Downloaded 67 times
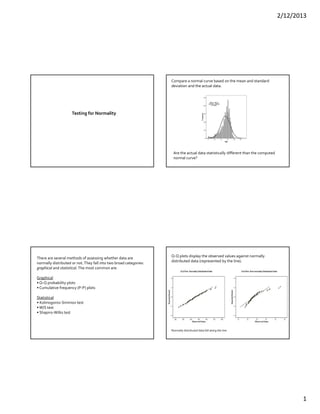
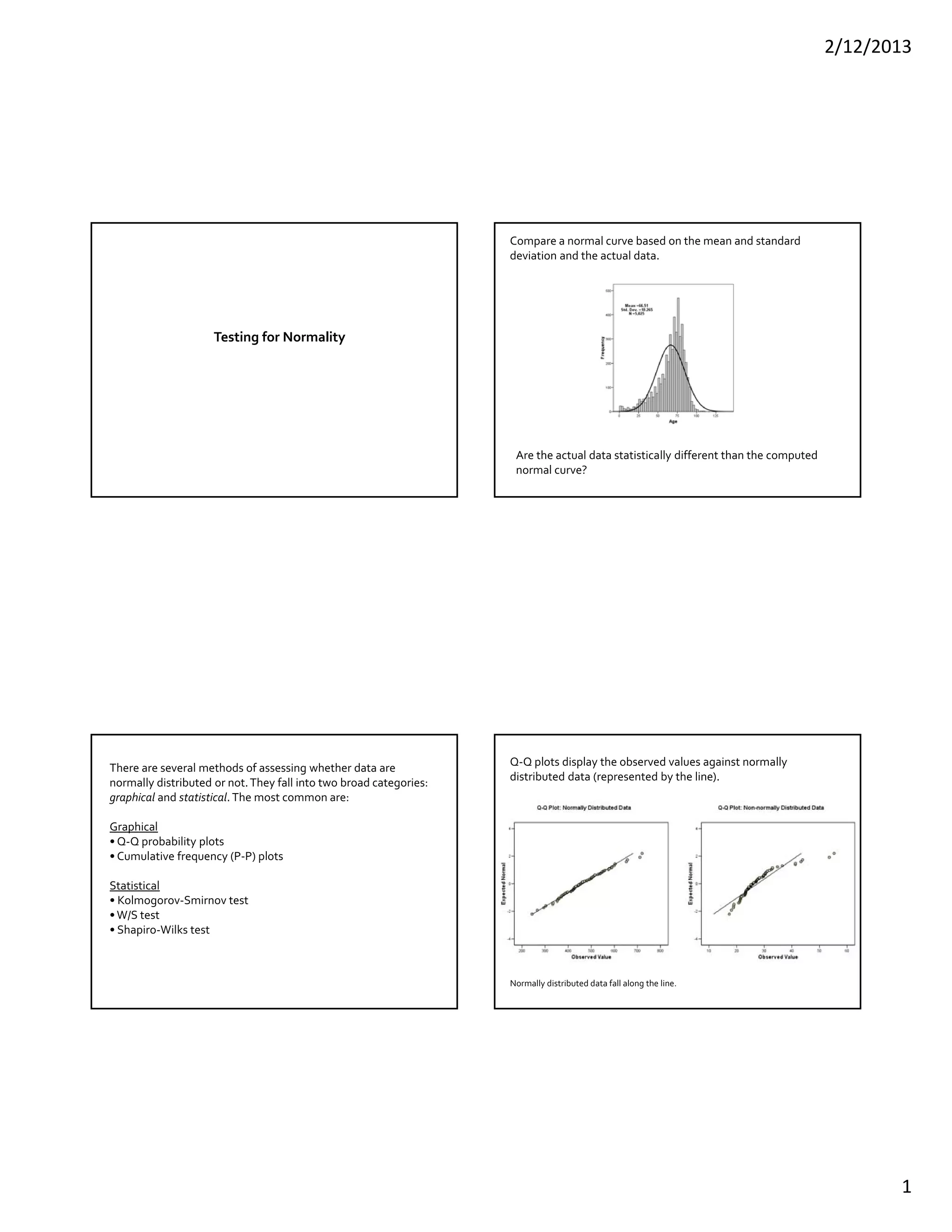






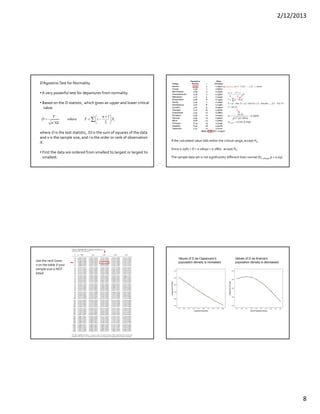
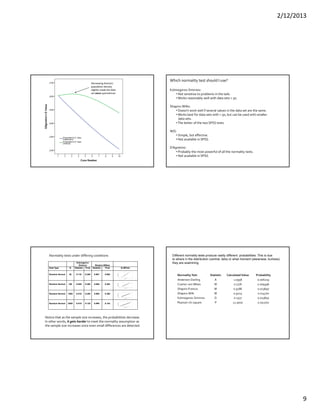


This document discusses methods for testing whether a data set is normally distributed. It describes both graphical and statistical tests for normality, including Q-Q plots and the Kolmogorov-Smirnov, Shapiro-Wilk, and Lilliefors tests. It then provides a detailed example of how to perform the Kolmogorov-Smirnov test for normality on a set of height data.









































































