Downloaded 18 times





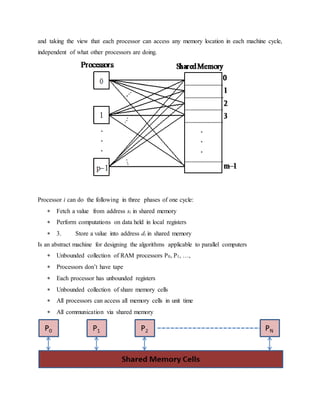



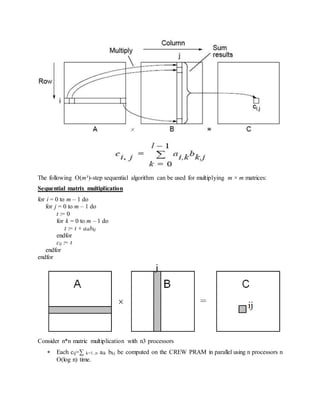


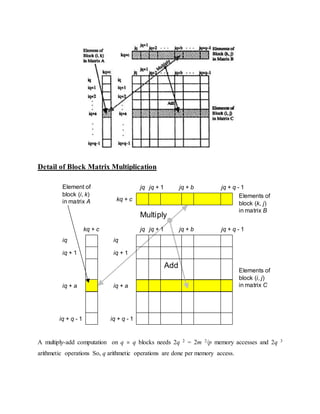



The document discusses parallel processing and matrix multiplication. It introduces parallel processing concepts like dividing a task between multiple processors to complete it faster. As an example, it explains how two people can add 100 numbers in half the time it takes one person. It then discusses using parallel processing to compute the convex hull of a set of points by dividing the set in half and merging the results. The rest of the document focuses on computational models for parallel processing like PRAM and different types of PRAM models including EREW, CREW, CRCW and how they handle read/write conflicts. It also provides an example of using parallel processing to perform matrix multiplication faster by dividing the matrices and merging the results.





























































































