This document discusses techniques for optimizing parallel programs for locality. It covers several key topics:
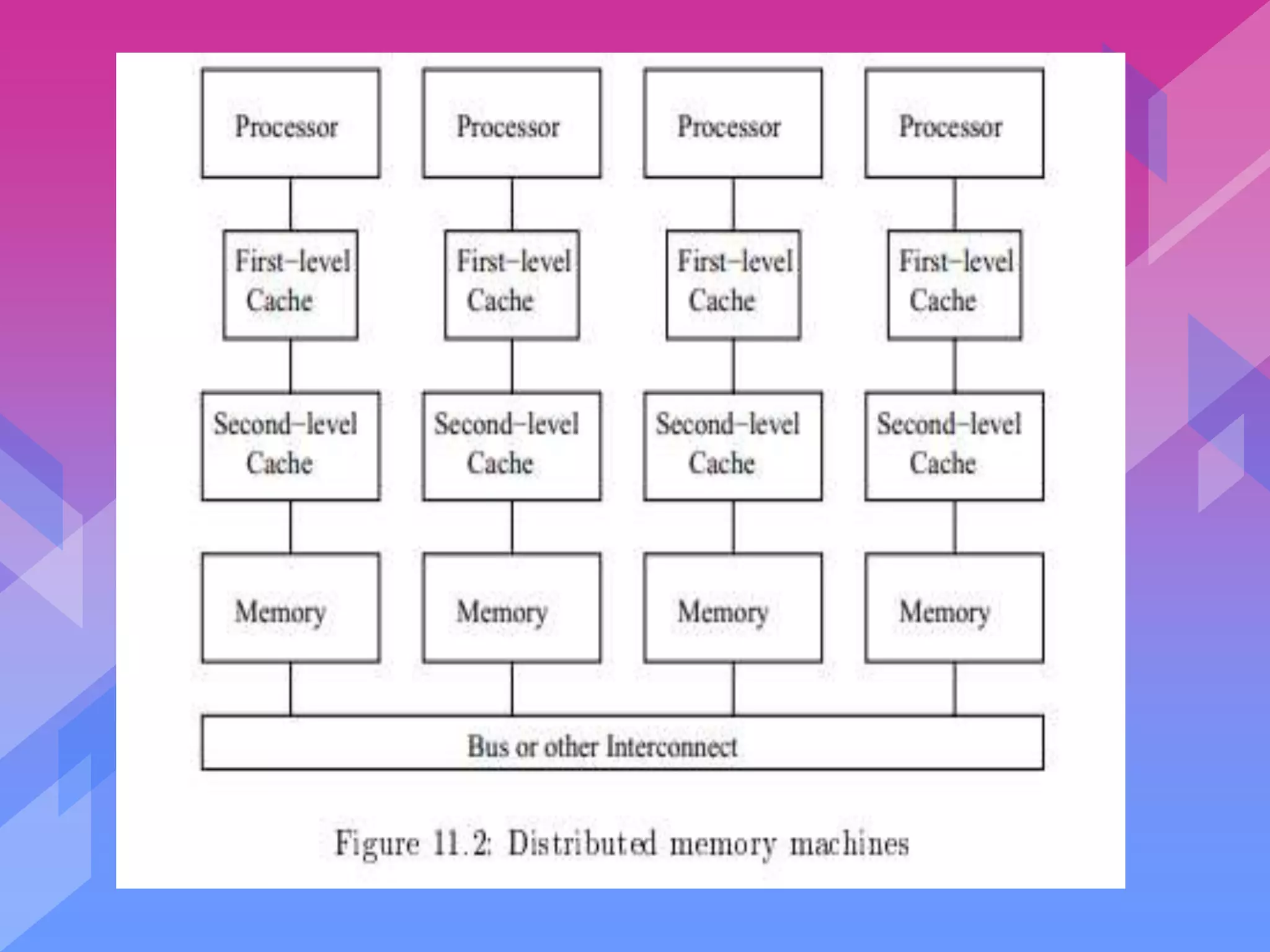
- Symmetric multiprocessors are a popular parallel architecture where all processors can access shared memory uniformly. Cache coherence protocols allow caches to share data while reading.
- Parallel programs must have good data locality to perform well. Techniques like grouping related operations on the same processor and executing code in succession on processors can improve locality.
- Loop-level parallelism is a common target for parallelization. Dividing loop iterations evenly across processors can achieve good parallelism if iterations are independent.













![The loop
for (i = 0; i < n; i++)
{
Z[i] = X[i] - Y[i];
Z[i] = Z[i] * Z[i];
}
computes the square of differences between elements in vectors X
and Y and stores it into Z.
The loop is parallelizable because each iteration accesses a
different set of data.
We can execute the loop on a computer with M processors by
giving each processor an unique ID p = 0; 1;::: ;M 1 and having
each processor execute the same code](https://image.slidesharecdn.com/complierdesignuva-211111130623/75/Complier-design-15-2048.jpg)

![for (i = 0; i < n; i++)
Z[i] = X[i] - Y[i];
for (i = 0; i < n; i++)
Z[i] = Z[i] * Z[i];
Like Example 11.1 the following also finds the
squares of differences between elements in vectors X
and Y
The first loop finds the differences, the second finds
the squares.
Code like this appears often in real programs,
because that is how we can optimize a program for
vector machines, which are supercomputers which
have instructions that perform simple arithmetic
operations on vectors at a time.](https://image.slidesharecdn.com/complierdesignuva-211111130623/75/Complier-design-17-2048.jpg)





![for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
{
Z[i,j] = 0.0; for (k = 0; k < n; k++)
Z[i,j] = Z[i,j] + X[i,k]*Y[k,j];
}
Figure 11.5: The basic matrix-
multiplication algorithm](https://image.slidesharecdn.com/complierdesignuva-211111130623/75/Complier-design-23-2048.jpg)
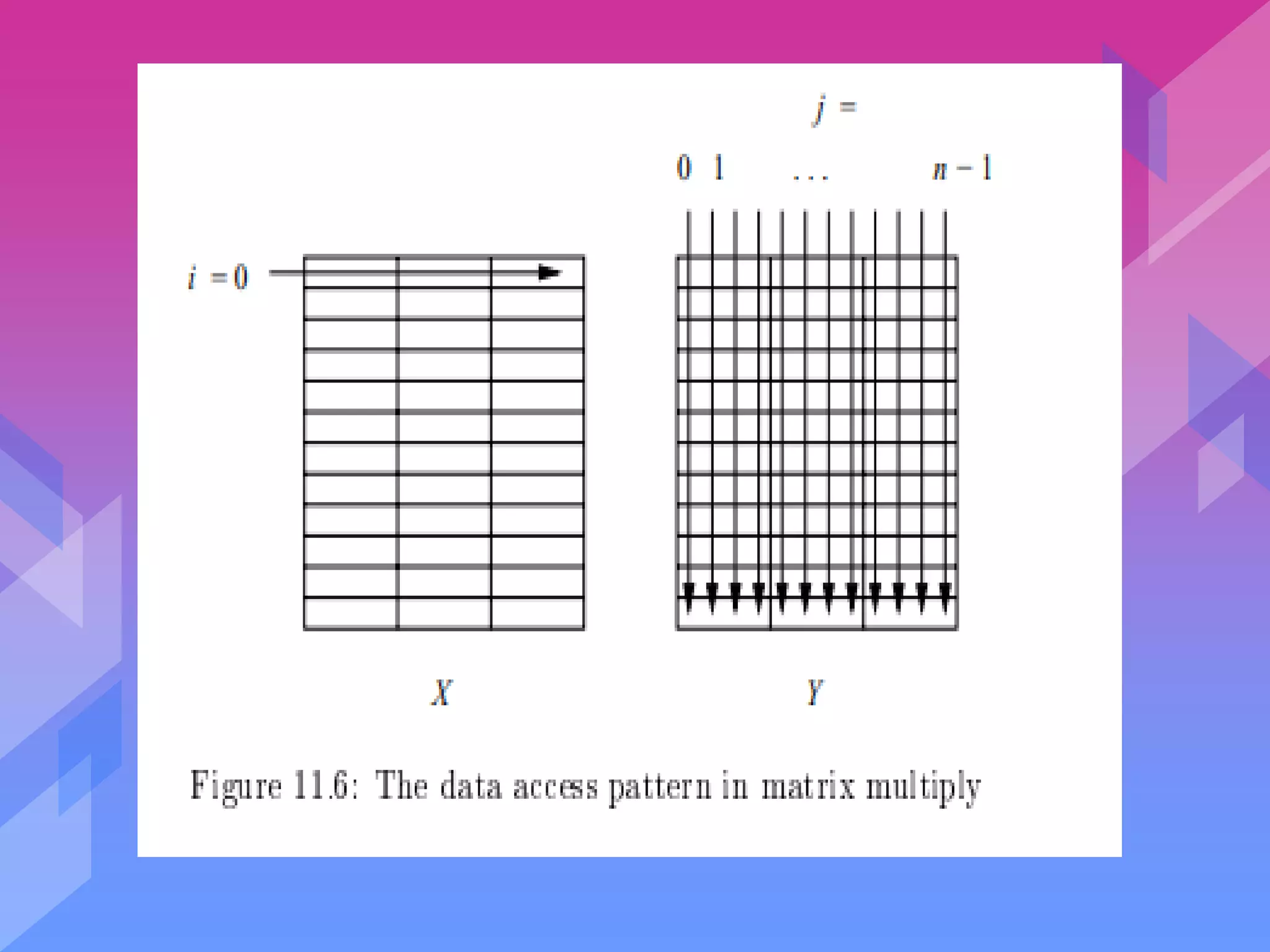
![ The innermost loop reads and writes
the same element of Z, and uses a row
of X and a column of Y .
Z[i; j] can easily be stored in a register
and requires no memory accesses.
Assume, without loss of generality, that
the matrix is laid out in row-major
order, and that c is the number of array
elements in a cache line.](https://image.slidesharecdn.com/complierdesignuva-211111130623/75/Complier-design-24-2048.jpg)