The document provides an in-depth overview of linear algebra concepts relevant to signal engineering and machine learning, covering topics such as vectors, norms, inner products, matrices, and linear equations. It explains definitions and properties, including linear independence, matrix inversion, determinants, and the formulation of linear equations in matrix form. Various special matrix forms, their properties, and applications in FIR filters are also discussed.





![Inner Product
▶ If a = [a1, ...., aN]T and b = [b1, ...., bN]T are two complex
vectors, the Inner Product is a scalar defined by
a, b = aH
b =
N
X
i=1
a∗
i bi
for real vectors inner product simplifies to
a, b = aT
b =
N
X
i=1
ai bi
▶ Inner product defines the geometrical relationship between
two vectors, which is given by
a, b = ||a|| ||b|| cos θ
θ: angle between the two vectors
▶ Orthogonal vectors: a ̸= 0 and b ̸= 0 but a, b = 0
▶ Orthonormal vectors: a, b = 0 and ||a|| = 1, ||b|| = 1](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-5-320.jpg)
![▶ The inner product between two vectors is bounded by the
product of their magnitudes
| a, b | ≤ ||a|| ||b||
equality holds when both the vectors are colinear (a = αb for
some constant α) and the above inequality is referred to as
Cauchy-Scwartz inequality
▶ Since ||a ± b||2 = ||a||2 ± 2 a, b +||b||2 ≥ 0 it follows
that
2| a, b | ≤ ||a||2
+ ||b||2
▶ Writing the sample response of an FIR filter h(n) in vector
form given below
h = [h(0), h(1), ..., h(N − 1)]T
The output y(n) of the FIR filter may be written as the inner
product
y(n) =
N−1
X
k=0
h(k)x(n − k) = hT
x(n)
where x(n) = [x(n), x(n − 1), ..., x(n − N + 1)]T](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-6-320.jpg)

![Vector Spaces and Basis Vectors
▶ Given a set of N vectors V = {v1, v2, ..., vN}, consider the set
of all vectors V that may be formed from a linear combination
of vectors vi i.e. v =
PN
i=1 αi vi and v ∈ V
▶ This set V forms a vector space
▶ The vectors vi are said to span the space V
▶ If the vectors vi are linearly independent then they are said to
form a basis for the space V
▶ The number of vectors in the basis, N, is referred to as the
dimension of the vector space V
▶ Example The set of all real vectors of the form
x = [x1, x2, ..., xN]T forms an N-dimensional vector
space,denoted by RN, that is spanned by the basis vectors,
u1 = [1, 0, 0, ..., 0]T ,u2 = [0, 1, 0, ..., 0]T ,...,uN =
[0, 0, 0, ..., 1]T . In terms of this basis, any vector
v = [v1, v2, ..., vn]T ∈ RN may be uniquely decomposed as
v =
PN
i=1 vi ui
Note:The basis for a vector space is not unique.](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-8-320.jpg)
![Matrices
▶ An n × m matrix is an array of numbers(real or complex)
functions having n rows and m columns.e.g.
A = [aij ] =
a11 a12 .. a1m
a21 a22 .. a2m
. . .
. . .
an1 an2 .. anm
is an n × m matrix of numbers aij and
A(z) = [aij (z)] =
a11(z) a12(z) .. a1m(z)
a21(z) a22(z) .. a2m(z)
. . .
. . .
an1(z) an2(z) .. anm(z)
is an n × m matrix of functions aij (z)
▶ If n = m then A is a n × n square matrix of n rows and n
columns](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-9-320.jpg)
![▶ Example: The output of an FIR-LTI filter with a unit sample
response h(n) may be written in vector form as
y(n) = hT
x(n) = xT
(n)h
if x(n) = 0 for n 0, then we may express y(n) for n ≥ 0 as
X0h = y, where X0 is a convolution matrix defined by
X0 =
x(0) 0 0 .. 0
x(1) x(0) 0 .. 0
x(2) x(1) x(0) .. 0
. . . .
. . . .
x(N − 1) x(N − 2) x(N − 3) .. x(0)
. . . .
. . . .
and y = [y(0), y(1), y(2), ...]T
Note: The elements of X0 in each diagonal are same. X0 has
N − 1 columns and an infinite number of rows.](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-10-320.jpg)
![▶ Matrices can also be represented as a set of column vectors or
row vectors, such as A = [c1, c2, ..., cm] or A =
rH
1
rH
2
.
.
rH
n
▶ A matrix may also be partitioned into submatrices. For
instance the matrix A may be partitioned into
A =
A11 A12
A21 A22
where A11 is p × q,A12 is p × (m − q),A21
is (n − p) × q and A22 is (n − p) × (m − q)
▶ If A is an n × m matrix, then the transpose denoted by AT
is
the m × n matrix that is formed by interchanging the rows
and columns of A
▶ Symmetric matrix: For a square matrix if A = AT
▶ Hermitian Transpose:AH
= (A∗
)T
= (AT
)
∗
▶ Hermitian matrix: For a square complex valued matrix if
A = AH
▶ Properties: (A + B)H = AH
+ BH
, (AH
)H = A and
(AB)H = BH
AH](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-11-320.jpg)


![Determinant Property
det(AB) = det(A)det(B) det(αA) = αndet(A)
det(A−1
) = 1
det(A),A is invertible det(AT
) = det(A)
▶ Example For a 2 × 2 matrix
A =
a11 a12
a21 a22
det(A) = a11a22 − a12a21
and for a 3 × 3 matrix
A =
a11 a12 a13
a21 a22 a23
a31 a32 a33
det(A) = a11det
a22 a23
a32 a33
−a12det
a21 a23
a31 a33
+a13det
a21 a22
a31 a32
= a11[a22a33−a23a32]−a12[a21a33−a31a23]+a13[a21a32−a31a22]](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-14-320.jpg)




![▶ Exchange Matrix: It is symmetric and has ones along the
cross diagonal and zeros everywhere else.i.e.
J =
0 ... 0 1
0 ... 1 0
.
.
.
.
.
.
.
.
.
1 ... 0 0
▶ Interestingly J2
= I and J−1
= J
▶ when we post multiply a vector v by the exchange matrix J
the order of the entries of v will reverse. i.e.
J[v1, v2, ..., vn]T
= [vn, vn−1, ..., v1]
▶ If a matrix A is multiplied on the left by the exchange matrix,
the operation would reverse the order of each column. e.g.
A =
a11 a12 a13
a21 a22 a23
a31 a32 a33
⇒ JT
A =
a31 a32 a33
a21 a22 a23
a11 a12 a13
▶ Similarly if A is multiplied on the right by J, then the order of
the entries in each row is reversed](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-19-320.jpg)



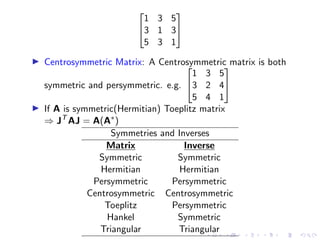
![▶ Orthogonal Matrix: A real n × n matrix is said to be
orthogonal if the columns(and rows) are orthonormal. i.e. if
the columns of A are ai then
A = [a1, a2, ..., an] and aT
i ai =
(
1 i = j
0 i ̸= j
▶ If A is orthogonal then AT
A = I, thus the inverse A−1
= AT
▶ Example:Exchange Matrix J is an orthogonal Matrix since
JT
J = J2
= I
▶ In a complex n × n Matrix A, if the columns(rows) are
orthogonal
aH
i ai =
(
1 i = j
0 i ̸= j
which implies AH
A = I and A is said to be Unitary matrix
▶ The inverse of a unitary matrix is same as its Hermitian
transpose
A−1
= AH](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-24-320.jpg)
![Quadratic and Hermitian Forms
▶ The quadratic form of a n × n real symmetric matrix A and a
n × n Hermitian matrix C is a scalar and is respectively
defined by
QA(x) = xT Ax =
Pn
i=1
Pn
j=1 xi aij xj
and
QC (x) = xHCx =
Pn
i=1
Pn
j=1 x∗
i aij xj
where xT = [x1, x2, ..., xn] is a vector of n real variables and
also the quadratic form is a quadratic function in the n
variables x1, x2, ..., xn
▶ Example: The quadratic form of A =
2 −1
1 2
is
QA(x) = xT Ax = 2x2
1 + 2x2
2
▶ For any x ̸= 0
Definiteness condition Definiteness condition
+ve definite QA(x) 0 -ve Semidefinite QA(x) ≤ 0
+ve semidefinite QA(x) ≥ 0 indefinite none of above
-ve definite QA(x) 0](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-25-320.jpg)



![Eigenvalue Decomposition
▶ Let A be an n × n matrix with eigenvalues λk and
eigenvectors vk then
Avk = λkvk for k = 1, 2, ..., n
Matrix form of these n equations are as under
A[v1, v2, ...vn] = [λ1v1, λ2v2, ...λnvn]
Substituting V = [v1, v2, ..., vn] and Λ = diag{λ1, λ2, ..., λn}
we get
AV = VΛ
If the eigenvectors vi are independent then V is invertible and
the decomposition is as follows
A = VΛV−1
▶ Spectral Theorem When a matrix A is Hermitian then V is
unitary and the Eigenvalue Decomposition becomes
A = VΛVH
=
Pn
i=1 λi vi vH
i
This simplified Eigenvalue Decomposition is known as
Spectral Theorem where λi being the eigenvalues and vi are a
set of orthonormal vectors of A](https://image.slidesharecdn.com/linearalgebraforml-220924052125-dc8dc15f/85/Linear-Algebra-for-AI-ML-29-320.jpg)























































































