Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
hoxo_m
14,230 views
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
トピックモデルの評価指標 Coherence 研究まとめ
Data & Analytics
◦
Read more
30
Save
Share
Embed
Embed presentation
1
/ 69
2
/ 69
3
/ 69
4
/ 69
5
/ 69
6
/ 69
7
/ 69
8
/ 69
9
/ 69
10
/ 69
11
/ 69
12
/ 69
13
/ 69
14
/ 69
15
/ 69
16
/ 69
17
/ 69
18
/ 69
19
/ 69
20
/ 69
21
/ 69
22
/ 69
23
/ 69
24
/ 69
25
/ 69
26
/ 69
27
/ 69
Most read
28
/ 69
29
/ 69
30
/ 69
31
/ 69
32
/ 69
33
/ 69
34
/ 69
35
/ 69
36
/ 69
37
/ 69
38
/ 69
39
/ 69
40
/ 69
41
/ 69
42
/ 69
43
/ 69
44
/ 69
45
/ 69
46
/ 69
Most read
47
/ 69
48
/ 69
49
/ 69
50
/ 69
51
/ 69
52
/ 69
53
/ 69
54
/ 69
55
/ 69
56
/ 69
57
/ 69
Most read
58
/ 69
59
/ 69
60
/ 69
61
/ 69
62
/ 69
63
/ 69
64
/ 69
65
/ 69
66
/ 69
67
/ 69
68
/ 69
69
/ 69
More Related Content
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
PDF
最適輸送の解き方
by
joisino
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Active Learning 入門
by
Shuyo Nakatani
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
最適輸送の解き方
by
joisino
What's hot
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PPTX
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
PPTX
Zotero紹介
by
Takara Ishimoto
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PDF
最適輸送入門
by
joisino
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PDF
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
ベイズモデリングと仲良くするために
by
Shushi Namba
PPTX
トピックモデルの基礎と応用
by
Tomonari Masada
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
Zotero紹介
by
Takara Ishimoto
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
Attentionの基礎からTransformerの入門まで
by
AGIRobots
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
最適輸送入門
by
joisino
ベイズ統計学の概論的紹介
by
Naoki Hayashi
機械学習モデルのハイパパラメータ最適化
by
gree_tech
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
変分ベイズ法の説明
by
Haruka Ozaki
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
Stanコードの書き方 中級編
by
Hiroshi Shimizu
ベイズ統計入門
by
Miyoshi Yuya
ベイズモデリングと仲良くするために
by
Shushi Namba
トピックモデルの基礎と応用
by
Tomonari Masada
Viewers also liked
PDF
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
PDF
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
3.3節 変分近似法(前半)
by
tn1031
PDF
「トピックモデルによる統計的潜在意味解析」読書会「第1章 統計的潜在意味解析とは」
by
ksmzn
PDF
トピックモデルによる統計的潜在意味解析 2章後半
by
Shinya Akiba
PDF
LDA等のトピックモデル
by
Mathieu Bertin
PDF
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
PPTX
20150730 トピ本第4回 3.4節
by
MOTOGRILL
PDF
協調フィルタリング入門
by
hoxo_m
PDF
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
PDF
確率論基礎
by
hoxo_m
PDF
日英機械翻訳のための構文辞書
by
Kanji Takahashi
PPT
自動翻訳ツールの概要と応用(ネットショップ向け)
by
fengruoyouqing
PPTX
A survery of topic model in bioinformatics
by
Tsukasa Fukunaga
PDF
Wsdm2016: Extracting Search Query Patterns via the Pairwise Coupled Topic Model
by
Mitsuhisa Ohta
PDF
変分法
by
弘毅 露崎
PPTX
PFI seminar 2010/05/27 統計的機械翻訳
by
Preferred Networks
PPT
Twitterテキストのトピック分析
by
Nobuyuki Kawagashira
PPTX
トピックモデル(LDA)によるセグメンテーション
by
businessanalytics
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
by
hoxo_m
「トピックモデルによる統計的潜在意味解析」読書会 2章前半
by
koba cky
階層モデルの分散パラメータの事前分布について
by
hoxo_m
3.3節 変分近似法(前半)
by
tn1031
「トピックモデルによる統計的潜在意味解析」読書会「第1章 統計的潜在意味解析とは」
by
ksmzn
トピックモデルによる統計的潜在意味解析 2章後半
by
Shinya Akiba
LDA等のトピックモデル
by
Mathieu Bertin
データの不備を統計的に見抜く (Gelman’s secret weapon)
by
hoxo_m
20150730 トピ本第4回 3.4節
by
MOTOGRILL
協調フィルタリング入門
by
hoxo_m
シンギュラリティを知らずに機械学習を語るな
by
hoxo_m
確率論基礎
by
hoxo_m
日英機械翻訳のための構文辞書
by
Kanji Takahashi
自動翻訳ツールの概要と応用(ネットショップ向け)
by
fengruoyouqing
A survery of topic model in bioinformatics
by
Tsukasa Fukunaga
Wsdm2016: Extracting Search Query Patterns via the Pairwise Coupled Topic Model
by
Mitsuhisa Ohta
変分法
by
弘毅 露崎
PFI seminar 2010/05/27 統計的機械翻訳
by
Preferred Networks
Twitterテキストのトピック分析
by
Nobuyuki Kawagashira
トピックモデル(LDA)によるセグメンテーション
by
businessanalytics
Similar to トピックモデルの評価指標 Coherence 研究まとめ #トピ本
PDF
言語資源と付き合う
by
Yuya Unno
PPTX
Coling読み会スライド
by
lkjjkl
PPTX
対話テキストの自動要約
by
Masahiro Yamamoto
PDF
読解支援プレゼン 4 28
by
kentshioda
PPTX
発話自動採点システムの研究と開発
by
早稲田大学
PDF
文献紹介:Extracting Opinion Expression with semi-Markov Conditional Random Fields
by
Shohei Okada
PDF
研究論文の書き方 - How to write a scientific paper
by
Antonio Tejero de Pablos
PDF
人間との協調を学ぶ人工知能 岩橋直人 Artificial intelligence that learns to cooperate with huma...
by
KIT Cognitive Interaction Design
PDF
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
PDF
機関リポジトリから収集した学術論文のテキスト解析に関する一検討
by
Okamoto Laboratory, The University of Electro-Communications
PDF
Interspeech2022 参加報告
by
Yuki Saito
PDF
キーワード推定を内包したオーディオキャプション法
by
Yuma Koizumi
言語資源と付き合う
by
Yuya Unno
Coling読み会スライド
by
lkjjkl
対話テキストの自動要約
by
Masahiro Yamamoto
読解支援プレゼン 4 28
by
kentshioda
発話自動採点システムの研究と開発
by
早稲田大学
文献紹介:Extracting Opinion Expression with semi-Markov Conditional Random Fields
by
Shohei Okada
研究論文の書き方 - How to write a scientific paper
by
Antonio Tejero de Pablos
人間との協調を学ぶ人工知能 岩橋直人 Artificial intelligence that learns to cooperate with huma...
by
KIT Cognitive Interaction Design
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
機関リポジトリから収集した学術論文のテキスト解析に関する一検討
by
Okamoto Laboratory, The University of Electro-Communications
Interspeech2022 参加報告
by
Yuki Saito
キーワード推定を内包したオーディオキャプション法
by
Yuma Koizumi
More from hoxo_m
PDF
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PDF
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
学習係数
by
hoxo_m
PDF
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
PDF
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
PPTX
高速なガンマ分布の最尤推定法について
by
hoxo_m
PDF
経験過程
by
hoxo_m
PDF
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
PDF
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
PDF
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
PDF
チェビシェフの不等式
by
hoxo_m
PDF
swirl パッケージでインタラクティブ学習
by
hoxo_m
PPTX
RPubs とその Bot たち
by
hoxo_m
PPTX
5分でわかるベイズ確率
by
hoxo_m
Shinyユーザのための非同期プログラミング入門
by
hoxo_m
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
Prophet入門【R編】Facebookの時系列予測ツール
by
hoxo_m
機械学習のためのベイズ最適化入門
by
hoxo_m
学習係数
by
hoxo_m
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
AJAXサイトの情報をWebスクレイピング
by
hoxo_m
高速なガンマ分布の最尤推定法について
by
hoxo_m
経験過程
by
hoxo_m
非制約最小二乗密度比推定法 uLSIF を用いた外れ値検出
by
hoxo_m
カップルが一緒にお風呂に入る割合をベイズ推定してみた
by
hoxo_m
Stan で欠測データの相関係数を推定してみた
by
hoxo_m
チェビシェフの不等式
by
hoxo_m
swirl パッケージでインタラクティブ学習
by
hoxo_m
RPubs とその Bot たち
by
hoxo_m
5分でわかるベイズ確率
by
hoxo_m
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
1.
【論論⽂文紹介】 トピックモデルの評価指標 Coherence 研究まとめ 2016/01/28 牧⼭山幸史 1
2.
発表の流流れ 1. 研究背景、基礎知識識 2. 既存研究の紹介(5つ) 3.
まとめ 2
3.
1. 研究背景、基礎知識識 • トピックモデルの評価指標として Perplexity
と Coherence の 2 つが広く 使われている。 • Perplexity:予測性能 • Coherence:トピックの品質 • 確率率率モデルにおける Perplexity の定義は 明確だが Coherence はどう定義するか? 3
4.
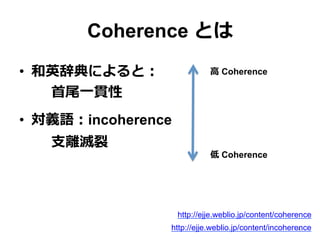
Coherence とは • 和英辞典によると: ⾸首尾⼀一貫性 •
対義語:incoherence ⽀支離離滅裂裂 http://ejje.weblio.jp/content/coherence http://ejje.weblio.jp/content/incoherence4 ⾼高 Coherence 低 Coherence
5.
Coherence とは • 抽出されたトピックが⼈人間にとって解釈 しやすいかどうかを表す指標 •
トピックを表す単語集合を考える { farmers, farm, food, rice, agriculture } { stories, undated, receive, scheduled } • 前者は Coherence が⾼高い。後者は低い。 5
6.
Coherence 研究 • Coherence
の定義は明確ではない • Coherence が⾼高いかどうかは⼈人間により 判断可能 • Chang(2009) ⼈人間による評価法を提案 • Newman(2010) ⾃自動評価法を提案 • その後、様々な⾃自動評価法が提案される 6
7.
発表の流流れ 1. 研究背景、基礎知識識 2. 既存研究の紹介(5つ) 3.
まとめ 7
8.
2. 既存研究の紹介 ① Chang (2009) ② Newman
(2010) ③ Mimno (2011) ④ Aletras (2013) ⑤ Lau (2014) 8
9.
① Chang (2009) •
“Reading Tea Leaves: How Humans Interpret Topic Models” 紅茶茶占い:⼈人間はどうやってトピックモデルを解釈 するか • トピックモデルの評価指標として Coherence を提案した最初の論論⽂文 • Word Intrusion(単語の押しつけ)という⽅方法 でトピックの Coherence を⼈人間に評価させ る 9
10.
① Chang (2009) <研究背景> •
トピックモデルの評価指標として、 Perplexity が広く使われている • 抽出されたトピックが解釈できないのは困る • トピックの品質に関する指標が必要 • ⼈人間の解釈可能性(Human-Interpretability) として Coherence を提案 10
11.
Word Intrusion(単語の押しつけ) • トピックの単語群の中に、⼀一つだけ別の 単語を混ぜて、⼈人間に⾒見見つけさせる •
仲間はずれはどれか?: { dog, cat, horse, apple, pig, cow } { car, teacher, platypus, agile, blue, Zaire } • 前者は Coherence が⾼高い。後者は低い。 • 複数⼈人に作業させ、発⾒見見成功率率率を算出 11
12.
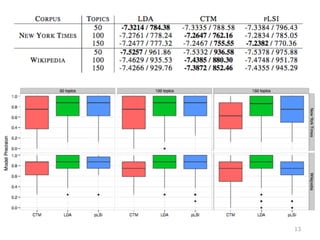
① Chan (2009) •
CTM, LDA, pLSI の 3つのトピックモデル に対して、発⾒見見成功率率率(Coherence)を測定 • 結果は次ページ • CTM は Perplexity は良良いが(上表太字)、 Coherence が低い(下図⾚赤)という結果に CTM: Correlated Topic Model LDA: Latent Dirichlet Allocation pLSI: Probabilistic Latent Semantic Indexing 12
13.
13
14.
① Chang (2009)
まとめ • Coherence を定義した最初の論論⽂文 • Word Intrusion によって⼈人間に評価させ る • Perplexity が良良いモデルでも Coherence が良良いとは限らない 14
15.
2. 既存研究の紹介 ① Chang (2009) ② Newman
(2010) ③ Mimno (2011) ④ Aletras (2013) ⑤ Lau (2014) 15
16.
② Newman (2010) •
“Automatic Evaluation of Topic Coherence” トピックコヒーレンスの⾃自動評価 • ①Chang(2009) では、⼈人間による Coherence の評価を⾏行行った • この論論⽂文では、⼈人間を介さない Coherence の算出⽅方法を提案する http://www.aclweb.org/anthology/N10-101216
17.
② Newman (2010) <基本アイデア> •
Coherence は単語間の類似度度に依存する { farmers, farm, food, rice, agriculture } { stories, undated, receive, scheduled } • 単語間類似度度をうまく定義できれば、 ⼈人⼿手を使わずに Coherence を算出できる 17
18.
② Newman (2010) •
トピックを代表する単語集合 w に対して、 単語間類似度度 D(wi, wj) の平均値もしくは 中央値を Coherence とする • ⼈人間による Coherence 評価と同じような 結果になる単語間類似度度 D(wi, wj) を探す 18
19.
② Newman (2010) •
⼈人間による Coherence の評価⽅方法は、 ①Chang(2009) と異異なり、直接的な⽅方法 • トピックの単語集合を⾒見見せ、それらの単 語間の関連性を 3 段階評価させる 「良良い」「中間」「悪い」 • ⼈人間による評価と単語類似度度による評価 のスピアマン相関を⾒見見る Gold-standard: アノテータ間の相関 19
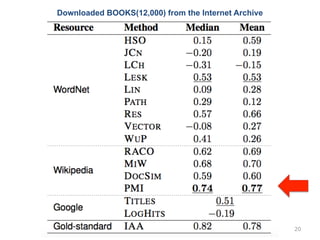
20.
Downloaded BOOKS(12,000) from
the Internet Archive 20
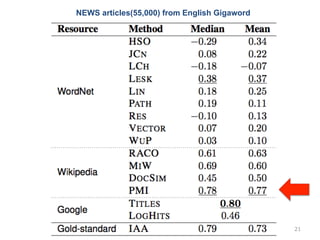
21.
NEWS articles(55,000) from
English Gigaword 21
22.
② Newman (2010) •
参照コーパスとして Wikipedia、単語間 類似度度として PMI (⾃自⼰己相互情報量量) を 使った場合が、⼈人間による評価と相関が 最も⾼高い ※ 10 words sliding window 22
23.
(余談)Google-based similarity • Google
検索索に基づく単語集合類似度度 • 単語集合 w の全ての単語を繋げたクエリ を作る +space +earth +moon +science +scientist • このクエリを投げたとき、検索索結果の上 位 100 件のタイトル部分に w 内の単語が 出現する数をカウントする • これを単語集合の類似度度とする 23
24.
② Newman (2010)
まとめ • Coherence を⼈人⼿手を使わずに算出する⽅方 法を提⽰示した • この⼿手法は、UCI Coherence と呼ばれ、 広く使われている 24
25.
2. 既存研究の紹介 ① Chang (2009) ② Newman
(2010) ③ Mimno (2011) ④ Aletras (2013) ⑤ Lau (2014) 25
26.
③ Mimno (2011) •
“Optimizing Semantic Coherence in Topic Models” トピックモデルの意味的コヒーレンスの最適化 • ②Newman(2010)では、参照コーパス (Wikipedia)を⽤用意する必要があった • 本論論⽂文では、学習コーパスのみを⽤用いた Coherence の算出⽅方法を提案する 26
27.
③ Mimno (2011) •
Framework は②Newman(2010)と同じ • 単語間類似度度として、対数条件付き確率率率 • 学習コーパスを⽤用いる D(v): 単語出現⽂文書数 D(v1,v2): 単語共起⽂文書数 27
28.
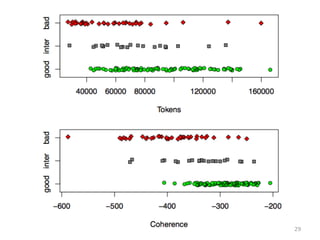
③ Mimno (2011) •
⼈人間による3段階評価との関係を⾒見見る • ベースラインとして、そのトピックに割 り当てられたトークン数(ギブスサンプリ ングにより推定)と⽐比較 • ⼈人間による評価に近い結果が得られた (※②Newmanとの⽐比較は⾏行行われていない) 28
29.
29
30.
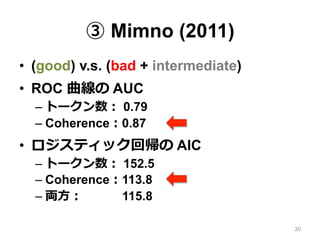
③ Mimno (2011) •
(good) v.s. (bad + intermediate) • ROC 曲線の AUC – トークン数: 0.79 – Coherence:0.87 • ロジスティック回帰の AIC – トークン数: 152.5 – Coherence:113.8 – 両⽅方: 115.8 30
31.
(余談) Word Intrusion
の問題点 • この論論⽂文では ①Chang が提案した Word Intrusion の問題点が指摘されている • トピックの単語が Chain している場合、 仲間はずれを⾒見見つけやすい { apple, apple-pie, meat-pie, meat, crab-meat, crab } • しかしこのトピックの Coherence は低い 31
32.
③ Mimno (2011)
まとめ • 参照コーパスを使わず、学習コーパスの みで Coherence を算出する⽅方法を⽰示した • UMass Coherence と呼ばれる • genism に実装されている • 新語、専⾨門⽤用語に強いと思われる(予想) • (本論論⽂文では、この評価指標を最適にする新しい トピックモデルも提案。関係ないので割愛) 32
33.
2. 既存研究の紹介 ① Chang (2009) ② Newman
(2010) ③ Mimno (2011) ④ Aletras (2013) ⑤ Lau (2014) 33
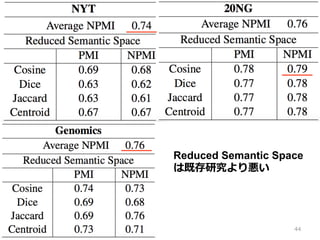
34.
④ Aletras (2013) •
“Evaluating Topic Coherence Using Distributional Semantics” 統計的意味論論を使ったトピックコヒーレンスの 評価 • 統計的意味論論における単語間類似度度を Coherence の⾃自動算出に使ってみた 34
35.
④ Aletras (2013) •
Framework は②Newman(2010)と同じ • 単語間類似度度の算出に PMI でなく、意味 空間(Semantic Space)上の類似度度を使う – コサイン類似度度、Dice係数、Jaccard係数 • 意味空間の作成に Wikipedia を使う 35
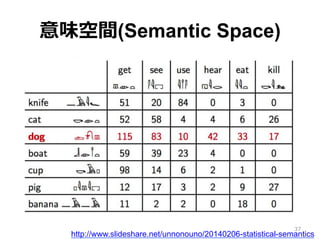
36.
意味空間(Semantic Space) • 単語を共起情報を⽤用いてベクトル化 – ⽂文脈ベクトルと呼ぶ •
よく似た共起分布を持つ単語はよく似た 意味を持つ単語である 36
37.
意味空間(Semantic Space) http://www.slideshare.net/unnonouno/20140206-statistical-semantics 37
38.
④ Aletras (2013) •
意味空間を作るための単語の共起情報 • PMI (⾃自⼰己相互情報量量) • NMPI (Normalized PMI) (Bouma2009) ※それぞれ⼆二乗値を⽤用いる 38
39.
④ Aletras (2013) •
全ての単語では意味空間の次元が⼤大きい • Reduced Semantic Space (Islam2006) – 各単語 wi に対して、トップ βwi 個だけ使⽤用 • Topic Word Space – トピックに現れる単語のみを使⽤用 m: コーパスサイズ、σ: 補正変数(今回は3に固定) 39
40.
④ Aletras (2013) •
⽂文脈ベクトル間の類似度度 3 つ • コサイン類似度度 • Dice 係数 • Jaccard 係数 http://sucrose.hatenablog.com/entry/2012/11/30/132803 40
41.
④ Aletras (2013) •
⽂文脈ベクトル集合の類似度度 1 つ • トピックの全単語の⽂文脈ベクトルの重⼼心 (Centroid)を Tc とするとき、重⼼心からの コサイン類似度度の平均値 41
42.
④ Aletras (2013) •
2 × 2 × (3+1) = 16 パターンについて、⼈人 間による評価とのスピアマン相関を⾒見見る • ⼈人間による評価は 3 段階評価 • 学習コーパス 3 つを LDA で学習 – NYT: New York Times articles(47,229) – 20NG: News Group emails(20,000) – Genomics: MEDLINE articles(30,000) MEDLINE: 医学論論⽂文データベース 42
43.
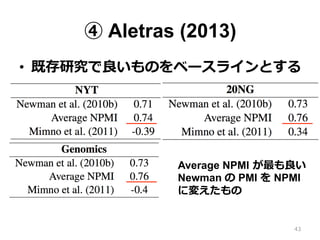
④ Aletras (2013) •
既存研究で良良いものをベースラインとする Average NPMI が最も良良い Newman の PMI を NPMI に変えたもの 43
44.
Reduced Semantic Space は既存研究より悪い 44
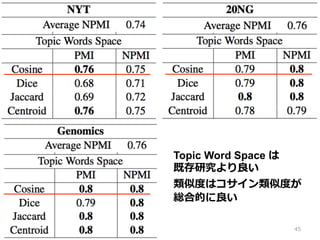
45.
Topic Word Space
は 既存研究より良良い 類似度度はコサイン類似度度が 総合的に良良い 45
46.
④ Aletras (2013)
まとめ • 意味的な類似度度を⽤用いた Coherence 評価 • Topic Word Space でコサイン類似度度を使 うと既存研究より良良くなった • 統計的意味論論によるアプローチの有効性 を⽰示した • NPMI はコサイン類似度度以外でもいい値を 出しているので意味論論的アプローチに向 いている 46
47.
2. 既存研究の紹介 ① Chang (2009) ② Newman
(2010) ③ Mimno (2011) ④ Aletras (2013) ⑤ Lau (2014) 47
48.
⑤ Lau(2014) • “Machine
Reading Tea Leaves: Automatically Evaluation Topic Coherence and Topic Model Quality” 機械で紅茶茶占い:トピックコヒーレンスと ト ピックモデル品質の⾃自動評価 • Coherence を算出する様々な⼿手法が提案さ れているが、どれが良良いか分からない • これらの⼿手法を俯瞰的に⽐比較し、どれが良良い かを評価する http://www.aclweb.org/anthology/E14-1056 48
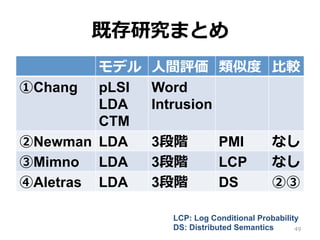
49.
既存研究まとめ モデル ⼈人間評価 類似度度
⽐比較 ①Chang pLSI LDA CTM Word Intrusion ②Newman LDA 3段階 PMI なし ③Mimno LDA 3段階 LCP なし ④Aletras LDA 3段階 DS ②③ 49 LCP: Log Conditional Probability DS: Distributed Semantics
50.
既存研究の問題点 • ①Chang(2009) と誰も⽐比較していない ⇨
Word Intrusion の⾃自動化 • トピックモデルの評価指標のはずが LDA だけで評価 ⇨ pLSI, LDA, CTM の 3つ • 参照コーパスとして Wikipedia のみ ⇨ Wikipedia, New York Times の 2つ 50
51.
既存研究の問題点 • モデルレベルで⾒見見た場合の Coherence
と トピックレベルで⾒見見た場合の Coherence を分けて考えてない ⇨ 分けて調査 51
52.
モデルレベル Coherence • モデルに対する
Coherence はトピックに 対する Coherence の平均値とする • pLSI, LDA, CTM のそれぞれをトピック数 50, 100, 150 で作成(合計 9 つ) • 9 つのモデルを⼈人間による評価と⽐比較 • ピアソン相関 (relative difference) 52
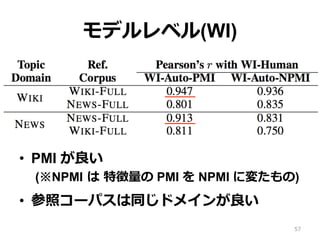
53.
モデルレベル Coherence • ⼈人間による評価: – Word
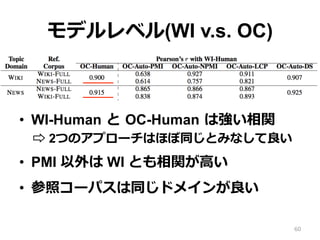
Intrusion(WI) – Observed Coherence(OC) : 3段階評価 • この論論⽂文では、WI の⾃自動評価法を提案 • OC については既存⼿手法を⽐比較 • WI v.s. OC の⽐比較も⾏行行う 53
54.
学習データと参照コーパス • 学習データ: – WIKI: Wikipedia(10,000) – NEWS:
New York Times(8,447) • 参照コーパス: – WIKI-FULL: Wikipedia(3,300,000) – NEWS-FULL: New York Times(1,200,000) 54
55.
Word Intrusion の⾃自動化 <基本アイデア> •
Lau(2010) では、トピックの単語集合から 「最も良良くトピックを表す単語」を⾒見見つ ける⽅方法を⽰示した • Word Intrusion は「トピックを表す単語 として最も悪いもの」を⾒見見つける作業で ある Lau(2010) Best Topic Word Selection for Topic Labelling 55
56.
Word Intrusion の⾃自動化 •
Intruder word を含む単語の集合について SVM-rank で順位を学習 • 特徴量量 3 つ 56
57.
モデルレベル(WI) • PMI が良良い (※NPMI
は 特徴量量の PMI を NPMI に変たもの) • 参照コーパスは同じドメインが良良い 57
58.
モデルレベル(OC) • 単語間類似度度として 4
つ • PMI (②Newman) • NPMI (Newman改) • LCP (③Mimno) – ただし、参照コーパスを使⽤用 • DS (④Aletras) – 意味空間上のコサイン類似度度 – Topic Word Space, PMI, Wikipedia 58
59.
モデルレベル(OC) • 総合的には NPMI
が良良い • WIKI に対しては LCP がベスト 59
60.
モデルレベル(WI v.s. OC) •
WI-Human と OC-Human は強い相関 ⇨ 2つのアプローチはほぼ同じとみなして良良い • PMI 以外は WI とも相関が⾼高い • 参照コーパスは同じドメインが良良い 60
61.
モデルレベル まとめ • WI
と OC はほぼ同じとみなしてよい • 以下の⼿手法のどれも良良い – WI-Auto-PMI (WI でトップ) – OC-Auto-NPMI (OC でトップ) – OC-Auto-LCP (WIKI でトップ) • 参照コーパスはドメインを同じにした⽅方 が良良い 61
62.
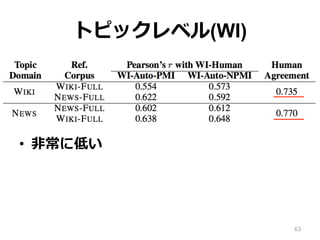
トピックレベル Coherence • 9
つのモデルの 900 トピックに対して モデルレベルと同様に⽐比較 • モデルレベルに⽐比べて⾮非常に低い相関 • 本質的な難しさがある • Human Agreement: 評価者を2グループ に分けて、その相関を算出 62
63.
トピックレベル(WI) • ⾮非常に低い 63
64.
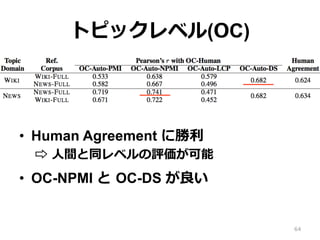
トピックレベル(OC) • Human Agreement
に勝利利 ⇨ ⼈人間と同レベルの評価が可能 • OC-NPMI と OC-DS が良良い 64
65.
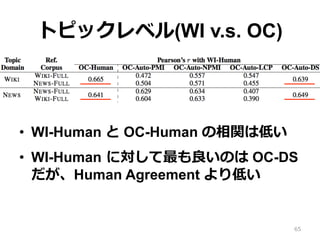
トピックレベル(WI v.s. OC) •
WI-Human と OC-Human の相関は低い • WI-Human に対して最も良良いのは OC-DS だが、Human Agreement より低い 65
66.
(余談) WI の問題点 (太字:Intruder
Word 四⾓角:⼈人間が選んだ単語) 1 & 2 ← 最初から仲間はずれが⼀一つある 3 & 4 ← 偶然関係のある単語が Intrude された 5 & 6 ← Intruder Word が浮いている 66 OC-Human* および WI-Human* は [0,1] に正規化されている
67.
⑤ Lau(2014) まとめ •
Coherence の⾃自動評価について、これま でに提案された様々な⼿手法を⽐比較した。 • モデルレベルでは、WI と OC に違いはな く、既存の OC-NPMI, OC-LCP および 我々の提案する WI-PMI が良良い。 • トピックレベルでは、WI と OC には差が あり、OC に対しては OC-NPMI と OC- DS が⼈人間と同じレベルで評価可能。 67
68.
発表の流流れ 1. 研究背景、基礎知識識 2. 既存研究の紹介(5つ) 3.
まとめ 68
69.
まとめ 69


















































![(余談) WI の問題点
(太字:Intruder Word 四⾓角:⼈人間が選んだ単語)
1 & 2 ← 最初から仲間はずれが⼀一つある
3 & 4 ← 偶然関係のある単語が Intrude された
5 & 6 ← Intruder Word が浮いている
66
OC-Human* および WI-Human* は [0,1] に正規化されている](https://image.slidesharecdn.com/20160128lt-160128103325/85/Coherence-66-320.jpg)








![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)



















































