Recommended
PPTX
[DL輪読会]Pyramid Stereo Matching Network
PPTX
PDF
PDF
PDF
PDF
ODP
PPTX
PPTX
Multi-index法を用いた�リアルタイム波形比較手法の検討(Variance Reduction のレビュー)
PDF
PDF
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
PPTX
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transfo...
PDF
PDF
PDF
object detection with lidar-camera fusion: survey (updated)
PDF
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
PPTX
Devil is in the Edges: �Learning Semantic Boundaries from Noisy Annotations
PDF
PDF
[Ridge-i 論文読み会] ICLR2019における不完全ラベル学習
PDF
Trend of 3D object detections
PDF
第四回 全日本CV勉強会スライド(MOTS: Multi-Object Tracking and Segmentation)
PDF
katagaitai workshop #7 crypto ナップサック暗号と低密度攻撃
PDF
PDF
PDF
PDF
Cache-Oblivious データ構造入門 @DSIRNLP#5
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
ODP
PPTX
More Related Content
PPTX
[DL輪読会]Pyramid Stereo Matching Network
PPTX
PDF
PDF
PDF
PDF
ODP
PPTX
What's hot
PPTX
Multi-index法を用いた�リアルタイム波形比較手法の検討(Variance Reduction のレビュー)
PDF
PDF
ソフト高速化の専門家が教える!AI・IoTエッジデバイスの選び方
PPTX
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transfo...
PDF
PDF
PDF
object detection with lidar-camera fusion: survey (updated)
PDF
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
PPTX
Devil is in the Edges: �Learning Semantic Boundaries from Noisy Annotations
PDF
PDF
[Ridge-i 論文読み会] ICLR2019における不完全ラベル学習
PDF
Trend of 3D object detections
PDF
第四回 全日本CV勉強会スライド(MOTS: Multi-Object Tracking and Segmentation)
PDF
katagaitai workshop #7 crypto ナップサック暗号と低密度攻撃
PDF
PDF
PDF
PDF
Cache-Oblivious データ構造入門 @DSIRNLP#5
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
Viewers also liked
ODP
PPTX
PPTX
Weighting of acoustic cues shifts to frication duration in identification of ...
PDF
PDF
PDF
破擦音生成時の解放に伴う破裂が摩擦音・破擦音識別に与える影響〜若年者と高齢者の比較〜
Similar to ナイーブベイズによる言語判定
PDF
PDF
PDF
PDF
PDF
PDF
言語処理するのに Python でいいの? #PyDataTokyo
PDF
PDF
PDF
PDF
Session2:「グローバル化する情報処理」/伊藤敬彦
PDF
PDF
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
PDF
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PPT
PDF
Introduction of tango! (jp)
More from Shuyo Nakatani
PDF
PDF
Short Text Language Detection with Infinity-Gram
PDF
PDF
Zipf? (ジップ則のひみつ?) #DSIRNLP
PDF
数式を綺麗にプログラミングするコツ #spro2013
PDF
PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
PDF
PDF
Generative adversarial networks
PDF
無限関係モデル (続・わかりやすいパターン認識 13章)
PDF
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
PDF
PDF
PDF
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
PDF
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
PDF
[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems
PDF
Recently uploaded
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
PPTX
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
ナイーブベイズによる言語判定 1. ナイーブベイズによる
言語判定
2010/9/25
中谷 秀洋@サイボウズ・ラボ
id:n_shuyo / @shuyo
2. 3. 言語判定
• 不えられた文書が何語で書かれたものか判定
– 英語/スペイン語/日本語/中国語(繁体・簡体)/アラビア語/……
– 文字コードの判定を同時に行うこともあり(今回は対象外)
• 利用シーン
– 言語の絞り込み付で検索したい
– 言語別のフィルタを適用したい(SPAMフィルタとか)
• Web本文抽出でも言語固有の特徴量を使った
• 利用対象
– Web検索エンジン
• Apache Nutch ではクローラに言語判定モジュールが付属
– 掲示板 グローバル化!
• 例:日英中越入り交じりの書き込み
4. 自分で作らなくちゃダメ?
• 言語判定ライブラリは数少ない
– ニーズが限られている?
• Web検索だけ? でもこれからはグローバル化の時代!
– コーパス/モデルの構築が高コスト
• 対象言語の知識がどうしてもある程度かなり必要
• 対応言語数が少ない。精度が低い
– おおむね10言語程度。アジア系サポートなし
– “Thank you. ありがとうございます”
• → 「タガログ語かチェコ語かスロバキア語です」
5. 6. 既存の言語判定サービス
• Google AJAX Language API
– 短いテキストでも比較的的確に判定&対応言語も多い
– 最も可能性の高い言語を1つだけ返す
– Web API でいい&非商用利用なら鉄板か
• http://code.google.com/intl/lt/apis/ajaxlanguage/documentation/
• http://www.google.com/uds/samples/language/detect.html
• G2LI (Global Information Infrastructure Laboratory's
Language Identifier)
– オンラインデモのみ
• http://gii.nagaokaut.ac.jp:8080/g2liWebHome/index.jsp
• PetaMem Language Identification
– オンラインデモのみ
• http://nlp.petamem.com/eng/nlp/langident.mpl
7. 既存の言語判定ライブラリ
• Lingua::LanguageGuesser
– Perl 実装。60カ国語対応。文字コードもあわせて判定
– 類似度ベースゆえ、評価結果は相対値で得られる
– テキスト分類器の実装 TextCat をベース
• http://gensen.dl.itc.u-tokyo.ac.jp/LanguageGuesser/
• NGramJ
– Java の言語判定ライブラリ。LGPL
– Executable Jar で配布されているので、ダウンロードして即、コマンドラ
インから実行してみることが可能。
– Lingua::LanguageGuesser と同じく TextCat がベース。
– 用意されているプロファイルが少なく、標準で対応している言語や文字
コードが少ない(UTF-8 は対応無し)
• http://ngramj.sourceforge.net/
8. 言語判定の論文 (1)
• [Dunning 1994] Statistical Identification of Language
– 英西の2言語、5万件の学習データで 正解率は 92%(20bytes)、99%(500bytes)
– Markov モデルによる識別。おそらく学習コストがめちゃめちゃ高い。
– 確率的言語識別では多分一番引用数が多い論文。
• [Grefenstette 1995] Comparing two language identification schemes
– 欧文9言語、10~20語の入力で 99%
– 手法は「 Trigram ごとの確率を求め、シーケンスの確率を求めて、一番大きいヤツ」と文章で書
かかれているだけ。
• [Sibun & Reynar 1996] Language identification: Examining the issues
– 欧文18言語で、90%(テストデータ1行)、99%(テストデータ5行) ((注:単位は「行」))
– 各言語の n-gram の確率分布をあらかじめ求めておき、対象とのKLダイバージェンスが一番小
さいものをとる。
• [Cavnar & Trenkle 1994] N-gram-based text categorization
– 欧文8言語、正解率 98~99%(テストデータ 300bytes 前後)。
– N-gram のランキングの類似度による判別。
9. 言語判定の論文 (2)
• [Giguet 1995] Multilingual sentence categorization according to language
– 欧文4言語で error rate は 0.01%
– 方式は「機能語(of とか)が出てきたら、その言語の尤度を増加させる」と書かれているだけ
– テストセットは「集めてきた」と書かれているだけ
• [Poutsma 2001] Applying Monte Carlo Techniques to Language
Identification
– trigramの確率を「加算」して比較。モンテカルロと言いつつ先頭から順に「サンプリング」
• [Martins+ 2005] Language Identification in Web Pages
– 1~5-gram+similarity。欧文12言語で 91%。イタリア語が 80%(スペイン語と間違う)
• [AMINE+ 2010] Automatic Language Identification: An Alternative
Unsupervised Approach Using a New Hybrid Algorithm
– 不えられた「ドキュメントのセット」をクラスタ分類するものであり、未知のドキュメントの言語判別を
するものではない
– 基本 K-means だが、K を不えるのではなく人工蟻コロニーで推定する
10. 11. 12. ナイーブベイズによる文書分類
本当は独立なわけ
• 文書 = ( ) をカテゴリ に分類する問題 ないんだけどね!
– 文書は単語 の集合と見なす(bag-of-words)
• ナイーブベイズ : カテゴリ毎の単語の出現確率を独立とする仮定
– = k (独立の仮定から)
– where ( |) : カテゴリごとの単語の出現率
• 事後確率が最大となる k を文書 のカテゴリと推定する
k k
– k = ∝ (k ) ( |k )
– where (k ) : カテゴリごとの事前情報
• [宣伝] 詳細は gihyo.jp 「機械学習 はじめよう」第2回をご覧ください
– http://gihyo.jp/dev/serial/01/machine-learning/0002
13. ナイーブベイズによる「言語判定」
• 「言語」をカテゴリとした文書分類を行う
– 文書が「英語」に分類されるか、「日本語」に分類されるか判定
• 特徴量に単語ではなく「文字 n-gram」を使う
– 正確には「Unicodeのコードポイント n-gram」 (≠単語/バイト)
– 文字コードが判明していることを前提(特に Unicode とする)
• アプリはテキストの文字コードは把握している
• 文字コード判別が必要なら別途( ICU-4C など)
□T h i s □ 単語の区切りを
表す記号
T h i s ←1-gram
□T Th hi is s□ ←2-gram
□Th Thi his is□ ←3-gram
14. 文字n-gramで言語判定ができる理由
• 各言語には固有の文字や綴り字の規則がある
– アクセント付きの “é” はスペイン語、イタリア語などではよく使われ
るが、英語では原則として用いない
– “Z” で始まる単語はドイツ語には多いが、英語にはほとんど無い
– “C”で始まる単語や “Th” という綴りは英語には多いがドイツ語に
は少ない
• これら特徴に「確率」を設定し、文書全体について累積
□C □L □Z Th
英語 0.75 0.47 0.02 0.74
ドイツ語 0.10 0.37 0.53 0.03
フランス語 0.38 0.69 0.01 0.01
15. 言語判別の流れ
• 学習: 学習コーパスから ( |k ) を求める
– 最尤推定(MLE)なら
の文書内のXi の頻度
=
言語の特徴量数
• 判定: 対象テキストから k を求める
(m) を更新
– テキストから特徴量 を抽出、 k
(m+1) m
– k ∝ k ⋅
– 正規化し、最大確率が閾値(0.99999)を超えたら終了
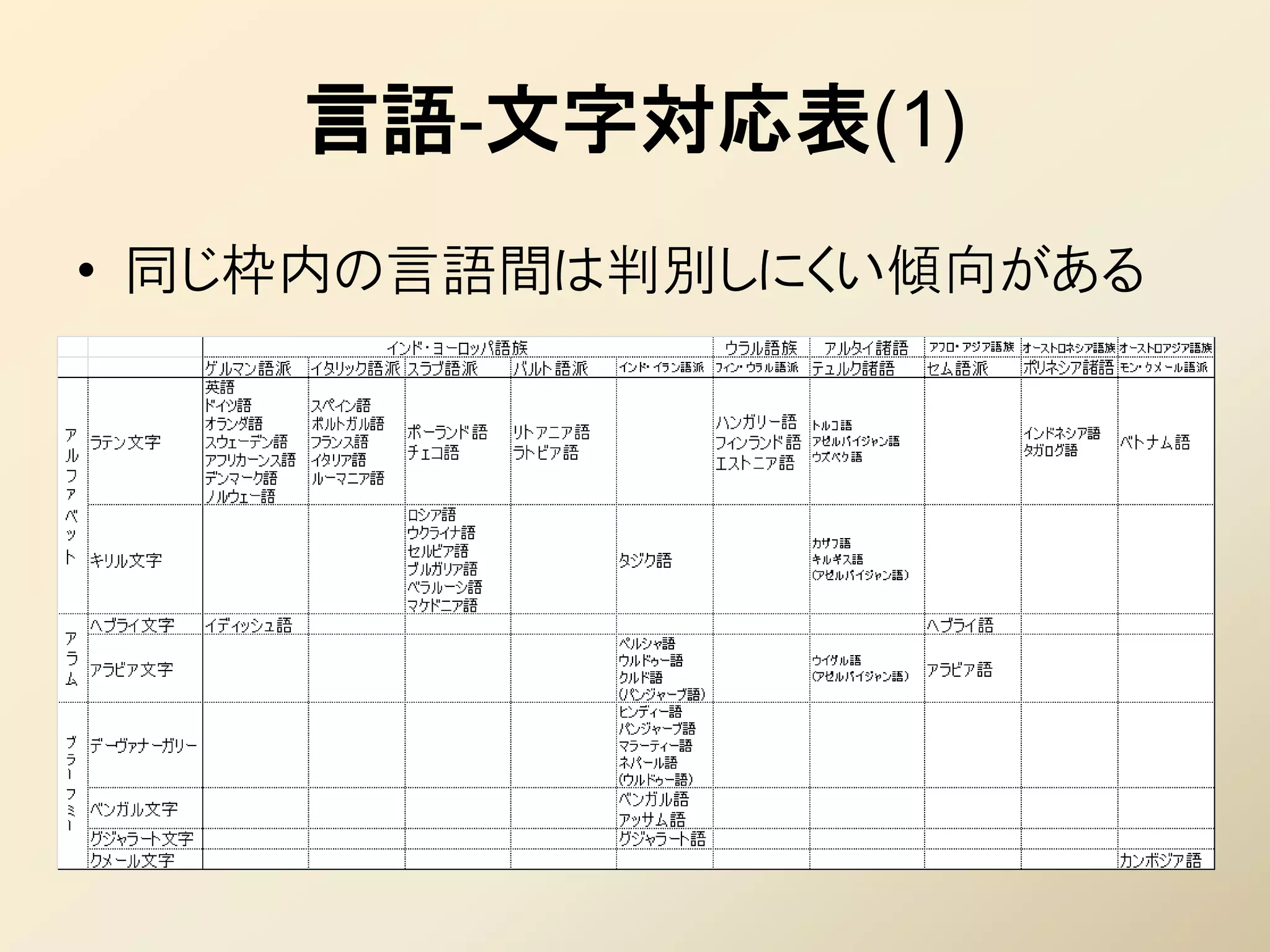
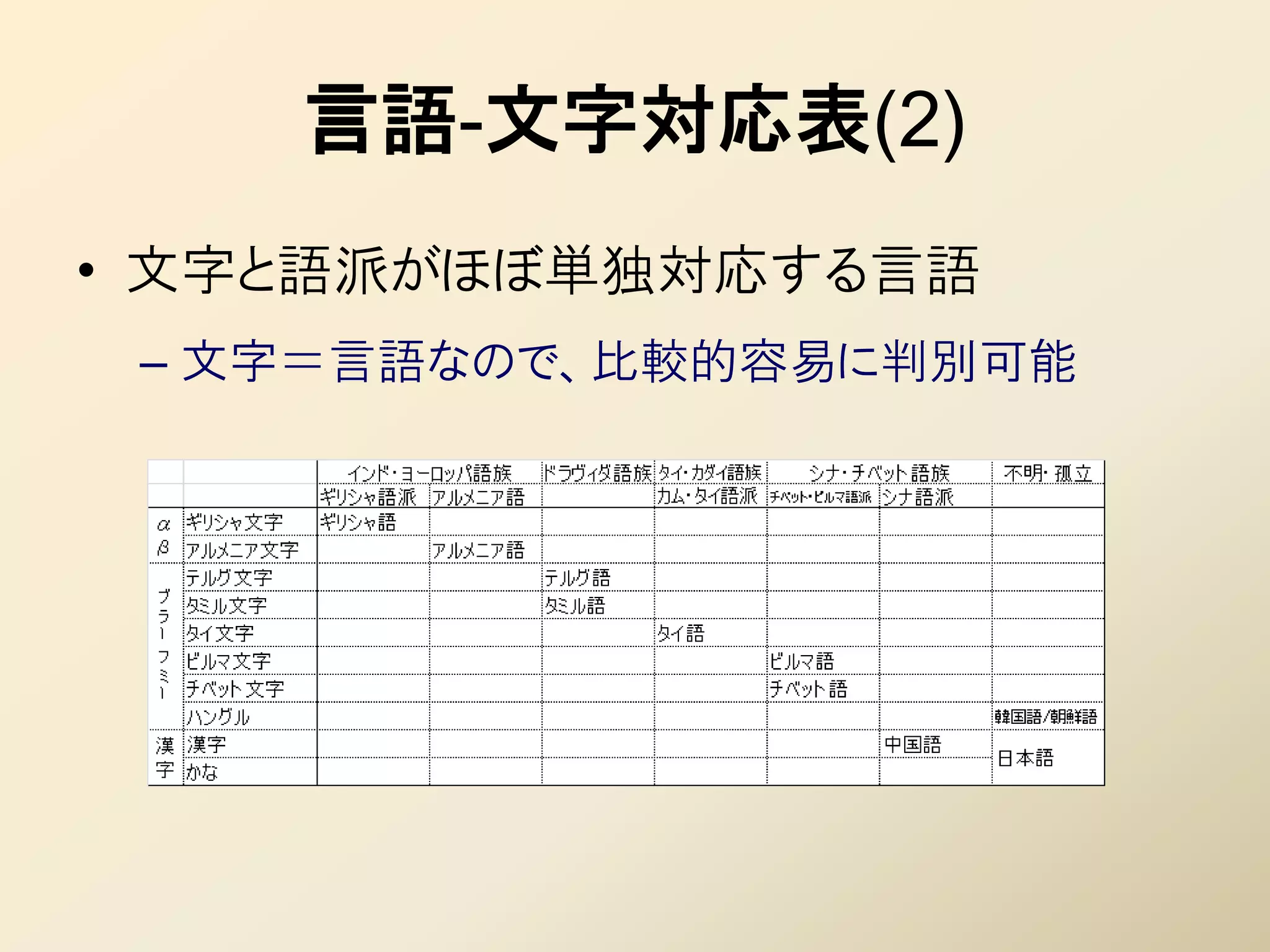
16. 17. 18. 19. 20. 21. 22. Αλφάβητο
• 代表的な文字
– ラテン文字:ローマ・カソリックとともに普及
• アメリカ、ヨーロッパなど、最も多くの国・言語で使われる
• 意外なところではアフリカ諸国、東南アジアにも多い
– 植民地の文字をラテン文字表記に変えさせたり
• アルファベットに存在しない音があれば、付加記号を付
けて文字を増やす(拡張ラテン文字)
– キリル文字: ギリシャ正教とともに普及
• ロシア、東欧を中心に
• 旧・現 社会主義国にも多い(旧ソ連の仕業)
23. アラム文字系
• 中東で普及したアラム文字から派生
これは2文字!
• 主な特徴
– 右から左に続き字で書く
• 続き字の頭・真ん中・お尻で字形が変わる
• 活字より手書きをよしとする(新聞も手書き)
• 慣れないとどこからどこまでが1文字かわからない
ال
– 基本的に子音のみで表記される(「アブジャド」)
• 単語の意味によって母音がわかるので、知らない単語は読めない
• 文字がないせいか、母音が少ない(アラビア語は a/i/u のみ)
• クルアーンや子供向け文章は母音記号付き(「ふりがな」みたい)
– 文字種は 30 前後
• Unicodeでは派生文字(後述)も Arabic ブロックに含むため、コードポイ
ント数は256
24. أبجدية عربية
• 代表的な文字
– アラビア文字: イスラムの文字として普及
• イスラムの聖典クルアーン(コーラン)は「アラビア語のみ」。翻
訳されたものはクルアーンではない
• そのためイスラム圏の諸語では、アラビア文字に数文字加え
た派生文字が使われる傾向(ペルシャ文字、ウルドゥー文字)
– ヘブライ文字:ユダヤ民族の文字
• ヘブライ語:日常語としては一度消滅。20世紀に復活
• 世界各地のユダヤ人が現地の言葉をヘブライ文字で表す
– イディッシュ語 ≒ ドイツ語のヘブライ文字表記
– ジュデズモ語 ≒ スペイン語のヘブライ文字表記
25. 26. देवनागरी
• 代表的な文字
– デーヴァナーガリー: ヒンズー教とともに普及
• ブラーフミー系にしては珍しく複数の言語で使われる(それで
も非常に少ないが)
– 言語固有文字
• 伝播先のインド国内や東南アジアで次々と独自の派生文字
が作られる
• テルグ文字、カンナダ文字、クメール文字、タイ文字、……
– ハングル文字:朝鮮で作られた人造文字
• 合字による音節文字の構成など、パスパ文字を参考に制定
されたと考えられる
27. 漢字系
• 甲骨文字(亀甲獣骨文字)の発展系
• 特徴
– 現行文字としては唯一の表意文字
• 言葉の全く異なる日本語と中国語でも、漢字を使えばある程
度の意思疎通が可能
– 「普通」は逆(口頭は通じるが筆談は×:ヒンディーとウルドゥー)
– 文字種数は数万~数十万と膨大
• 正確な数は「わからない」
• 常用漢字(よく使われる字)というカテゴリーがある(他の文字
にそんなのがあるわけない!)
28. 汉字
• 代表的な文字
– 漢字
• 現在は中国語(簡体字・繁体字)と日本語のみ
• 朝鮮での使用は事実上廃止(CJKなんだけど……)
• ベトナム語(チュノム):漢字を表意・表音の両方で用いるという
独特の体系。現在はラテン文字表記に
– ひらがな、カタカナ:漢字から作られた表音文字
• 現存する言語の中で、日本語は表意文字と表音文字の両方
を使う唯一の言語
• 全く同体系の2種類の表音文字を使い分けるのも日本語だけ
29. 30. 言語判別の流れ(再掲)
• 学習: 学習コーパスから ( |k ) を求める
– 最尤推定(MLE)なら
の文書内のXi の頻度
=
言語の特徴量数
• 判定: 対象テキストから k を求める
(m) を更新
– テキストから特徴量 を抽出、 k
(m+1) m
– k ∝ k ⋅
– 正規化し、最大確率が閾値(0.99999)を超えたら終了
31. 言語判定モジュール(プロトタイプ)
• 学習&判定を Ruby で実装して検証
– 1~3-gram を特徴量として用いる
• 頻度2回以下は足切り
• 4-gram を加えると、精度が低下する(原因未調査)
– 文字の正規化(後述)
– 近似&加算スムージング(手抜き!)
document frequency+
• =
言語のdocument数+V
• パラメータはα=1,2,5,10。確率を正規化してないので大きめ
– http://github.com/shuyo/iir/tree/master/langdetect/
• 学習済みモデルで、言語判定を試せます
$ ruby ./filetest.rb [判定したいファイル]
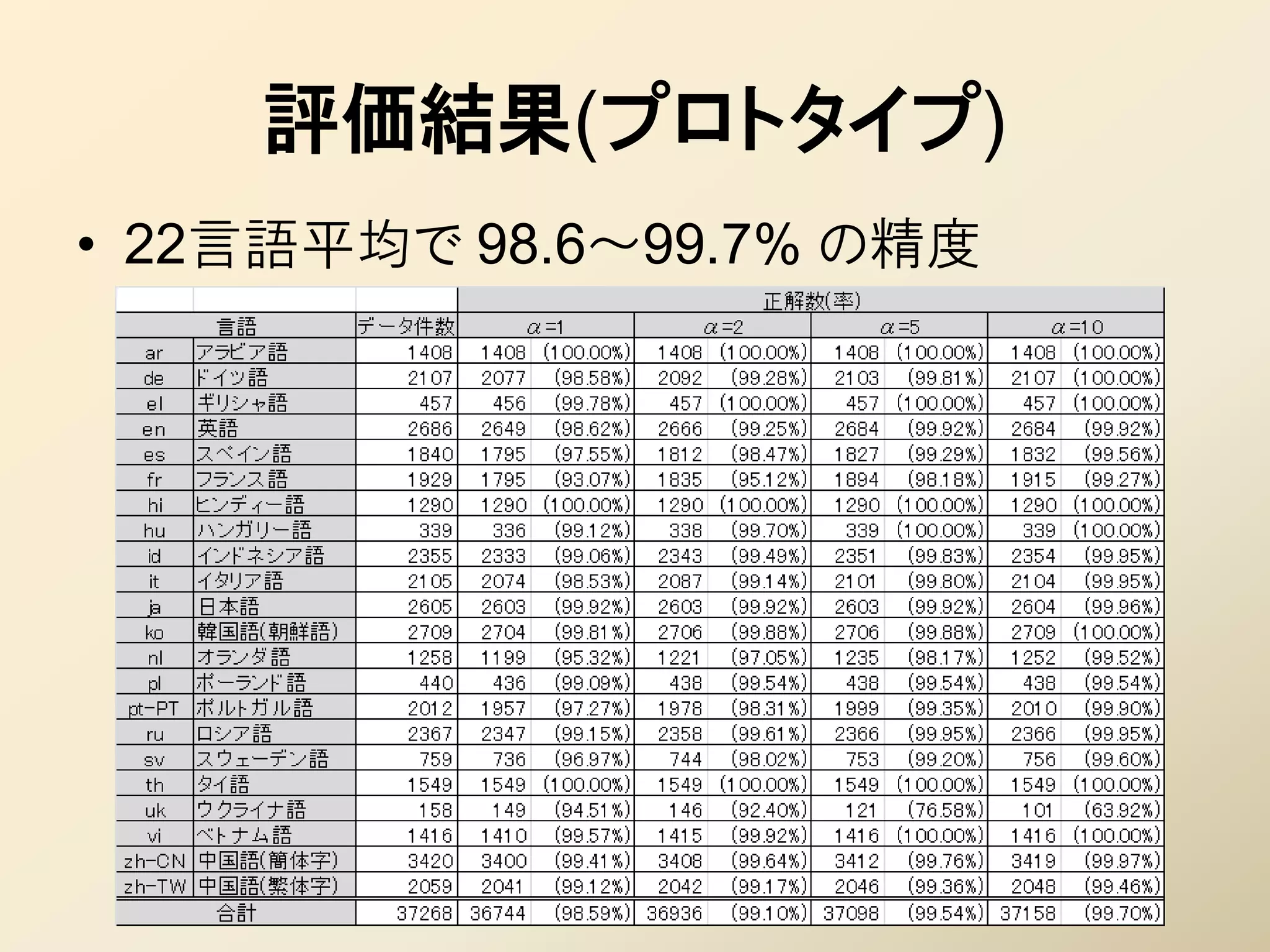
32. 評価(プロトタイプ)
• テスト方法
– コーパス : Google News から22言語
• RSSをクロールして収集
• 学習用 兼 テスト用。学習用はランダムに 300件抽出
• RSSの抜粋なのでデータの粒度(記事の長さ)が揃っている
• ノイズが非常に少ない
• 学習後のモデルサイズ
– JSON形式で出力して 1.2MB
• gzip圧縮して 280KB
33. 34. プロトタイプの問題点
• コーパスに依存した作り
• Google Newsコーパスのpros/cons
– ○データの粒度(記事あたりの長さ)が揃っている
– ○ ノイズが少ない
• 適当にやっても、そこそこいい精度!!
– ○偏りの少ない表現を一箇所から拾える
• ソースが複数ニュースサイト
– ×未提供言語に対応できない(ペルシャ語などなど)
– ×まとまった量の入手に手間&時間がかかる
– ×コーパスを配布できない
35. 36. 言語判定ライブラリ for Java
• オープンソースとして公開(Apache License 2.0)
– http://code.google.com/p/language-detection/
• プロトタイプ+コーパス変更
– 学習コーパスに Wikipedia の abstract データベース
ファイルを採用
• Wikipedia は 273 言語に展開(2010/09 現在)
– 特徴量に Jefferys-Peaks (ELE)
の文書内のXi の頻度+
• = , where = 0.5
言語 の特徴量数+V
• > 10−4 で足切り
37. 38. (1) 学習コーパスのノイズ
• Wikipedia Abstract Database は意外とノイズだらけ
– abstract = 先頭1段落の抜粋
• 他言語での名称表記
– 由来となる言語での正式名を併記。n-gram に他言語のも
のが混ざる
– → 足切りで極力除外
• スタイル情報などの残留
– 本来、独自タグで囲まれているのだが、Abstract
Database ではタグのみ消えている(!!?)
– → 正規表現などで引っかけて、少しでも減らす
39. (2) 学習コーパスの不均一性
• 言語によって記事件数に大きな隔たり
– 英語:340万件, イタリア語:72万件
– デンマーク語:13万件, ソマリ語: 1400件
– 特徴量の分母が異なるため、discount 項の効き
方が言語によって異なってしまう
の文書内のXi の頻度+
• = , where = 0.5
言語の特徴量数+V
– → 頻度の平均を用いて、分母を統一
40. (3) 文字種の偏り
• 漢字:文字種が他言語の1000倍!
• コーパスに出現しない文字
– Wikipedia で「谢」は使われない→ 「谢谢」が判定できない
– 日本人の人名漢字も同様
– → 文字の正規化時に「常用漢字」を考慮(後述)
• 日本語と繁体字の誤判定問題
– 確率を正規化すると、文字種が多い⇒確率小
• 共通文字について、文字種の多い言語が丌利
• アルファベットが混じっていると、負ける → ラテン文字ノイズ参照
– 漢字はかなり共通+日本語にはひらがな&カタカナ
• 漢字の日本語確率が下がりすぎ、繁体字判定されがち
– → 文字の正規化で解決(後述)
41. (4) 判定テキストのノイズ
• 言語に依存しない文字 → 単純に除去
– URL やメールアドレス
– 数字や記号(¥x21-¥x40, General Punctuation)
• ラテン文字ノイズ in 非ラテン文字
– 非ラテン文字の中にも頻繁に出現
• ある意味世界共通文字。でも精度低下の大きな要因
– → ラテン文字が2割以下なら除去
• ラテン文字ノイズ in ラテン文字
– 略字、人名は言語の特徴を表さない
• 特に人名はむしろ他の言語の特徴をもつことも
– → 全て大文字の単語は除去
– → 特徴サンプリングして、人名などの局所的な特徴の影響を低減
42. 文字の正規化
• 文字を(言語判定の観点で)統一されたものに置き換え
– 学習時・判定時の両方で行う
• そもそもなぜ正規化が必要?
– ノイズ除去
• 言語に依存しない記号・アラビア数字(しかも高頻度)
– sparseness の解消
• 特に文字セットが巨大な場合に重要(後述)
– モデルの圧縮
• 判定時のメモリ・速度が有利に
• 文字の正規化が最も困難(要:言語の知識)
43. 文字の正規化(基本)
• “stop character” の除外
– 数字や記号(¥x21-¥x40, General Punctuation 等)
• 特定の言語に対応する文字種の正規化
– 文字の「綴り」を言語判定に使う必要がない
– 文字種全体を代表となる1文字にまとめる
• モデルの圧縮に効果大
– ひらがな・カタカナ、特にハングル!
• 頻度は小さいが、言語判定の決め手となる文字
– ハングルの注音字母
44. 文字の正規化(CJK漢字) (1)
• CJK漢字特有の問題
– 学習コーパスに「たまたま出現しない文字」
• 例: 「谢谢」、人名漢字
• 解決案:「頻度が似ている漢字」でグルーピングし、それぞれ代表文
字に正規化
• ★よく使われる文字をできるだけカバーするクラスタを作る
– 高頻度の共通文字で「負けている」と常に負ける
• 例:「的」
– 日本語、簡体字、繁体字で共通に使用。
– 日本語はひらがなカタカナもあるため、漢字の確率は低い
– 「的」を含むグループの確率の差のせいで、繁体字に判定されやすい
• ★できるだけ細かいクラスタを作りたい
45. 文字の正規化(CJK漢字) (2)
• 大きすぎず、小さすぎない漢字クラスタを作る
– (1) K-meansによるクラスタ分類
• Wikipedia および Google News での tf-idf を特徴量とする
– 頻度をそのまま用いるよりはるかによい結果になる
• K=50 (アルファベットの個数 52 に合わせた)
– (2) 「常用漢字」による分類
• 簡体字: 现代汉语常用字表(3500字)
• 繁体字: Big5第1水準(5401字、「常用国字標準字体表」4808字を含む)
• 日本語: 常用漢字(2136字)+ JIS 第1水準(2965字) = 2998字
– 常用漢字だけでは、氏名や地名の漢字がほとんど入っていないため
– K-means のクラスタおよび、各「常用漢字」で集合積をとり、130のク
ラスタを作成
• +手動による補正……
46. 文字の正規化(アラビア文字)
• 問題発生:ペルシャ語の判別が全滅(全てアラビア語に!!)
– 同じアラビア文字だが語派が全く違う→判別は容易なはず
• 原因:高頻度で使われる yeh のコードが異なる
– 学習コーパス(Wikipedia)では ¥( یu06cc, Farsi yeh) が(正しく)
使われている
– テストコーパス(Google News)では ¥(يu064a, Arabic yeh)
• 推測:アラビア語の文字コード CP-1256 には ¥u06cc にマッピングされ
る文字がないため、¥u064aで代用する手法が現場で定着している?
• 対策: ¥u06cc を ¥u064a に正規化
ペルシア語ではye( )یの独立形・右接形には識別点を付けないが,付けているものをよく見かけ
る。これはアラビア語キーボードでペルシア語を入力したときによく起こる問題である。また,OS
やブラウザーなどの環境によってはこの文字が正しく出ないため,ウェブでは確信犯的にアラビ
ア語のyā’( )يを使っていることが多い。
「アラビア語系文字の基礎知識」より
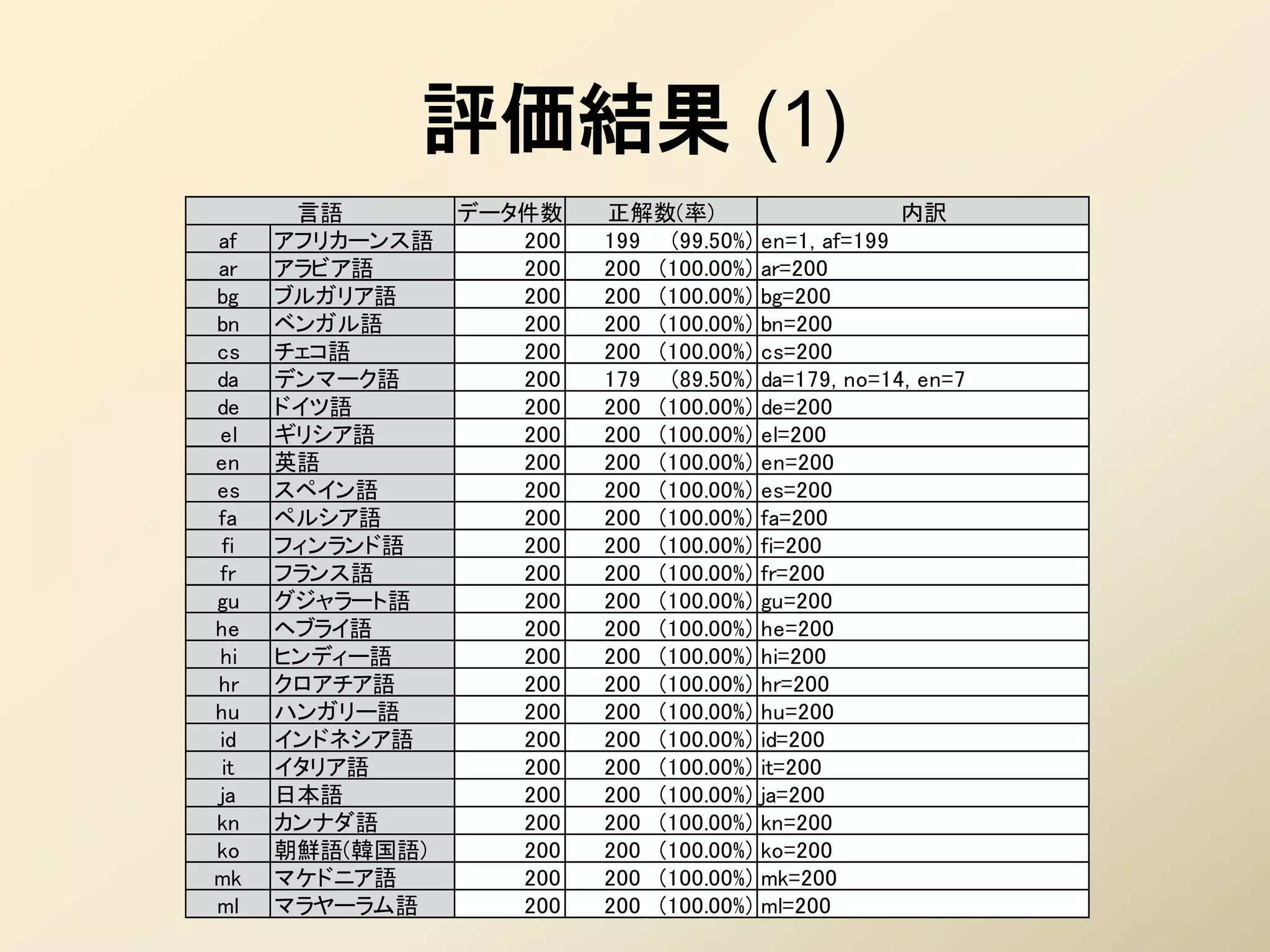
47. 48. 評価
• 学習
– 対象言語数: 49言語
• Wikipedia にはもっと言語多いのでは?
– テストデータが用意できるもの
– 似すぎていて判別できないものを対象外
• 各言語プロファイルのサイズは30KB前後(JSON)
• テスト
– コーパス:Google News + 様々なニュースサイトの RSS
• マイナーな言語は RSS を配信しているニュースサイトを見つけるだ
けでも大変……
– 各言語ごとにランダムに 200件抽出
49. 評価結果 (1)
言語 データ件数 正解数(率) 内訳
af アフリカーンス語 200 199 (99.50%) en=1, af=199
ar アラビア語 200 200 (100.00%) ar=200
bg ブルガリア語 200 200 (100.00%) bg=200
bn ベンガル語 200 200 (100.00%) bn=200
cs チェコ語 200 200 (100.00%) cs=200
da デンマーク語 200 179 (89.50%) da=179, no=14, en=7
de ドイツ語 200 200 (100.00%) de=200
el ギリシア語 200 200 (100.00%) el=200
en 英語 200 200 (100.00%) en=200
es スペイン語 200 200 (100.00%) es=200
fa ペルシア語 200 200 (100.00%) fa=200
fi フィンランド語 200 200 (100.00%) fi=200
fr フランス語 200 200 (100.00%) fr=200
gu グジャラート語 200 200 (100.00%) gu=200
he ヘブライ語 200 200 (100.00%) he=200
hi ヒンディー語 200 200 (100.00%) hi=200
hr クロアチア語 200 200 (100.00%) hr=200
hu ハンガリー語 200 200 (100.00%) hu=200
id インドネシア語 200 200 (100.00%) id=200
it イタリア語 200 200 (100.00%) it=200
ja 日本語 200 200 (100.00%) ja=200
kn カンナダ語 200 200 (100.00%) kn=200
ko 朝鮮語(韓国語) 200 200 (100.00%) ko=200
mk マケドニア語 200 200 (100.00%) mk=200
ml マラヤーラム語 200 200 (100.00%) ml=200
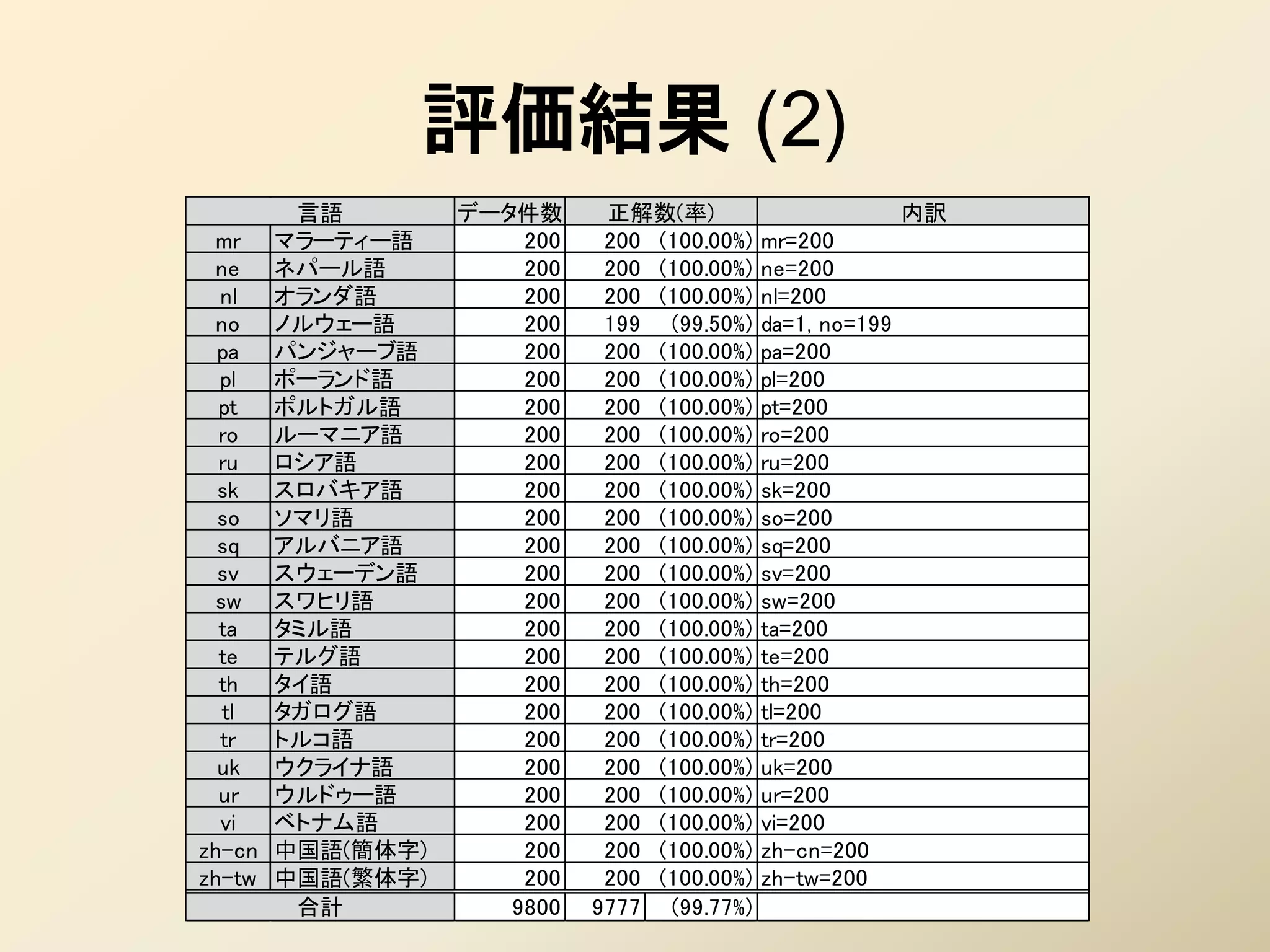
50. 評価結果 (2)
言語 データ件数 正解数(率) 内訳
mr マラーティー語 200 200 (100.00%) mr=200
ne ネパール語 200 200 (100.00%) ne=200
nl オランダ語 200 200 (100.00%) nl=200
no ノルウェー語 200 199 (99.50%) da=1, no=199
pa パンジャーブ語 200 200 (100.00%) pa=200
pl ポーランド語 200 200 (100.00%) pl=200
pt ポルトガル語 200 200 (100.00%) pt=200
ro ルーマニア語 200 200 (100.00%) ro=200
ru ロシア語 200 200 (100.00%) ru=200
sk スロバキア語 200 200 (100.00%) sk=200
so ソマリ語 200 200 (100.00%) so=200
sq アルバニア語 200 200 (100.00%) sq=200
sv スウェーデン語 200 200 (100.00%) sv=200
sw スワヒリ語 200 200 (100.00%) sw=200
ta タミル語 200 200 (100.00%) ta=200
te テルグ語 200 200 (100.00%) te=200
th タイ語 200 200 (100.00%) th=200
tl タガログ語 200 200 (100.00%) tl=200
tr トルコ語 200 200 (100.00%) tr=200
uk ウクライナ語 200 200 (100.00%) uk=200
ur ウルドゥー語 200 200 (100.00%) ur=200
vi ベトナム語 200 200 (100.00%) vi=200
zh-cn 中国語(簡体字) 200 200 (100.00%) zh-cn=200
zh-tw 中国語(繁体字) 200 200 (100.00%) zh-tw=200
合計 9800 9777 (99.77%)
51. 52. まとめ
• 99.8% で 49言語の判定可能な言語判定ライブ
ラリを開発
– オープンソース
• http://code.google.com/p/language-detection/
– ドキュメントは鋭意整備中……
• 90%までは簡単。でも実用レベルは99.*%~
– 理想:美しい理論で一発解答
– 現実:どこまでも泥臭い工夫の固まり
• 文字かわいいよ
53. 54. 参考文献
• 千野栄一編「世界のことば100語辞典 ヨーロッ
パ編」
• 町田和彦編「図説 世界の文字とことば」
• 世界の文字研究会「世界の文字の図典」
• 町田和彦「ニューエクスプレス ヒンディー語」
• 中村公則「らくらくペルシャ語 文法から会話」
• 道広勇司「アラビア系文字の基礎知識」
– http://moji.gr.jp/script/arabic/article01.html







![言語判定の論文 (1)
• [Dunning 1994] Statistical Identification of Language
– 英西の2言語、5万件の学習データで 正解率は 92%(20bytes)、99%(500bytes)
– Markov モデルによる識別。おそらく学習コストがめちゃめちゃ高い。
– 確率的言語識別では多分一番引用数が多い論文。
• [Grefenstette 1995] Comparing two language identification schemes
– 欧文9言語、10~20語の入力で 99%
– 手法は「 Trigram ごとの確率を求め、シーケンスの確率を求めて、一番大きいヤツ」と文章で書
かかれているだけ。
• [Sibun & Reynar 1996] Language identification: Examining the issues
– 欧文18言語で、90%(テストデータ1行)、99%(テストデータ5行) ((注:単位は「行」))
– 各言語の n-gram の確率分布をあらかじめ求めておき、対象とのKLダイバージェンスが一番小
さいものをとる。
• [Cavnar & Trenkle 1994] N-gram-based text categorization
– 欧文8言語、正解率 98~99%(テストデータ 300bytes 前後)。
– N-gram のランキングの類似度による判別。](https://image.slidesharecdn.com/langdetect-100925074057-phpapp02/75/slide-8-2048.jpg)
![言語判定の論文 (2)
• [Giguet 1995] Multilingual sentence categorization according to language
– 欧文4言語で error rate は 0.01%
– 方式は「機能語(of とか)が出てきたら、その言語の尤度を増加させる」と書かれているだけ
– テストセットは「集めてきた」と書かれているだけ
• [Poutsma 2001] Applying Monte Carlo Techniques to Language
Identification
– trigramの確率を「加算」して比較。モンテカルロと言いつつ先頭から順に「サンプリング」
• [Martins+ 2005] Language Identification in Web Pages
– 1~5-gram+similarity。欧文12言語で 91%。イタリア語が 80%(スペイン語と間違う)
• [AMINE+ 2010] Automatic Language Identification: An Alternative
Unsupervised Approach Using a New Hybrid Algorithm
– 不えられた「ドキュメントのセット」をクラスタ分類するものであり、未知のドキュメントの言語判別を
するものではない
– 基本 K-means だが、K を不えるのではなく人工蟻コロニーで推定する](https://image.slidesharecdn.com/langdetect-100925074057-phpapp02/75/slide-9-2048.jpg)


![ナイーブベイズによる文書分類
本当は独立なわけ
• 文書 = ( ) をカテゴリ に分類する問題 ないんだけどね!
– 文書は単語 の集合と見なす(bag-of-words)
• ナイーブベイズ : カテゴリ毎の単語の出現確率を独立とする仮定
– = k (独立の仮定から)
– where ( |) : カテゴリごとの単語の出現率
• 事後確率が最大となる k を文書 のカテゴリと推定する
k k
– k = ∝ (k ) ( |k )
– where (k ) : カテゴリごとの事前情報
• [宣伝] 詳細は gihyo.jp 「機械学習 はじめよう」第2回をご覧ください
– http://gihyo.jp/dev/serial/01/machine-learning/0002](https://image.slidesharecdn.com/langdetect-100925074057-phpapp02/75/slide-12-2048.jpg)
















![言語判定モジュール(プロトタイプ)
• 学習&判定を Ruby で実装して検証
– 1~3-gram を特徴量として用いる
• 頻度2回以下は足切り
• 4-gram を加えると、精度が低下する(原因未調査)
– 文字の正規化(後述)
– 近似&加算スムージング(手抜き!)
document frequency+
• =
言語のdocument数+V
• パラメータはα=1,2,5,10。確率を正規化してないので大きめ
– http://github.com/shuyo/iir/tree/master/langdetect/
• 学習済みモデルで、言語判定を試せます
$ ruby ./filetest.rb [判定したいファイル]](https://image.slidesharecdn.com/langdetect-100925074057-phpapp02/75/slide-31-2048.jpg)




















![[DL輪読会]Pyramid Stereo Matching Network](https://cdn.slidesharecdn.com/ss_thumbnails/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Ridge-i 論文読み会] ICLR2019における不完全ラベル学習](https://cdn.slidesharecdn.com/ss_thumbnails/yomikaiiclr2019-190510070433-thumbnail.jpg?width=640&height=640&fit=bounds)















































![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems](https://cdn.slidesharecdn.com/ss_thumbnails/karger-croudsourcing-nips11-120408005300-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






