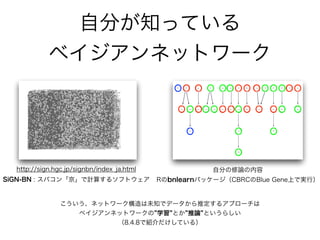
Recommended
PPTX
PDF
PDF
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
PDF
PPTX
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
PPTX
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
PDF
PDF
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ...
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
PDF
PDF
More Related Content
PPTX
PDF
PDF
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
PDF
PPTX
PDF
PDF
What's hot
PDF
PDF
PPTX
PDF
PDF
PPTX
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
PDF
PDF
PDF
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
PDF
感覚運動随伴性、予測符号化、そして自由エネルギー原理 (Sensory-Motor Contingency, Predictive Coding and ...
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
Viewers also liked
PDF
PDF
PDF
ベイジアンネットとレコメンデーション -第5回データマイニング+WEB勉強会@東京
PPTX
PDF
PDF
ベイジアンネットワークモデリング勉強会20140206
PDF
Robustness of classifiers_from_adversarial_to_random_noise
PDF
Generative adversarial nets
PDF
PPTX
[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)
PDF
PDF
Probabilistic Graphical Models 輪読会 #1
PDF
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
PPTX
JSAI2017:敵対的訓練を利用したドメイン不変な表現の学習
PDF
PDF
PDF
PDF
Similar to PRML8章
PDF
PDF
PDF
PPTX
PDF
Infer net wk77_110613-1523
PDF
PDF
PPTX
PDF
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
PDF
20191006 bayesian dl_1_pub
PDF
Prml Reading Group 10 8.3
PDF
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
PPTX
PDF
PPTX
PDF
[PRML] パターン認識と機械学習(第1章:序論)
PDF
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
More from 弘毅 露崎
PDF
大規模テンソルデータに適用可能なeinsumの開発
PDF
バイオインフォ分野におけるtidyなデータ解析の最新動向
PDF
Benchmarking principal component analysis for large-scale single-cell RNA-seq...
PDF
PDF
PDF
PDF
PDF
Predicting drug-induced transcriptome responses of a wide range of human cell...
PDF
LRBase × scTensorで細胞間コミュニケーションの検出
PDF
非負値テンソル分解を用いた細胞間コミュニケーション検出
PDF
Exploring the phenotypic consequences of tissue specific gene expression vari...
PDF
PDF
PDF
Identification of associations between genotypes and longitudinal phenotypes ...
PDF
A novel method for discovering local spatial clusters of genomic regions with...
PDF
PDF
文献注釈情報MeSHを利用した網羅的な遺伝子の機能アノテーションパッケージ
PDF
PDF
PDF
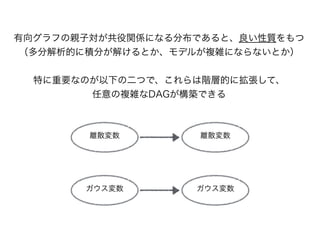
PRML8章 1. 2. 目次
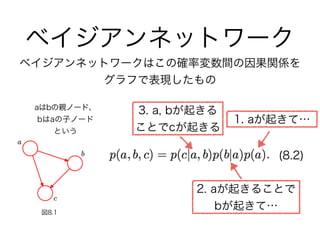
・8.1 ベイジアンネットワーク
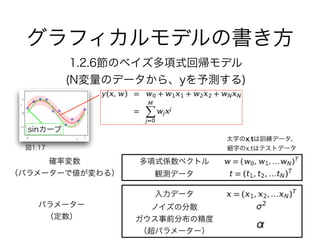
- 8.1.1 例: 多項式曲線フィッティング
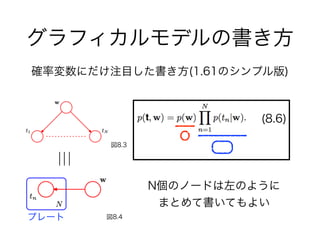
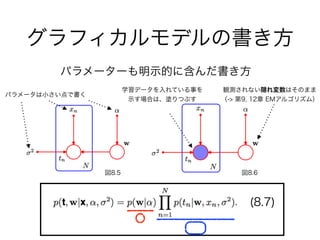
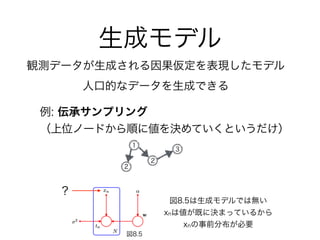
- 8.1.2 生成モデル
- 8.1.3 離散変数
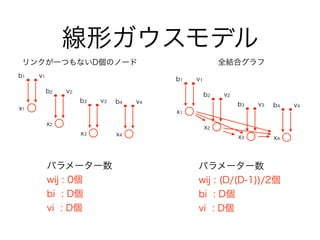
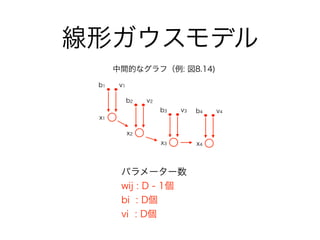
- 8.1.4 線形ガウスモデル
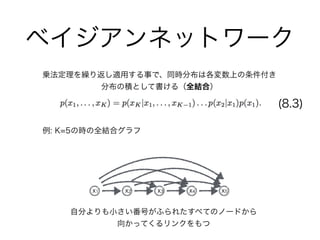
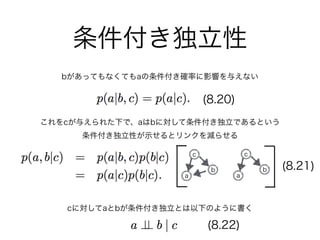
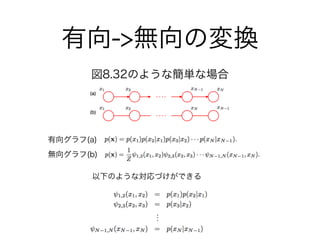
・8.2 条件付き独立性
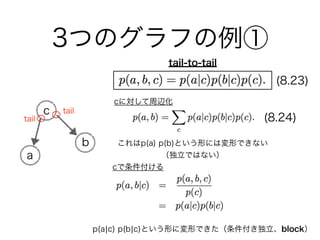
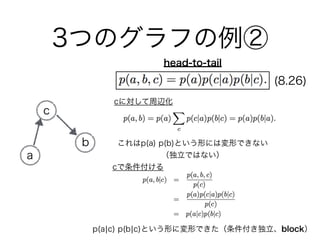
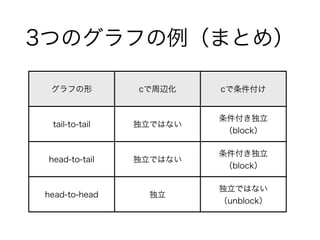
- 8.2.1 3つのグラフの例
- 8.2.2 有向分離(D分離)
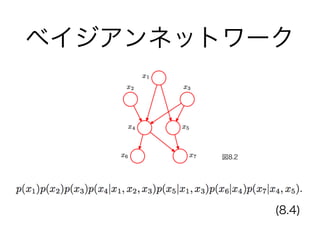
・8.3 マルコフ確率場
- 8.3.1 条件付き独立性
- 8.3.2 分解特性
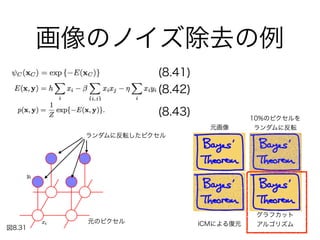
- 8.3.3 例: 画像のノイズ除去
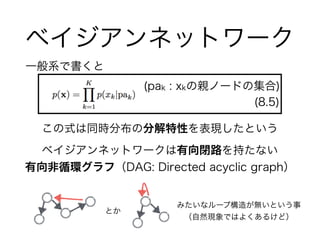
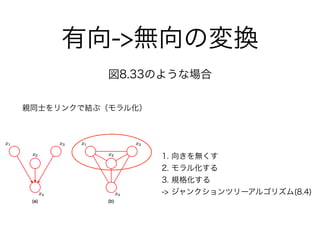
- 8.3.4 有向グラフとの関係
・8.4 グラフィカルモデルにおける推論
- 8.4.1 連鎖における推論
- 8.4.2 木
- 8.4.3 因子グラフ
- 8.4.4 積和アルゴリズム
- 8.4.5 max-sumアルゴリズム
- 8.4.6 一般のグラフにおける厳密推論
- 8.4.7 ループあり確率伝搬
- 8.4.8 グラフ構造の学習
今回 次回or次々回
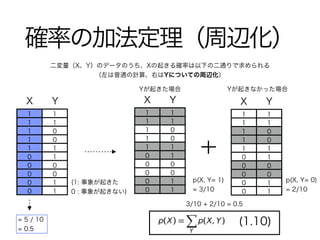
3. 4. 確率の加法定理(周辺化)
(1.10)
1 1
1 1
1 0
1 0
1 1
0 1
0 0
0 0
0 1
0 1
X Y
二変量(X、Y)のデータのうち、Xの起きる確率は以下の二通りで求められる
(左は普通の計算、右はYについての周辺化)
(1: 事象が起きた
0 : 事象が起きない)
= 5 / 10
= 0.5
p(X, Y= 0)
= 2/10
p(X, Y= 1)
= 3/10
3/10 + 2/10 = 0.5
Yが起きた場合
1 1
1 1
1 0
1 0
1 1
0 1
0 0
0 0
0 1
0 1
X Y
Yが起きなかった場合
1 1
1 1
1 0
1 0
1 1
0 1
0 0
0 0
0 1
0 1
X Y
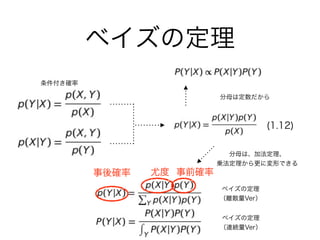
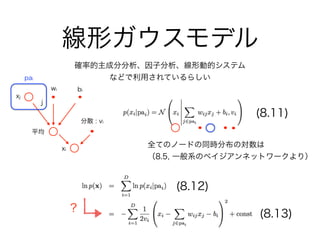
5. 6. 7. 共役事前分布
事後分布 尤度 事前分布
ベータ分布 二項分布 ベータ分布
正規分布 正規分布 正規分布
逆ガンマ分布 正規分布 逆ガンマ分布
ガンマ分布 ポアソン分布 ガンマ分布
ディリクレ分布 多項分布 ディリクレ分布
ベイズな手法は、パラメーターが
分布を持ち、さらにその分布のパ
ラメーターが分布を持ち…という
風に階層を増やしていける
幾らでも階層を作れる
(階層ベイズモデル)
時系列解析に使える
(データ同化)
t t+1 t+2
左のような尤度・事前分布の組み合わせ
は、事後分布が事前分布と同じ形になる
ので、どれだけモデルが複雑になっても、
事後分布を求める事ができる
(積分できる、計算がしやすい)
!
⇄ 最近はモデルが複雑になってもサンプ
リング(MCMC)で分布を求めようとい
うやり方も
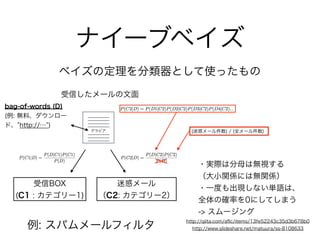
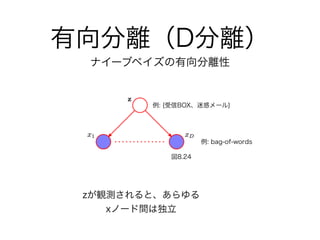
8. 9. 10. ナイーブベイズ
ベイズの定理を分類器として使ったもの
例: スパムメールフィルタ
受信BOX
(C1 : カテゴリー1)
迷惑メール
(C2: カテゴリー2)
受信したメールの文面
グラビア
bag-of-words (D)
(例: 無料、ダウンロー
ド、 http://… )
・実際は分母は無視する
(大小関係には無関係)
・一度も出現しない単語は、
全体の確率を0にしてしまう
-> スムージング
http://qiita.com/aflc/items/13fe52243c35d3b678b0
http://www.slideshare.net/matuura/ss-8108633
(迷惑メール件数) / (全メール件数)
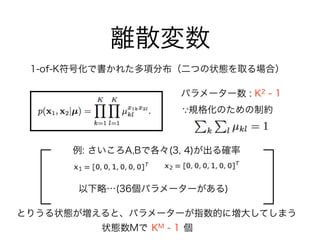
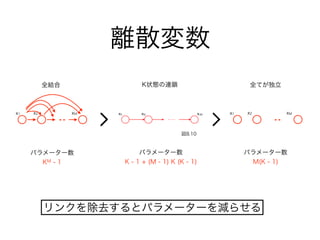
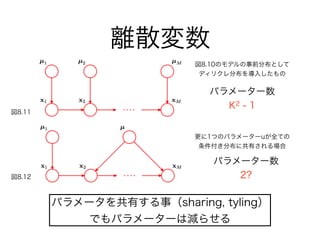
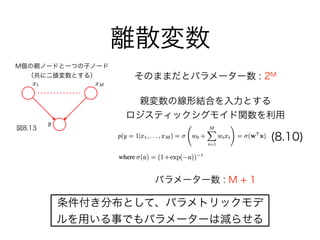
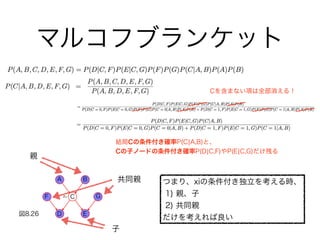
11. 12. 13. 14. 15. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. パラメーター数 : K2 - 1
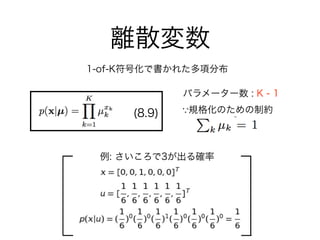
離散変数
1-of-K符号化で書かれた多項分布(二つの状態を取る場合)
規格化のための制約
例: さいころA,Bで各々(3, 4)が出る確率
以下略…(36個パラメーターがある)
とりうる状態が増えると、パラメーターが指数的に増大してしまう
KM - 1状態数Mで 個
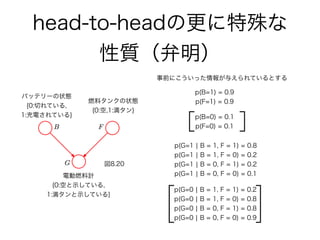
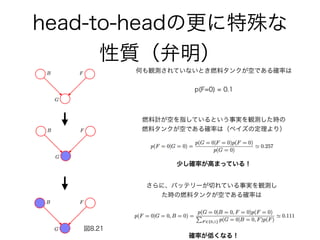
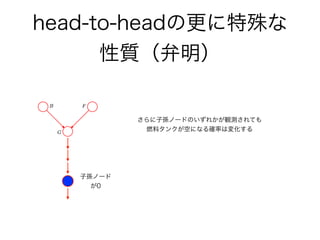
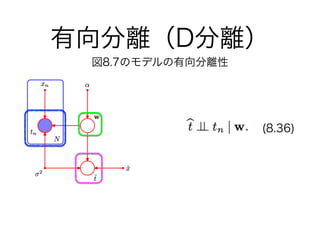
29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. head-to-headの更に特殊な
性質(弁明)
図8.20
バッテリーの状態
{0:切れている,
1:充電されている}
燃料タンクの状態
{0:空,1:満タン}
電動燃料計
{0:空と示している,
1:満タンと示している}
p(B=1) = 0.9
p(F=1) = 0.9
p(G=1 ¦ B = 1, F = 1) = 0.8
p(G=1 ¦ B = 1, F = 0) = 0.2
p(G=1 ¦ B = 0, F = 1) = 0.2
p(G=1 ¦ B = 0, F = 0) = 0.1
p(B=0) = 0.1
p(F=0) = 0.1
p(G=0 ¦ B = 1, F = 1) = 0.2
p(G=0 ¦ B = 1, F = 0) = 0.8
p(G=0 ¦ B = 0, F = 1) = 0.8
p(G=0 ¦ B = 0, F = 0) = 0.9
事前にこういった情報が与えられているとする
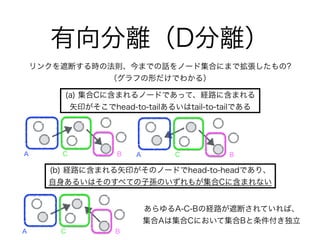
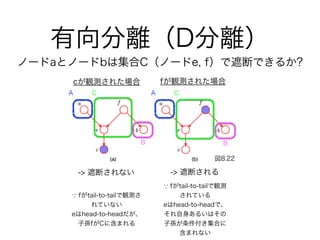
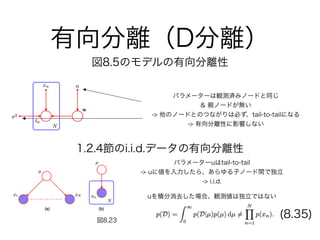
47. 48. 49. 50. 有向分離(D分離)
図8.22
A AC C
B B
ノードaとノードbは集合C(ノードe, f)で遮断できるか?
cが観測された場合 fが観測された場合
-> 遮断されない -> 遮断される
fがtail-to-tailで観測さ
れていない
eはhead-to-headだが、
子孫fがCに含まれる
fがtail-to-tailで観測
されている
eはhead-to-headで、
それ自身あるいはその
子孫が条件付き集合に
含まれない
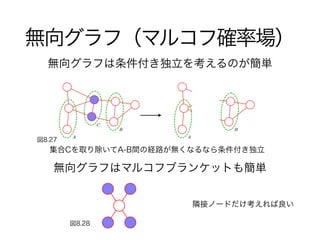
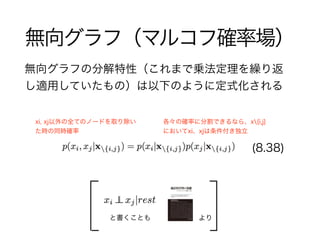
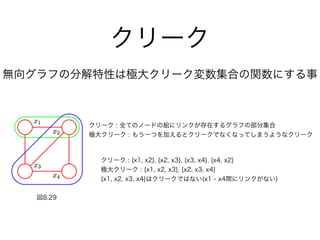
51. 52. 53. 54. 55. 56. 57. 58. 59. クリーク
図8.29
無向グラフの分解特性は極大クリーク変数集合の関数にする事
クリーク : {x1, x2}, {x2, x3}, {x3, x4}, {x4, x2}
極大クリーク : {x1, x2, x3}, {x2, x3, x4}
{x1, x2, x3, x4}はクリークではない(x1 - x4間にリンクがない)
クリーク : 全てのノードの組にリンクが存在するグラフの部分集合
極大クリーク : もう一つを加えるとクリークでなくなってしまうようなクリーク
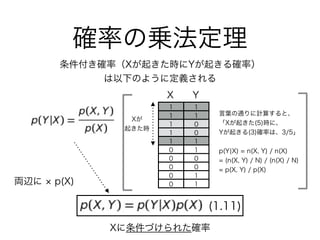
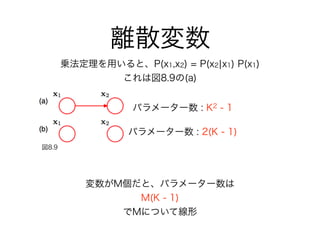
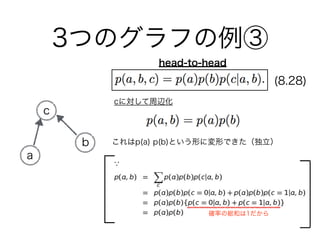
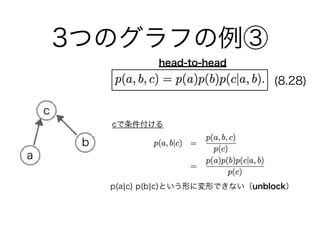
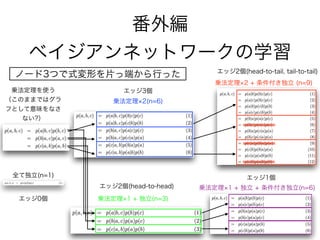
60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 乗法定理 2(n=6)
乗法定理 2 + 条件付き独立 (n=9)
乗法定理 1 + 独立(n=3)
全て独立(n=1)
乗法定理を使う
(このままではグラフ
として表現できない?)
乗法定理 1 + 独立 + 条件付き独立(n=6)
エッジ0個
エッジ1個
エッジ2個(head-to-tail, tail-to-tail)
エッジ2個(head-to-head)
エッジ3個(全結合)
ノード3つで式変形を片っ端から行った
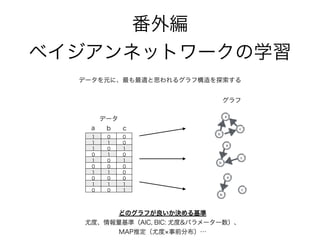
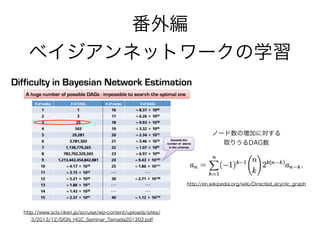
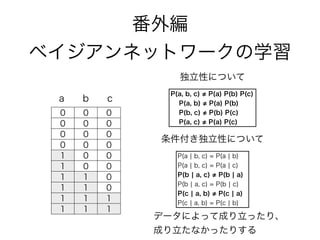
番外編
ベイジアンネットワークの学習
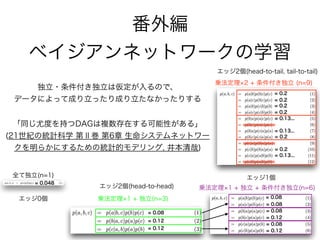
71. 72. 独立性について
番外編
ベイジアンネットワークの学習
0 0 0
0 0 0
0 0 0
0 0 0
1 0 0
1 0 0
1 1 0
1 1 0
1 1 1
1 1 1
a b c
P(a ¦ b, c) = P(a ¦ b)
P(a ¦ b, c) = P(a ¦ c)
P(b ¦ a, c) P(b ¦ a)
P(b ¦ a, c) = P(b ¦ c)
P(c ¦ a, b) P(c ¦ a)
P(c ¦ a, b) = P(c ¦ b)
P(a, b, c) P(a) P(b) P(c)
P(a, b) P(a) P(b)
P(b, c) P(b) P(c)
P(a, c) P(a) P(c)
条件付き独立性について
データによって成り立ったり、
成り立たなかったりする
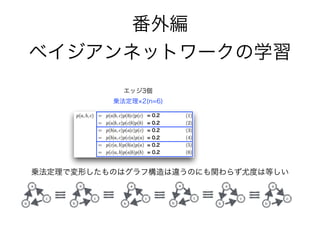
73. 乗法定理 2(n=6)
乗法定理 2 + 条件付き独立 (n=9)
乗法定理 1 + 独立(n=3)
全て独立(n=1)
乗法定理 1 + 独立 + 条件付き独立(n=6)
エッジ0個
エッジ1個
エッジ2個(head-to-tail, tail-to-tail)
エッジ2個(head-to-head)
エッジ3個(全結合)
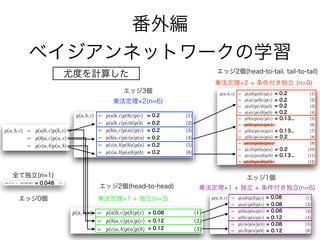
番外編
ベイジアンネットワークの学習
尤度を計算した
= 0.2
= 0.2
= 0.2
= 0.2
= 0.2
= 0.2
= 0.048
= 0.08
= 0.12
= 0.12
= 0.2
= 0.2
= 0.2
= 0.2
= 0.13...
= 0.13...
= 0.2
= 0.2
= 0.13...
= 0.08
= 0.08
= 0.08
= 0.12
= 0.08
= 0.12
74. 75. 乗法定理 2 + 条件付き独立 (n=9)
乗法定理 1 + 独立(n=3)
乗法定理 1 + 独立 + 条件付き独立(n=6)
エッジ0個
エッジ1個
エッジ2個(head-to-tail, tail-to-tail)
エッジ2個(head-to-head)
番外編
ベイジアンネットワークの学習
= 0.08
= 0.12
= 0.12
= 0.2
= 0.2
= 0.2
= 0.2
= 0.13...
= 0.13...
= 0.2
= 0.2
= 0.13...
= 0.08
= 0.08
= 0.08
= 0.12
= 0.08
= 0.12
条件付き独立・独立はデータによって成り立ったり、成り立たなかっ
たりする
!
「同じ尤度を持つDAGは複数存在する可能性がある」
21世紀の統計科学 第2巻 第6章
生命システムネットワークを明らかにするための統計的モデリング


























































![[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/20171121iwasawa-171120061515-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)





















