Downloaded 26 times

















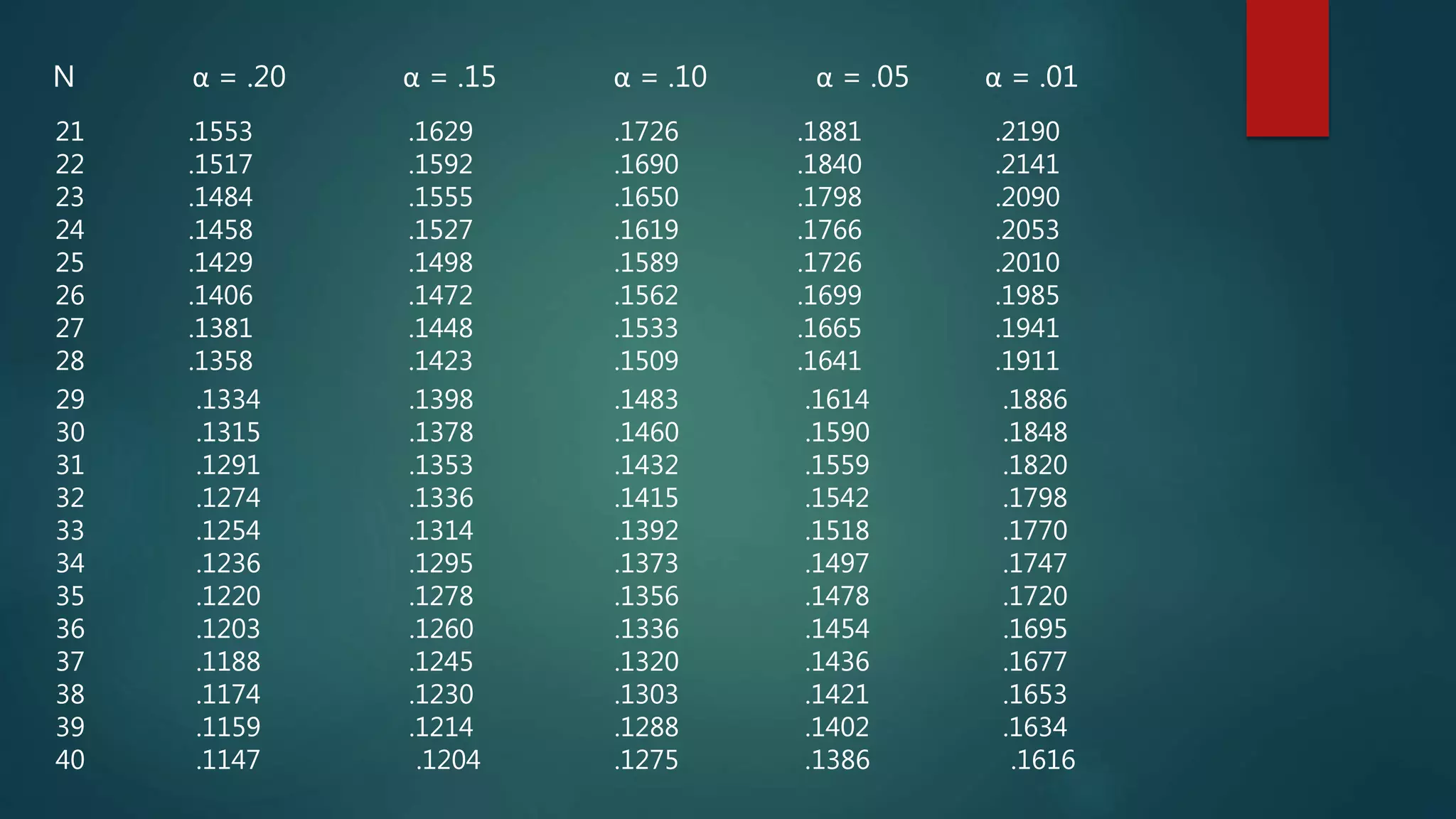



The document provides information about the Lilliefors test for normality. It discusses that the Lilliefors test was derived in 1967 by Hubert Lilliefors and is used to test the null hypothesis that data comes from a normal distribution based on the Kolmogorov-Smirnov test. It then outlines the procedure for conducting the Lilliefors test, which includes determining the test statistic by calculating the maximum difference between the empirical distribution function and the theoretical normal distribution function, and comparing this value to critical values from a table to determine whether to reject or fail to reject the null hypothesis. An example applying the Lilliefors test to sample data is also provided and worked through step





















































































