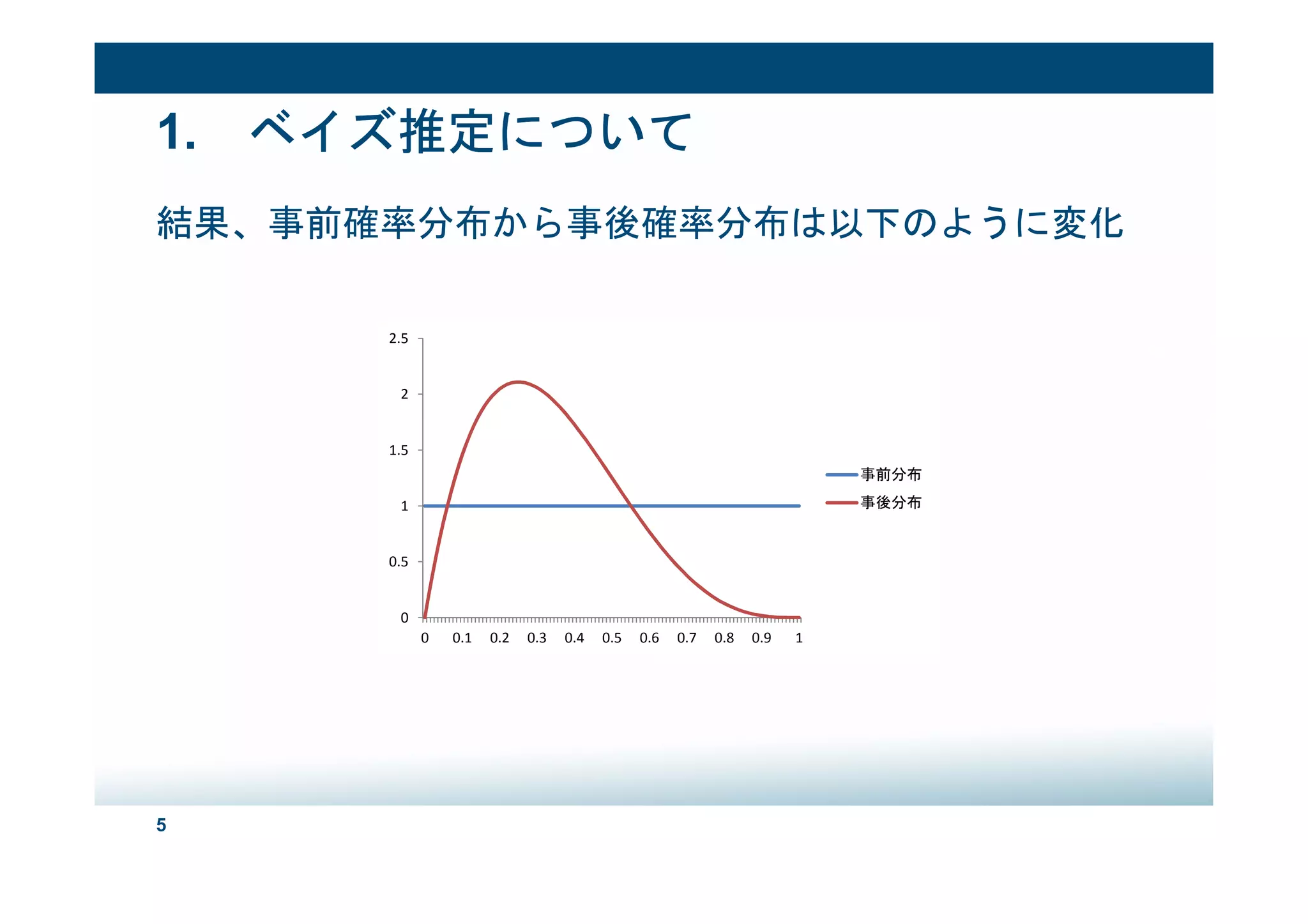
先日の某勉強会にて発表した資料がいい感じにまとめられたのでシェア。 一部保険数理業界向け。 MCMCもさることながら、我々の業界ではずいぶんと当たり前になってきた「パラメータリスク」という概念も流行ってほしいです。














![15
2. MCMC(Markov Chain Monte Carlo)について
stanコードの書き方例:事前分布を(0,1)の一様分布とする
θをパラメータとするN件のベルヌーイ試行のデータyが得
られた場合のθの事後分布を出したい
data {
int<lower=0> N;
int<lower=0,upper=1> y[N];
}
parameters {
real<lower=0,upper=1> theta;
}
model {
theta ~ uniform(0,1);
for (n in 1:N)
y[n] ~ bernoulli(theta);
}
ただの入力データ形式の宣言
(データは別途入力)
ただのパラメータの宣言
事前分布の設定
尤度を計算するためのデータ
発生のメカニズムの設定](https://image.slidesharecdn.com/mlst3teamc10logofreev-140314053652-phpapp02/75/MCMC-16-2048.jpg)

![17
2. MCMC(Markov Chain Monte Carlo)について
固定効果の反映例
– 例えばLee Carterモデルln , = + + , にコーホート効果
を反映させてln , = , + , + , などとしたい場合はstanを
使ったMCMCでは尤度の設定部分:
をたとえば以下のように変更すれば対応可能
for (x in 1:41){ //コメント:50歳~90歳
for (t in 1:61){ //コメント:1950年~2010年
mxt <- exp(ax[x]+ bx[x] * kt[t]);
rxt[x,t] ~ binomial(nxt[x,t],mxt);
}
}
for (x in 1:41){ //コメント: 50歳~90歳
for (t in 1:61){ //コメント: 1950年~2010年
mxt <- exp(ax[x,t]+ bx[x,t] * kt[t]);
rxt[x,t] ~ binomial(nxt[x,t],mxt);
}
}
※実際は変数宣言部分等も変更必要のためこの例は手順のイメージと考えてください](https://image.slidesharecdn.com/mlst3teamc10logofreev-140314053652-phpapp02/75/MCMC-18-2048.jpg)
![18
2. MCMC(Markov Chain Monte Carlo)について
ランダム効果の反映例
– 例えばLee CarterモデルにUWの質の差など未観察の要因により平均
を0とするランダム効果!"が加わりln , ," = + !" + + , ," (#
はランダム効果の番号)かつ !"~正規分布(平均 = 0, 標準偏差 =
!%&)などとしたい場合はstanを使ったMCMCではたとえば以下のよ
うにコードを変更すれば対応可能(「階層ベイズ」)
ri ~ normal(0,rdx); //ランダム効果のメタ分布
rdx ~ uniform(0,1.0E3);
for (x in 1:41){ //50歳~90歳
for (t in 1:61){ //1950年~2010年
for (i in 1:10){ //ランダム効果が発生した単位として10区分あり、
//それぞれ効果が独立に発生したとする
mxt <- exp(ax[x]+ri[i]+ bx[x] * kt[t]);
rxt[x,t,i] ~ binomial(nxt[x,t,i],mxt);
}
}
}
※実際は変数宣言部分等も変更必要のためこの例は手順のイメージと考えてください](https://image.slidesharecdn.com/mlst3teamc10logofreev-140314053652-phpapp02/75/MCMC-19-2048.jpg)