多項分布、ディリクレ分布の例
経験ベイズ法 :
事前分布のパラメターの初期値の推定例
)10(d||maxargmax EBp
x
K
i
m
i
KK
K
i
m
i
K
i
i
K
i
iKi
ii
ii
mm
M
XDir
XDir
DirXMultXDir
MmmmXmi
1
1
11
0
max
1
1
0
11
1
maxarg
)|(maxarg
),|(maxarg
)|(|),|(
,),,...,(
:の出現回数観測データ
問題の定式化
)30(
),|(
),|(
)1|()1(
)1|()1(
)|1(
)20(),|(),|()|()()(
)11(),|(),|()|(
)10()(
)1()1(1,0
1),|(),|()(
,,,,,
2,1
j
k
2,1
222111
2,1
2211
21
2211
21222111
222111
21
21
GM
xN
xN
zxpzp
zxpzp
xzpz
z
GMxNxNzxpzpxp
GMxNxNxp
GMp
zpzpz
xNxNxp
j
jj
kk
k
kk
kk
kk
k
k
kk
zz
zz
k
理で書きなおすを導入し、ベイズの定されるここで次のように定義
潜在変数
推定するパラメター:
z
z
16.
いよいよEMアルゴリズムの適用
次のパラメターに適当な初期値を設定:
Estep: P(Z|X, θ(t))を計算
ただし、観測されたデータはN個あるとする。
実際には、P(Z|X, θ(t))ではなく Zの期待値 を求めておくことにする
。
k
N
n
nk
N
n
nk
N
n k
nk
N
n k
nk
nkn
nk
j
jjn
kkn
z
z
jjn
z
z
kknnk
nk
nknn
N
n
z
n
z
n
Nzz
Nzznote
zx
GMz
xN
xN
xN
xNz
z
kwherezzzZ
xNxNXZpGMGM
nj
nj
nk
nk
nn
11
1
2
11
2
1
2,1
2
j
2
k
2
j
2
k
21
1
2
222
2
111
2
E
E!
(
)40(
),|(
),|(
),|(
),|(
E
)2,1,
),|(),|(),,,|()11()10(
21
定義より
表すばれるか)への寄与をどちらの正規分布が選のこれはデータ
を評価する。 まとめて(すなわちここで
より と
kk
2
k ,,
kk ,,kの の現在の値
から計算した更新値
17.
Mstep
での最適値を求める。を最大化してこの
においてを固定した上で次に
より
より
step
GMz
GMxNz
xNzZXp
GM
xNzZXp
xNxNZpZXpZXp
GMGM
kkk
nk
kknk
N
n k
nk
kknk
N
n k
nk
kknk
N
n k
nk
N
n
z
n
z
n
nn
2
2
1
2
1
2
1
2
1
2
Z
1
2
1
1
222111
,,
)50(
)50(),|(loglog
),|(loglogE),,|,(logE
)40(
),|(loglog),,|,(log
),|(),|()()|(),,|,(
)11)(10(
21
18.
)70(
1
0
)(
2
)(
log
),|(loglog
)50(
1
1
1
1
2
2
2
1
2
1
1
2
1
GMzx
N
z
zx
x
z
const
x
z
xNz
GM
N
n
nkn
k
N
n
nk
N
n
nkn
new
k
N
n k
kn
nk
k
kn
k
N
n k
nk
k
kknk
N
n k
nk
k
k
new
kk
。で微分してゼロとおくを
に更新するの最適化し
19.
)80(
)(
)()801(
)801(0
2
)(
2
1
2
)(
log
2
1
),|(loglog
)50(
1
2
2
1
2
1
2
1
22
2
2
2
2
2
1
2
1
2
2
1
2
1
2
22
GM
N
xz
xzzGM
GM
x
z
const
x
z
xNz
GM
k
N
n
knnk
new
k
N
n
knnk
N
n
nkk
N
n
k
kn
k
nk
k
kn
k
N
n k
nk
k
kknk
N
n k
nk
k
k
new
kk
より
。で微分してゼロとおくを
に更新するの最適化し、
20.
)90(2
0
0
1),|(loglog
2
1 1
11
2
1
2
1
2
1
GM
N
N
Nz
Nz
zL
xNzL
k
k
k
k
N
n
nk
k
new
kk
N
n
nk
N
n k
nk
k
k
kkknk
N
n k
nk
k
式より以上の
一方
の最適化
ここでは、 が古い を反映して計算された値であった。
それを固定して、loglikelihoodを最大化する新たな を求めているわ
けだ。
以上の(GM70)(GM80)(GM90)によって の更新式が求められた。
log likelihood (GM50)が収束しなければEstepに戻る
)( kz 2
,, kkk
2
,, kkk
2
,, kkk
問題の定式化
)30(
),|(
),|(
)1|()1(
)1|()1(
)|1(
)20(),|(),|()|()()(
)11(),|(),|()|(
)10()(
)1()1(1,0
1),|(),|()(
,,,,,
2,1
j
k
2,1
222111
2,1
2211
21
2211
21222111
222111
21
21
GM
xN
xN
zxpzp
zxpzp
xzpz
z
GMxNxNzxpzpxp
GMxNxNxp
GMp
zpzpz
xNxNxp
j
jj
kk
k
kk
kk
kk
k
k
kk
zz
zz
k
理で書きなおすを導入し、ベイズの定されるここで次のように定義
潜在変数
推定するパラメター:
z
z
24.
いよいよEMアルゴリズムの適用
次のパラメターに適当な初期値を設定:
Estep: P(Z|X, θ(t))を計算
ただし、観測されたデータはN個あるとする。
実際には、P(Z|X, θ(t))ではなく Zの期待値 を求めておくことにす
る。
k
N
n
nk
N
n
nk
N
n k
nk
N
n k
nk
nkn
nk
j
jjn
kkn
z
z
jjn
z
z
kknnk
nk
nknn
N
n
z
n
z
n
Nzz
Nzznote
zx
GMz
xN
xN
xN
xNz
z
kwherezzzZ
xNxNXZpGMGM
nj
nj
nk
nk
nn
11
1
2
11
2
1
2,1
j
k
j
k
21
1
222111
E
E!
(
)40(
),|(
),|(
),|(
),|(
E
)2,1,
),|(),|(),,,|()11()10( 21
定義より
表すばれるか)への寄与をどちらの正規分布が選のこれはデータ
を評価する。 まとめて(すなわちここで
より と
kk ,,k
kk ,,k の の現在の値か
ら計算した更新値
25.
Mstep
での最適値を求める。を最適化してこの
においてを固定した上で次に
より
より
step
GMz
xNz
GMxNz
xNzZXp
GM
xNzZXp
xNxNZpZXpZXp
GMGM
kkk
nk
kknk
N
n k
nk
kknk
N
n k
nk
kknk
N
n k
nk
kknk
N
n k
nk
N
n
z
n
z
n
nn
,,
)50(
),|(loglog
)50(),|(loglog
),|(loglogE),,|,(logE
)40(
),|(loglog),,|,(log
),|(),|()()|(),,|,(
)11)(10(
1
1
2
1
1
2
1
1
2
1
Z
1
2
1
1
222111
21
26.
)70(
1
0
)()(
2
1
log
),|(loglog
)50(
1
1
1
1
1
1
1
2
1
1
2
1
GMzx
N
z
zx
xz
constxxz
xNz
GM
N
n
nkn
k
N
n
nk
N
n
nkn
new
k
N
n
knknk
knk
T
knk
N
n k
nk
k
kknk
N
n k
nk
k
k
new
kk
。で微分してゼロとおくを
に更新するの最適化し
27.
ここが多変数だと難しくなる部分
N
n k
knk
T
kn
k
k
nk
knk
T
knk
N
n k
nk
k
kknk
N
n k
nk
k
k
new
k
new
kkk
new
kk
GM
xx
z
constxxz
xNz
GM
1
1
2
1
1
1
2
1
11
)801(0
)()(
2
1log
2
1
)()(
2
1
log
2
1
),|(loglog
)50(
)()(
。で微分してゼロとおくを
に更新するの最適化し、
に更新するの最適化し、
28.
)80(
)()(
)()()803)(802)(801(
)803(0)()()()(
)()()()(
log
)(
)(
)802(
log
)801(
)801(0
)()(
2
1log
2
1
11
1
1
1
1
1
11
1
11
1
11
1
GM
N
xxz
Nzz
xxzzGMGMGM
GMxxxx
xxtracexx
trace
AtraceA
GM
GM
GM
xx
z
k
N
n
T
knknnk
new
k
new
k
kk
N
n
nkk
N
n
knk
N
n
T
knknnk
N
n
knk
T
knknk
TT
knknk
T
knknk
k
kknk
T
kn
kk
k
TTT
k
T
k
k
k
N
n k
knk
T
kn
k
k
nk
より
より 公式
を計算するのおのおのの項の微分
B
A
AB
xxxx
29.
)90(2
0
0
1),|(loglog
2
1 1
11
2
11
2
1
GM
N
N
Nz
Nz
zL
xNzL
k
k
k
k
N
n
nk
k
new
kk
N
n
nk
N
n k
nk
k
k
kkknk
N
n k
nk
k
式より以上の
一方
の最適化
ここでは、 が古い を反映して計算された値であった。
それを固定して、loglikelihoodを最大化する新たな を求めているわ
けだ。
以上の(GM70)(GM80)(GM90)によって の更新式が求められた。
log likelihood (GM50)が収束しなければEstepに戻る
kkk ,,
)( kz kkk ,,
kkk ,,
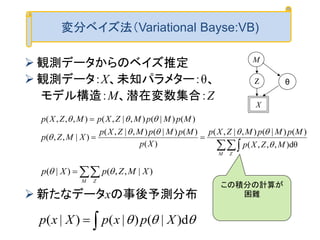
因子化の仮定下でのVBの導出 その3
とおけるのでだからなぜなら
MM
I
i
i
I
i
i
I
i
i
M
Z
I
i
i
Z
I
i
i
M
MqMq
MqMqMZq
MZXpMq
Mq
MZq
MqMZqMZq
MZXpMqMZq
Mq
MZq
MZq
MZqJ
)(1)(
0
d|d|)|(log
d),|,(log|
)(
1)|(
d|)|(log)|(
d),|,(log|)|(
)(
)|(
)|(
)]|([
11
1
Z
1
1
44.
因子化の仮定下でのVBの導出 その4
からなるベクトルのはこの式の
よって、
の値(スカラー)に対するはある
していると、が確率変数でなく確定もし、
だから、結局さらに
(*)
),|,(
1
),|,()|(
(*)|
)d,|,(log|exp)|(
)|(log1d),|,(log|
1d|
1
1
1
Z
iii
I
i
i
I
i
i
I
i
i
MZXp
CMZXCpMZq
iMq
MZXpMqCMZq
MZqMZXpMq
Mq
45.
因子化の仮定下でのVBの導出 その5
Z ji
ijii
i
i
Z ji
ij
iii
ii
i
i
i
Z ji
ij
M
ii
I
i
i
i
i
i
Z
I
i
i
M
i
i
i
MZXpMqMZqMpCMq
C
Mp
Mq
MZXpMqMZq
ff
Mq
Mp
MZXpMqMZq
Mq
Mq
Mq
Mp
Mq
MZqMZXpMqMZq
Mq
Mq
MqJ
MqZM
d),|,(log|)|(exp||
|
|
logd),|,(log|)|(
0)(0)d(
0
dd1
|
|
log
dd),|,(log|)|(
)(
1d|
d
|
|
log|
d),(log),|,(log|)|(
)(
)|(
)](|([
)|(
1
1
よって
だから
解く。の内部)の極値問題を下の式の次の
は の最適な分布 が与えられたときの モデル
46.
変分ベイズ法のアルゴリズム
初期化として、以下の初期分布を設定
反復計算以下を収束するまで繰り返す。
VB-E step
VB-M step
はθの構成要素からθiを除いた残りを意味する
IiMpMq old
i
old
i ,...,1})|({},)|({
)]),|,([logexp())d,|,(log)|(exp()|( ,, MZXpECMZXpMqCMZq ZM
M Z
oldnew
とする。を変数変数 oldnew
ZMi
i
old
i
M Z
new
i
new
i
MZXpEMpC
dZdMZDpMqMZqMpC
Mq
old
i
new )]),|,([logexp()|(
}){),|,(log)|}{()|(exp()|(
)|(
}{,,
'
'
}{ i
47.
変分ベイズ法再考
EMの再考を思い出して比較してみる。
P(Z,X| θ,M)をθold を固定してZ, θ,Mで期待値をとる
ことによって、Z,θ,Mに関する情報を教師データZか
ら集めて再度推定することを繰り返しての良い推定
値を求めている。
ただし、因子化仮定によってθiを別々に更新してい
る。だから解析的に更新式が求まる場合もあるわけ
だ。
とする。を変数変数 oldnew
ZMi
new
i
ZM
new
MZXpEMpCMqMstepVB
MZXpECMZqEstepVB
old
i
new )]),|,([logexp()|()|(:
)]),|,([logexp()|(:
}{,,
'
,,
48.
変分ベイズ法の例題
1変数正規分布p(X| μ, τ )のパラメターを観測データから推
定。ただし、平均値μ (これを潜在変数Zとみなす) 精度
(=分散の逆数)τ (これをパラメターθとみなす)の事前分
布は以下のように与えられているとする。
p(τ|a,b )を定義するガンマ関数は、パラメターa,bによっていろ
いろな分布形になるので、a,bを変化させて適した分布を得る
目的でVBの事前分布として使うことが多い。
)exp(
)(
),|(),|(
))(|()|(
)(
2
exp
2
),|(
0
0
1
0
0000
1
0,0
1
2
2
00
b
a
b
baGammabap
Np
xXp
aa
N
i
i
N






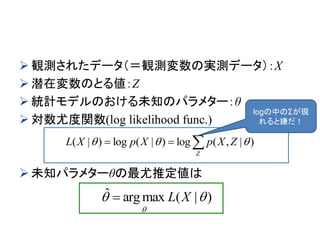




![EMとQ関数の再考
QをEZ( θold)[logP(Z,X| θ)]で書き直すと
以下のEstep, Mstepを収束するまで繰り返す
E step: P(Z|X, θold)を計算
M step: θnew =argmax θ EZ( θold)[logP(Z,X| θ)]とし、 θold を
θnewに更新
つまり、 P(Z,X| θ)を θold を固定してZで期待値をとることで
θに関する情報を教師データZから集めてにθ反映させること
を繰り返しての良い推定値を求めている。
K-meansに似ている
θはベクトル。よって、 Mstepでは、θの全要素
を一度に更新する式を求めている点に注意。](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-12-320.jpg)

















![
212
42
1
4,
42
1
22,1
(*)1loglog
)],,,,,([|
)],,,,,([maxarg1
1
)],,,,,([|
step1step2
4352
54321,,,,,
54321,,,,,
54321,,,,,
54321
54321
54321
xxyxxy
constxxxxE
xxxxxpEQ
xxxxxpEk
k
xxxxxpEQ
Q
old
old
old
xxxxx
old
xxxxx
xxxxx
old
old
old
old
old
項分布でである
1
が各々確率は
具体的には
を次式で求めるの新しい近似値
関数の結果を用いて
](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-32-320.jpg)




![に依存しない。周辺化しているので、
に対してはすなわち、
に注意。
よりの不等式
ZM
ZMXP
MZq
q
MZq
MZXp
MZq
xExEJensen
MZq
MZXp
MZq
MZXpXPXL
M Z
M Z
M Z
M Z
,,
,,)(log
1d),,(
)(d
),,(
),,,(
log),,(
)][log(])[log(
d
),,(
),,,(
),,(log
d),,,(log)(log)(
F
変分ベイズ法のトリック](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-38-320.jpg)


![因子化の仮定下でのVBの導出 その2
次のようになる。
の前に出、の右辺と無関係なので、はただし、
の微分を含まないのでが
の極値問題を解く。すなわち、次の
に対して最大化をという条件下で
はの最適な分布が与えられたときのモデル
)]|([)|(
0
)]|([
0
)|(
)]|([
)|()]|([
1)|(
d
)|(
),|,(
log|)|()()]|([
)]|([
)|(1)|(
)|(
Z
1
Z
MZqJMZq
MZqJ
MZq
MZqJ
MZqMZqJ
MZq
MZq
MZXp
MqMZqMqMZqJ
MZqJ
MZq(q)MZq
MZqZM
M Z
I
i
i
F](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-42-320.jpg)
![因子化の仮定下でのVBの導出 その3
とおけるのでだからなぜなら
MM
I
i
i
I
i
i
I
i
i
M
Z
I
i
i
Z
I
i
i
M
MqMq
MqMqMZq
MZXpMq
Mq
MZq
MqMZqMZq
MZXpMqMZq
Mq
MZq
MZq
MZqJ
)(1)(
0
d|d|)|(log
d),|,(log|
)(
1)|(
d|)|(log)|(
d),|,(log|)|(
)(
)|(
)|(
)]|([
11
1
Z
1
1](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-43-320.jpg)

|(
1
1
よって
だから
解く。の内部)の極値問題を下の式の次の
は の最適な分布 が与えられたときの モデル](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-45-320.jpg)
![変分ベイズ法のアルゴリズム
初期化として、以下の初期分布を設定
反復計算 以下を収束するまで繰り返す。
VB-E step
VB-M step
はθの構成要素からθiを除いた残りを意味する
IiMpMq old
i
old
i ,...,1})|({},)|({
)]),|,([logexp())d,|,(log)|(exp()|( ,, MZXpECMZXpMqCMZq ZM
M Z
oldnew
とする。を変数変数 oldnew
ZMi
i
old
i
M Z
new
i
new
i
MZXpEMpC
dZdMZDpMqMZqMpC
Mq
old
i
new )]),|,([logexp()|(
}){),|,(log)|}{()|(exp()|(
)|(
}{,,
'
'
}{ i](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-46-320.jpg)
![変分ベイズ法再考
EMの再考を思い出して比較してみる。
P(Z,X| θ,M)を θold を固定してZ, θ,Mで期待値をとる
ことによって、Z,θ,Mに関する情報を教師データZか
ら集めて再度推定することを繰り返しての良い推定
値を求めている。
ただし、因子化仮定によってθiを別々に更新してい
る。だから解析的に更新式が求まる場合もあるわけ
だ。
とする。を変数変数 oldnew
ZMi
new
i
ZM
new
MZXpEMpCMqMstepVB
MZXpECMZqEstepVB
old
i
new )]),|,([logexp()|()|(:
)]),|,([logexp()|(:
}{,,
'
,,
](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-47-320.jpg)

![ factorizedな変分近似の事後分布を
q(μ , τ )=q μ(μ)q τ(τ)とすると、以下のようにVB-Eステップ、VB-Mステッ
プの計算ができる。左辺のqは更新した結果とする。
VB-E:ここでは、内部変数μ,λを更新する。
][
),|()(
2
2
][
exp
)()(
2
][
exp
)]|(log),|([logexp)(
0
0
00
1
0
1
22
00
0
1
00
2
01
1
2
00
2
1
0
EN
N
xN
Nq
N
x
N
x
N
E
C
x
E
C
pXpECq
NN
NN
N
i
i
N
i
i
N
i
i
よって
E[log(τ/2π)N/2]
などはμには
関係しないの
で定数とみな
す](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-50-320.jpg)
![ VB-Mステップ
Gamma分布が指数分布族(事前分布と事後分布が同じタイプ
だから、以下のように推論できる。
こうして を定義するGamma分布のパラメターが更新さ
れた。
以下、同様にVB-E,VB-Mを収束するまで繰り返すことになる。
])()([
2
1
2
1
),|(
])()([
2
log
2
1
log)1(
exp
)]|(log))(,|([logexp)()(
1
2
00
2
0
0
1
2
00
2
00
1
1
0
N
i
iN
N
NN
N
i
i
xEbb
N
aa
baGamma
xE
N
ba
C
pXpEpCq
更新式が得られるに対応させると以下のこの結果を
)(p](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-51-320.jpg)

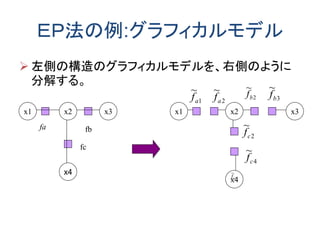
![EP法の背景
KL(p||q)を最小化するqをpから求める。
qはexponential family
一方、exponential familyであるqにおいて
][
)(
)||(KLminimize
][)()||(
))(exp()()(
)(
)(
u(z)
η
η
u(z)ηη
ηu(z)ηzz
z
z
T
T
p
p
E
a
qptothen
constEaqpKL
ahq
が保存されている。 となり=あわせると
ゆえに
より
=1の積分が1だから
momentuEuE
uE
η
ηa
duηauηhdηauηh
η
ηa
auηhq
zpzq
zq
TT
][][
][
)(
0)())()(exp()())()(exp()(
)(
d)(exp)(
)()(
)(
(z)(z)
(z)
xxxxxxx
zη(z)z T
](https://image.slidesharecdn.com/model-inf1-140313100211-phpapp02/85/9-53-320.jpg)

















![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)



















