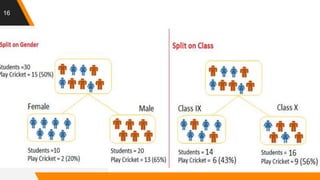
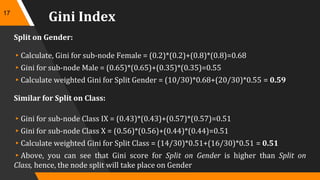
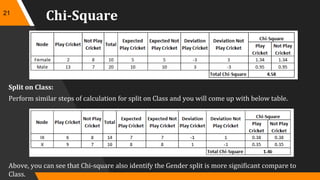
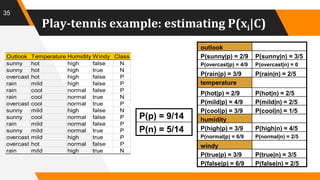
A decision tree is a decision support tool that utilizes a tree-like model for decision making, aiding in classification and prediction. It represents rules in a way that's comprehensible to humans and relies on sufficient data and predefined classes to learn models. Key algorithms for tree construction include Gini index, chi-square, and information gain, with a focus on splitting nodes to enhance accuracy and reduce complexity through techniques like pruning.