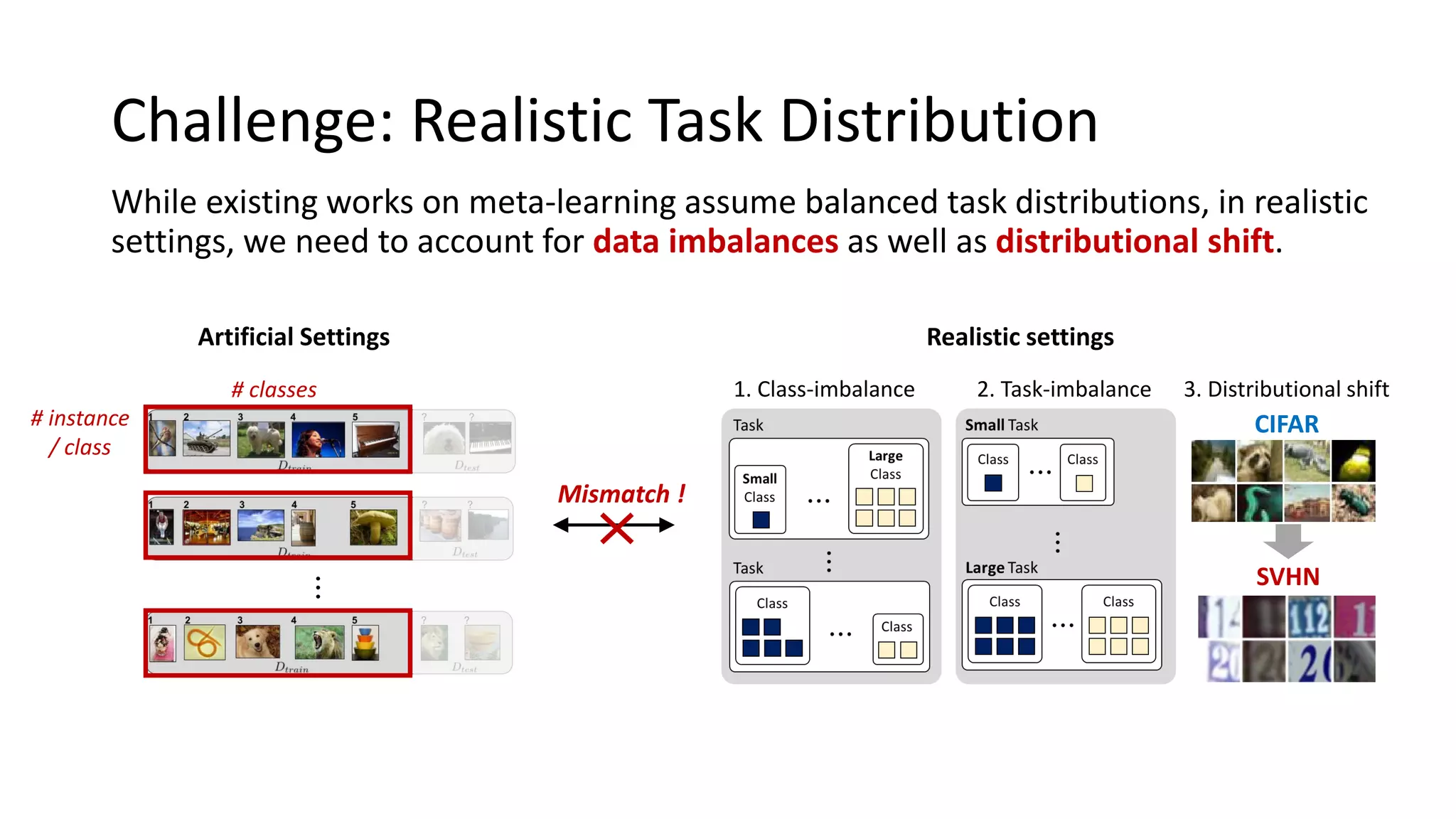
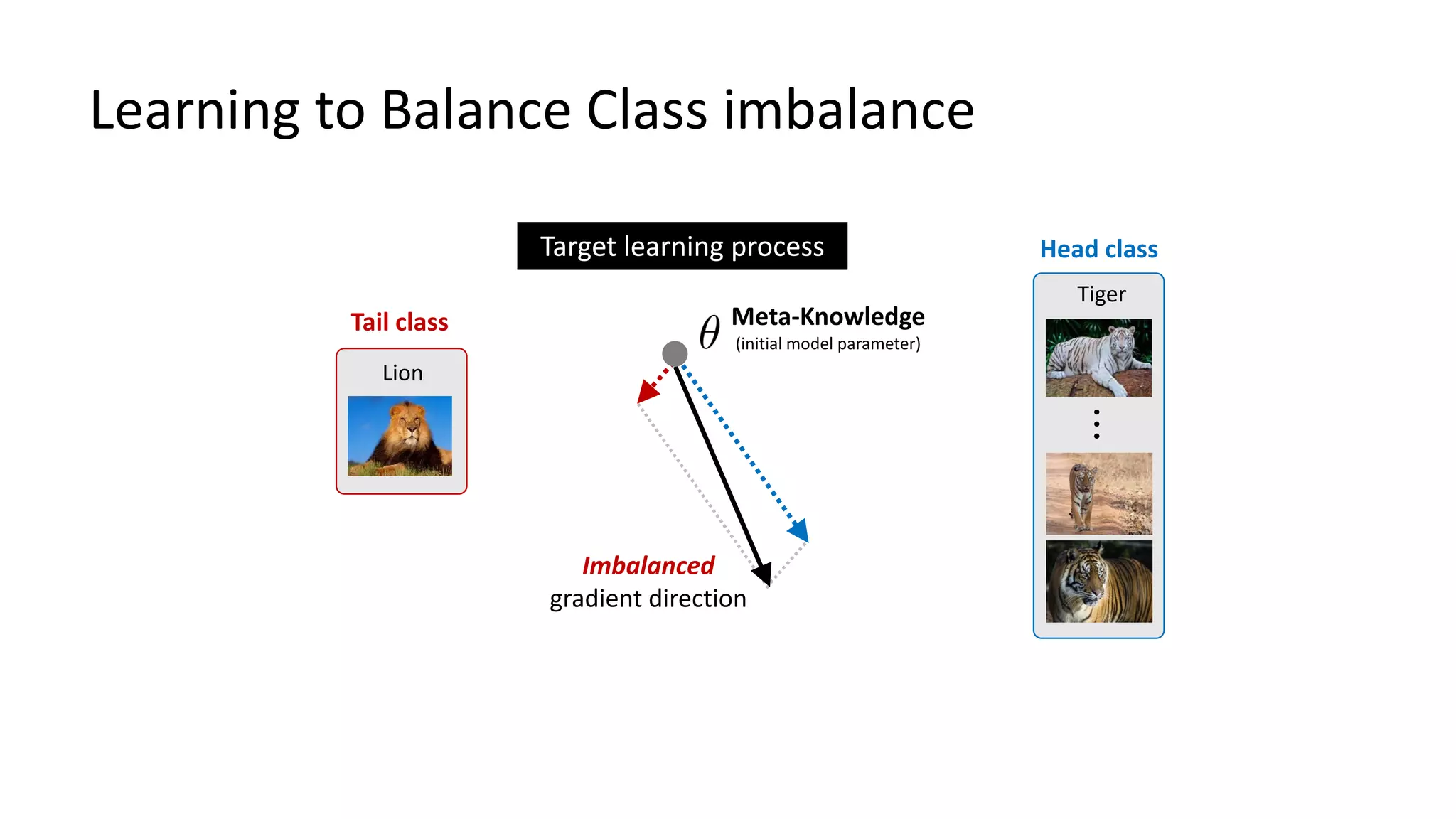
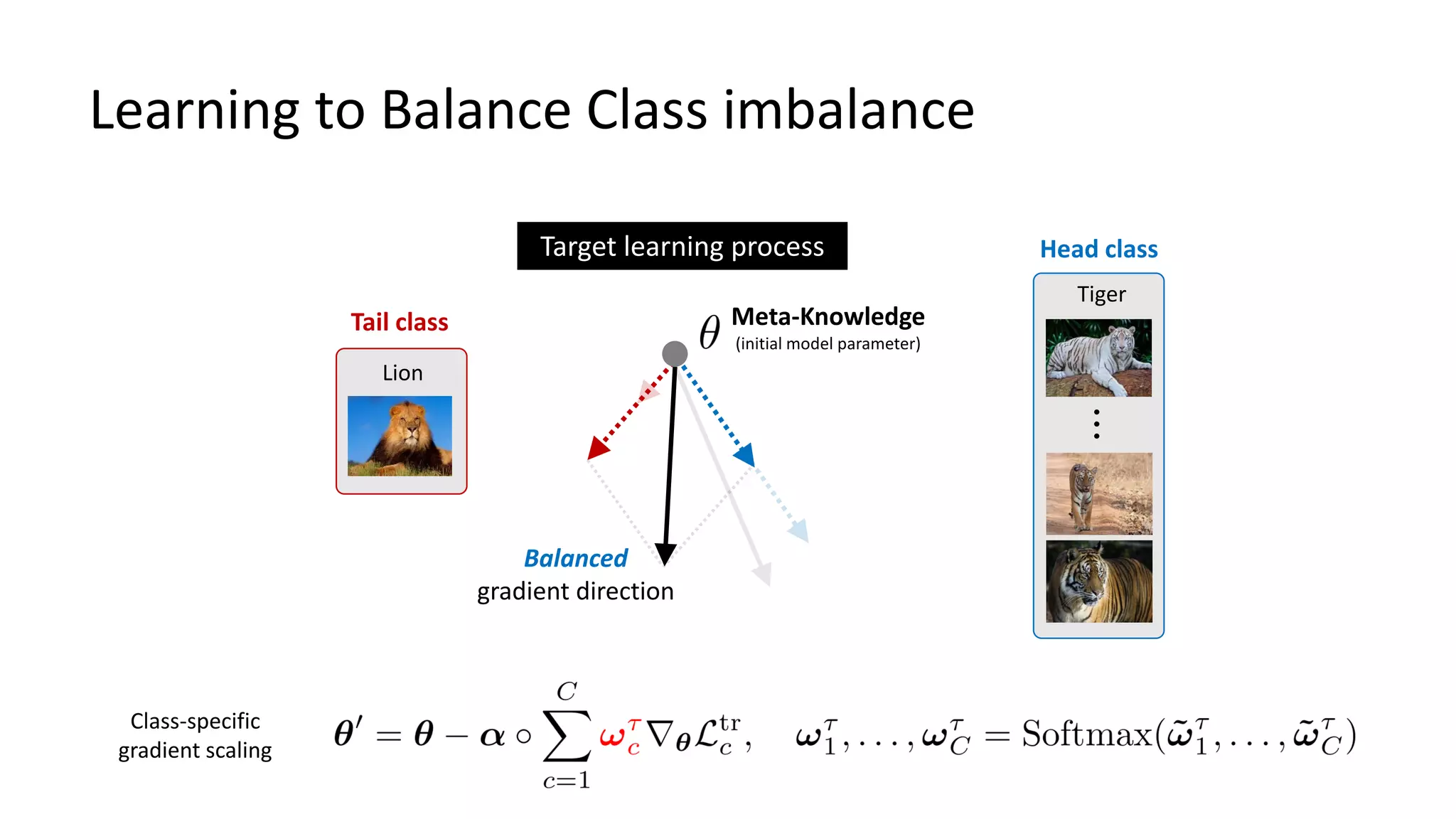
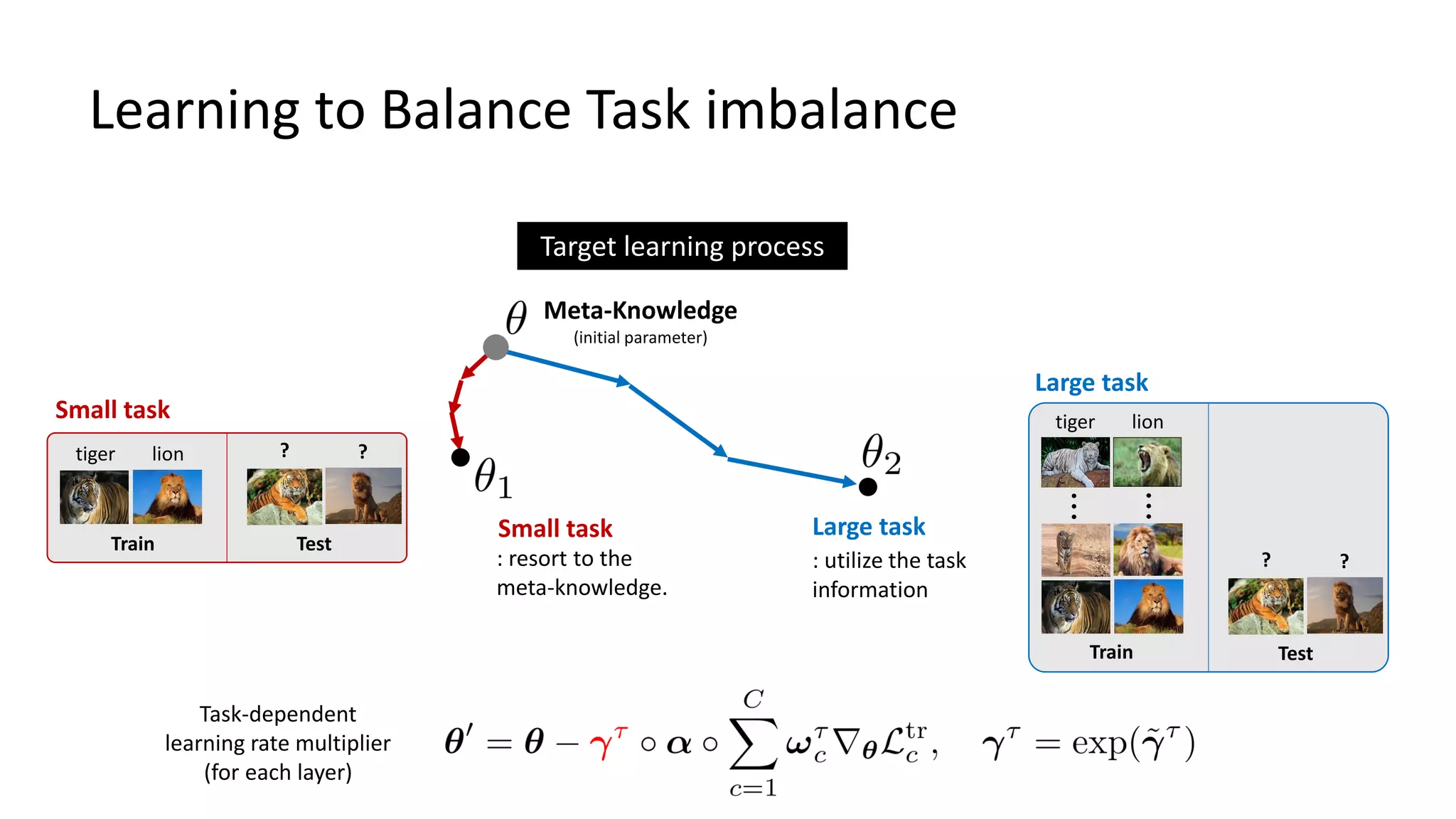
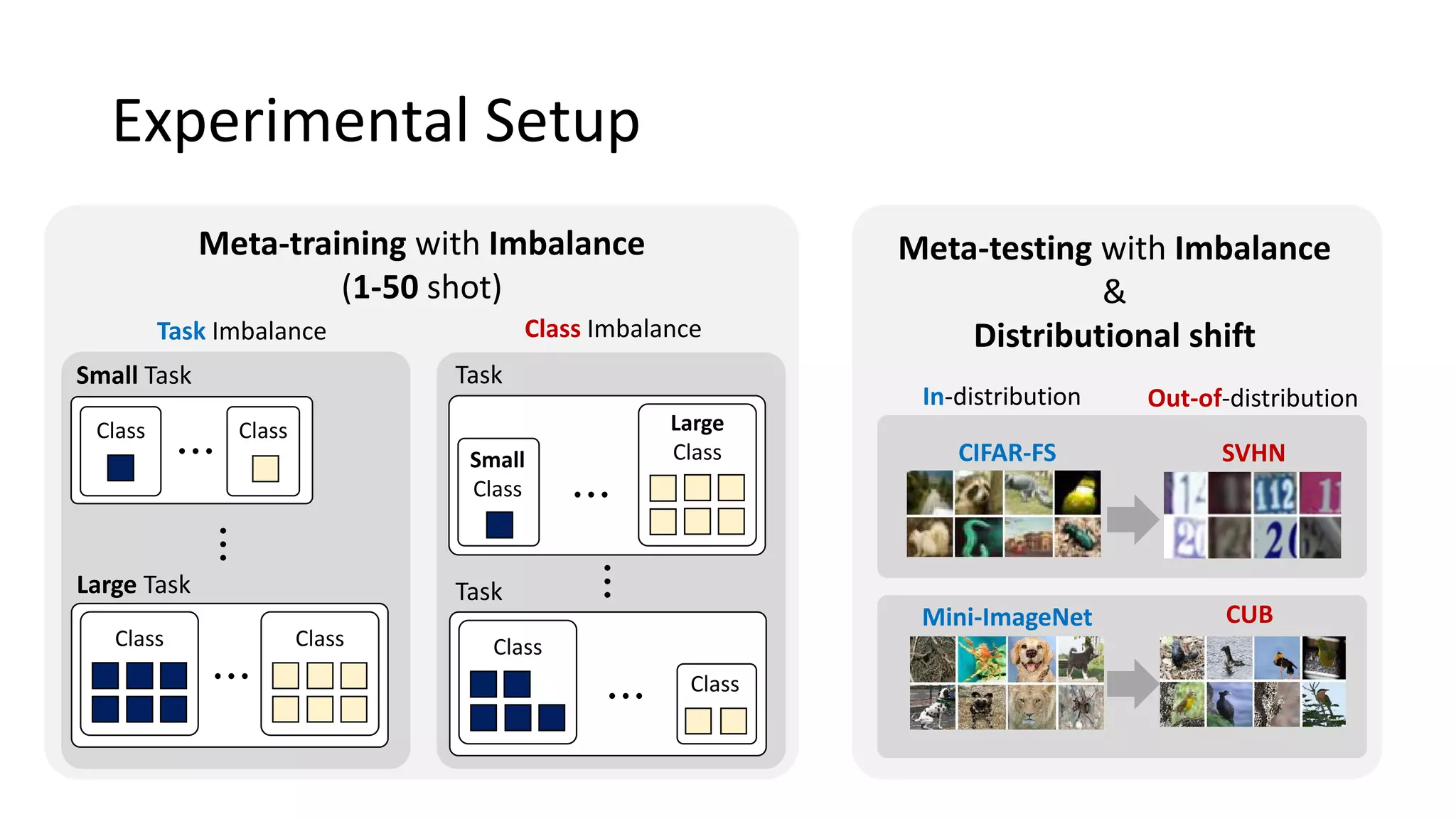
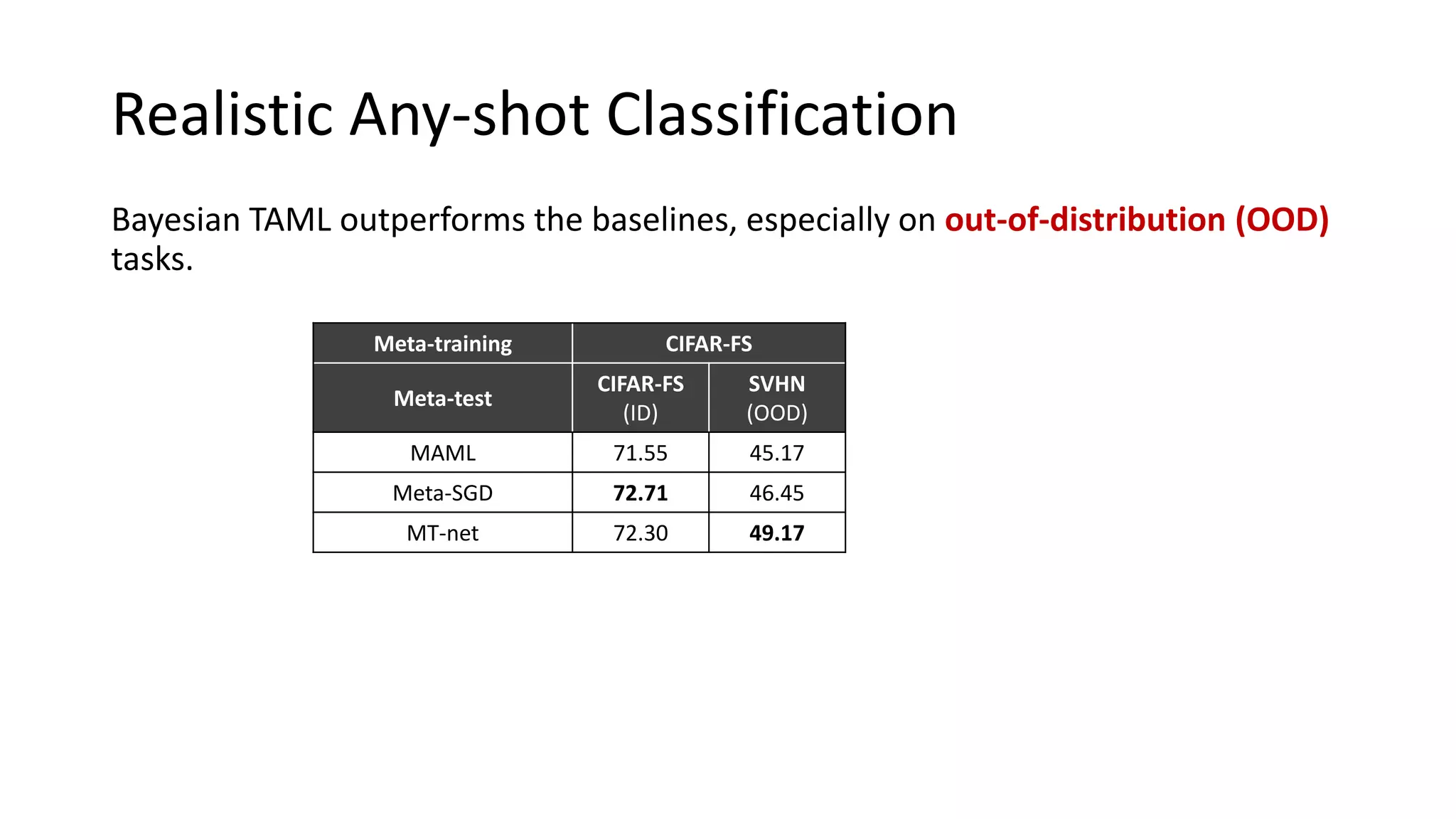
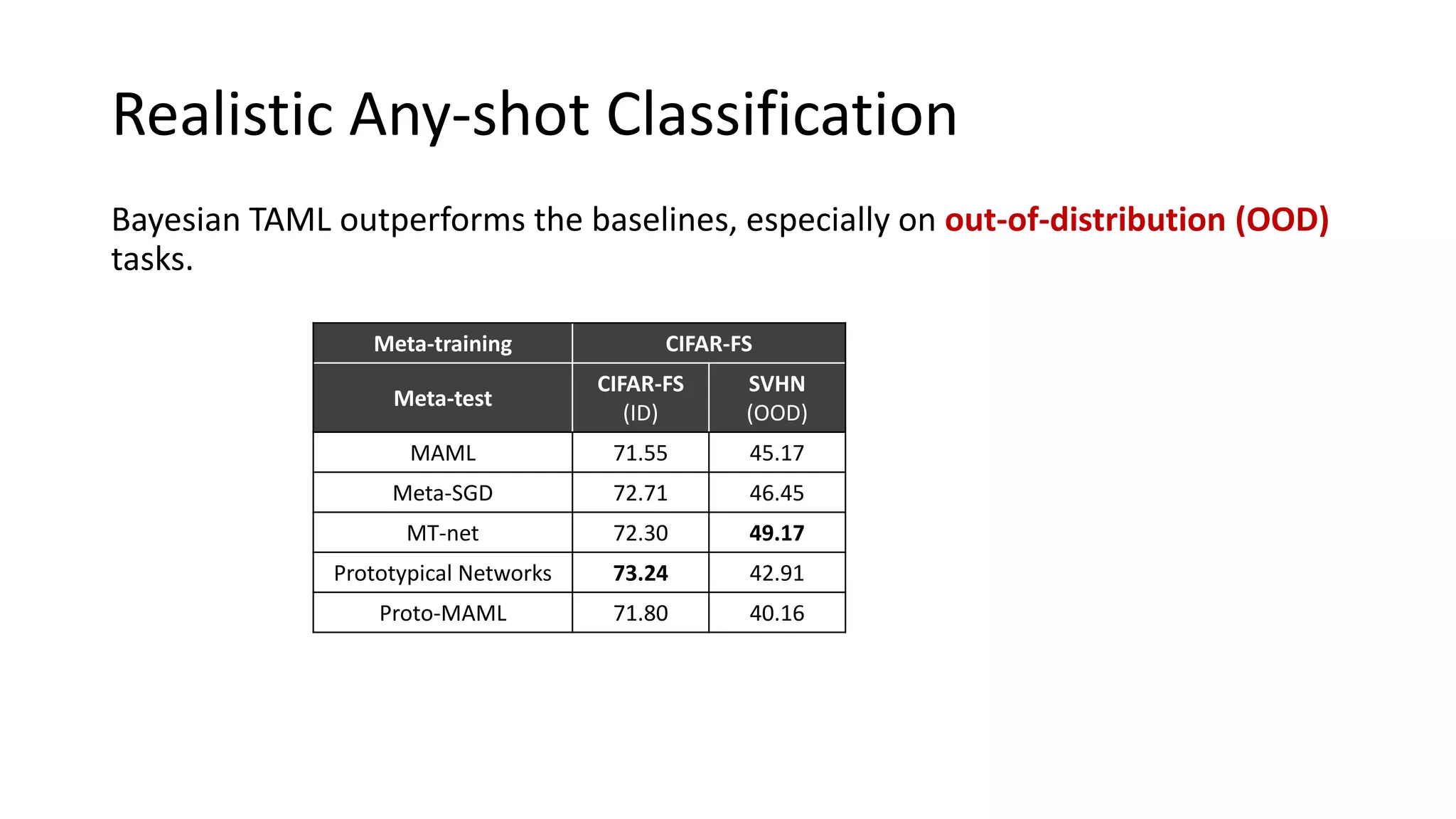
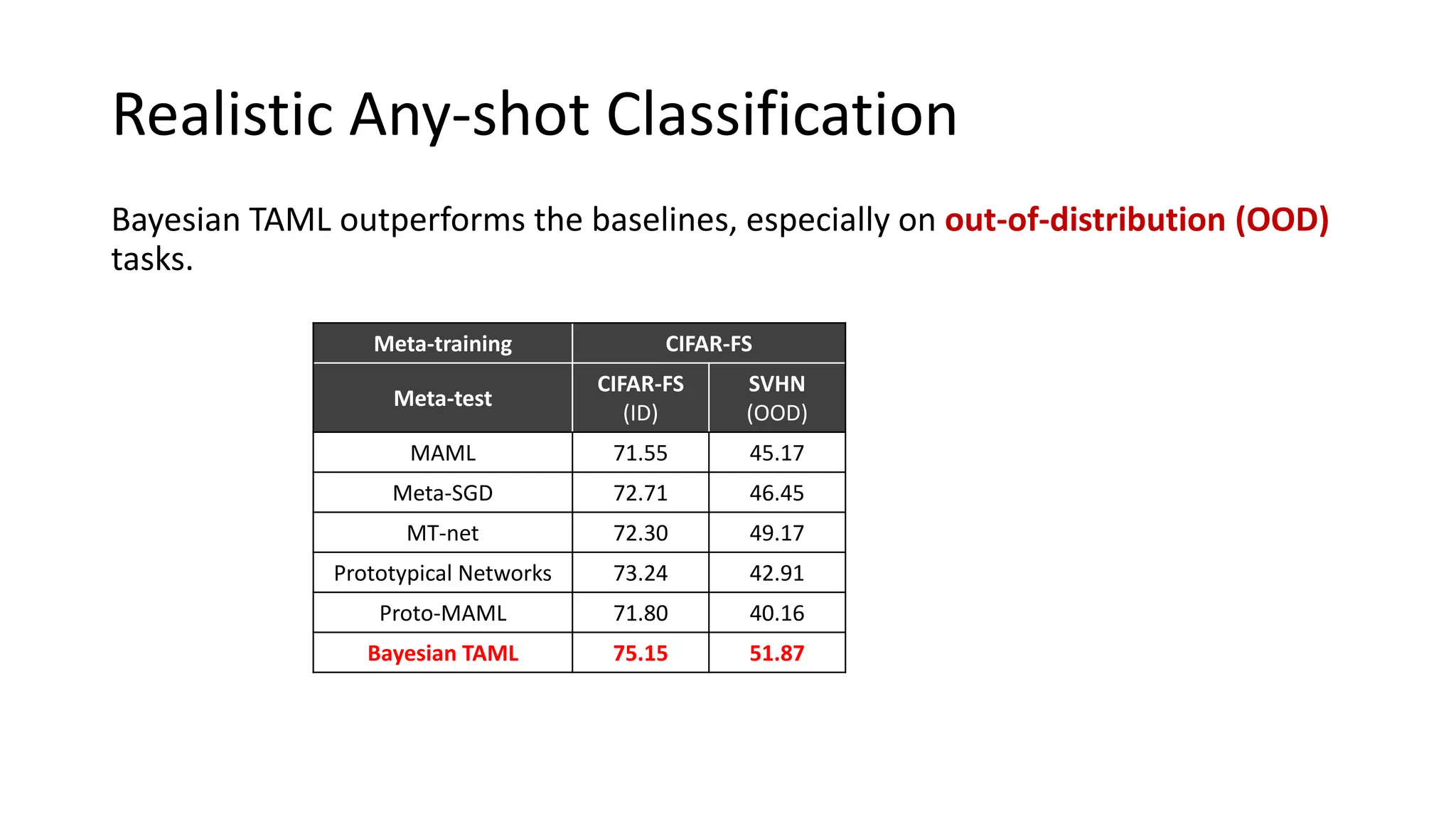
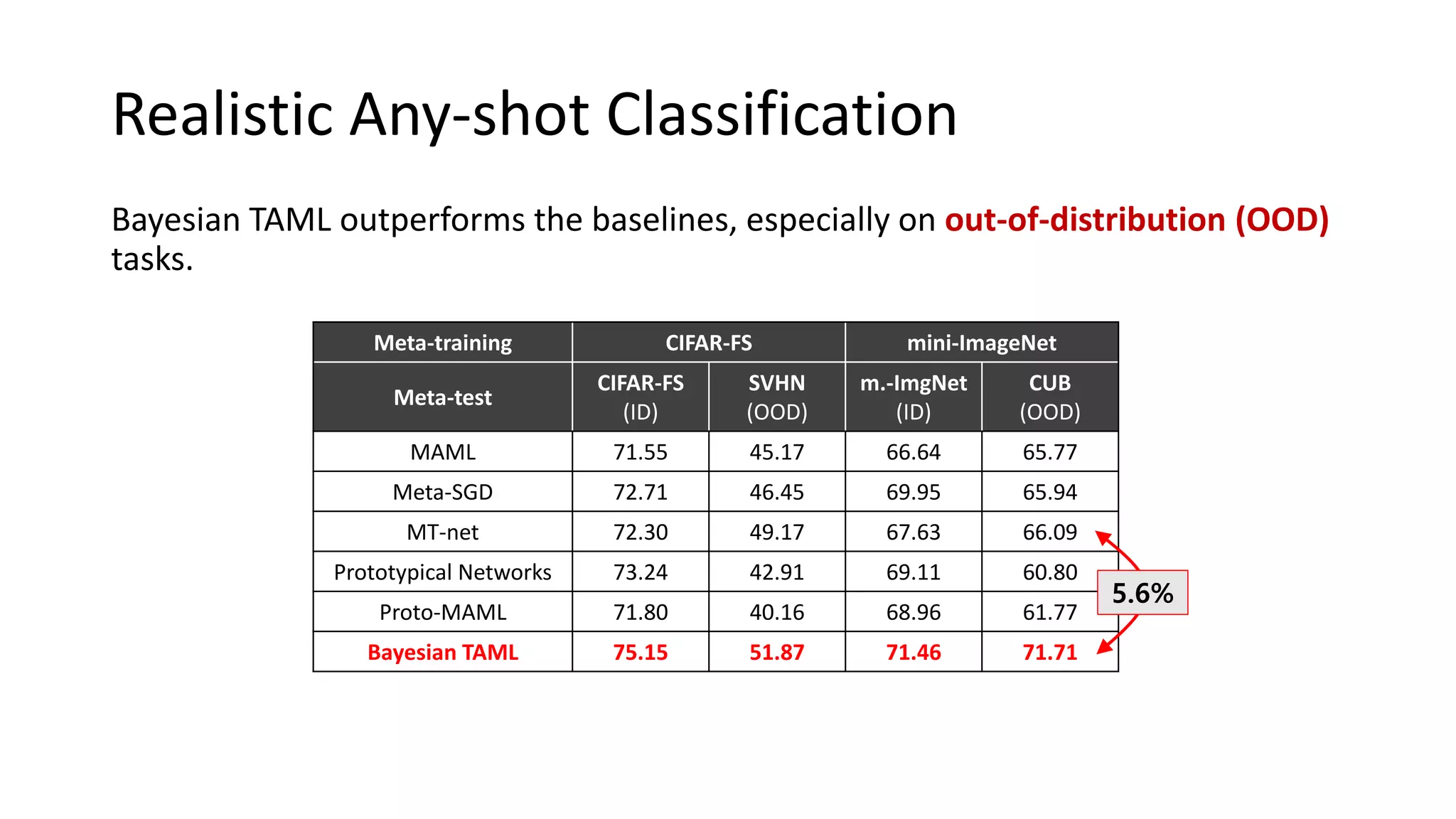
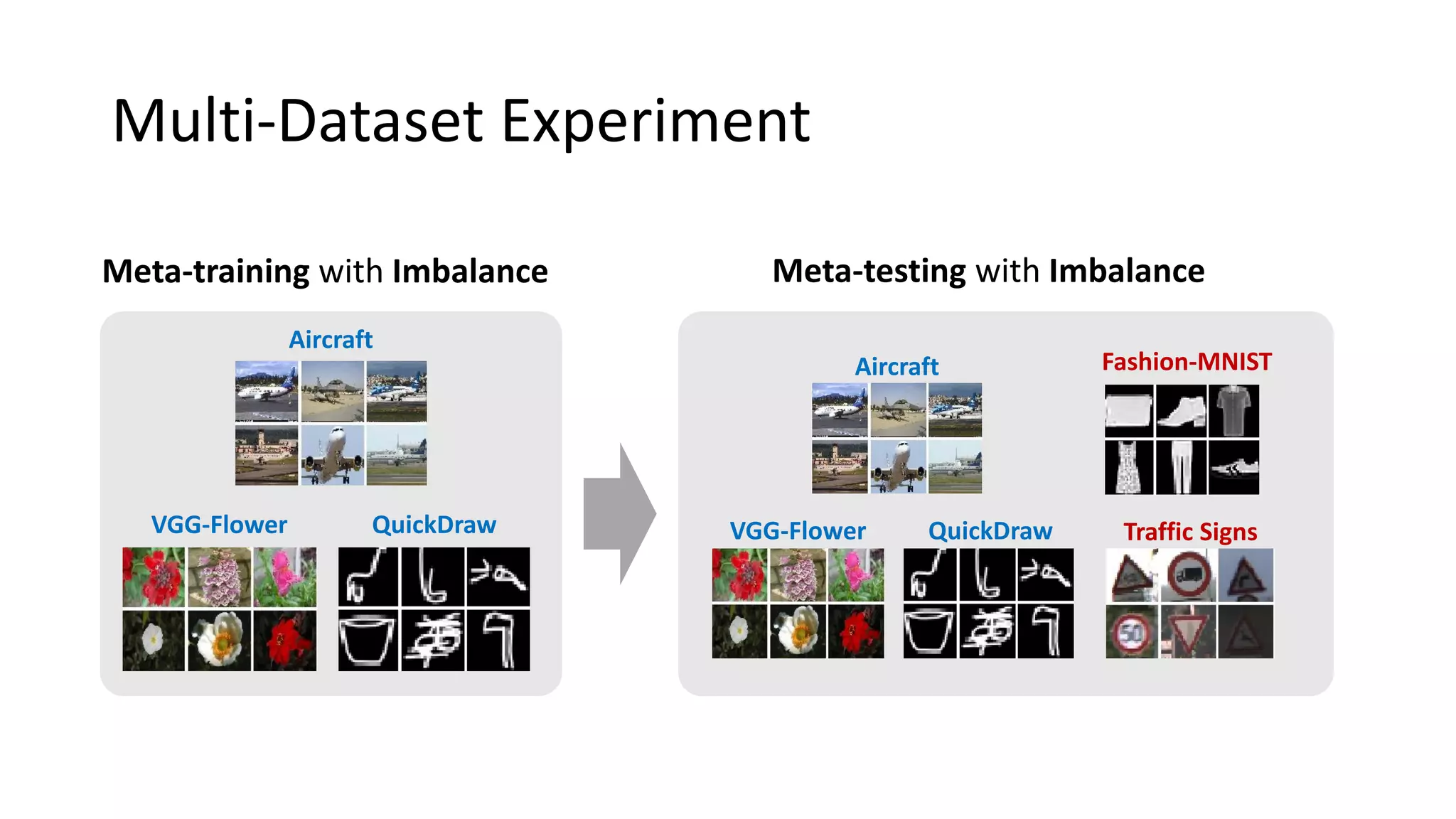
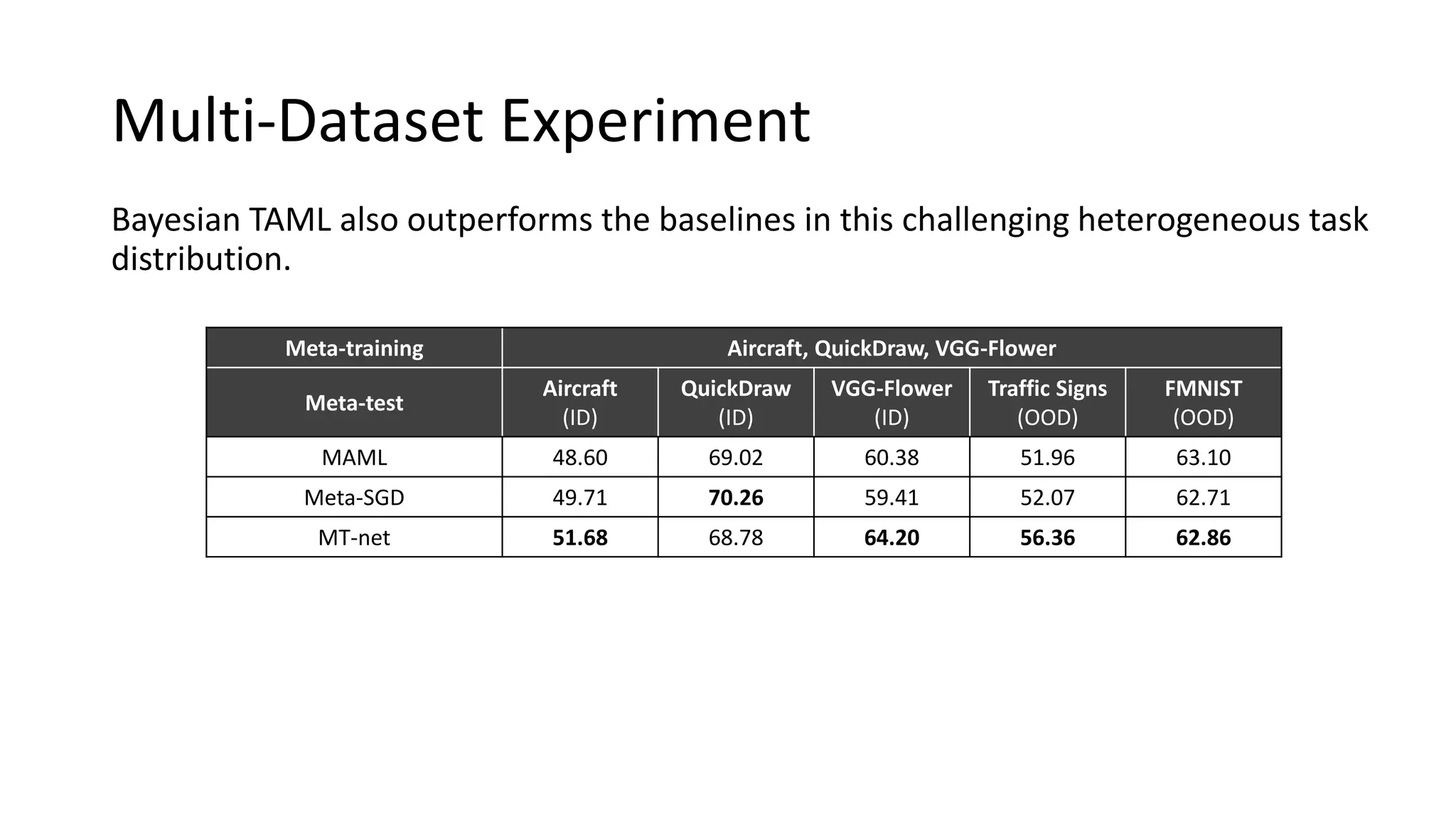
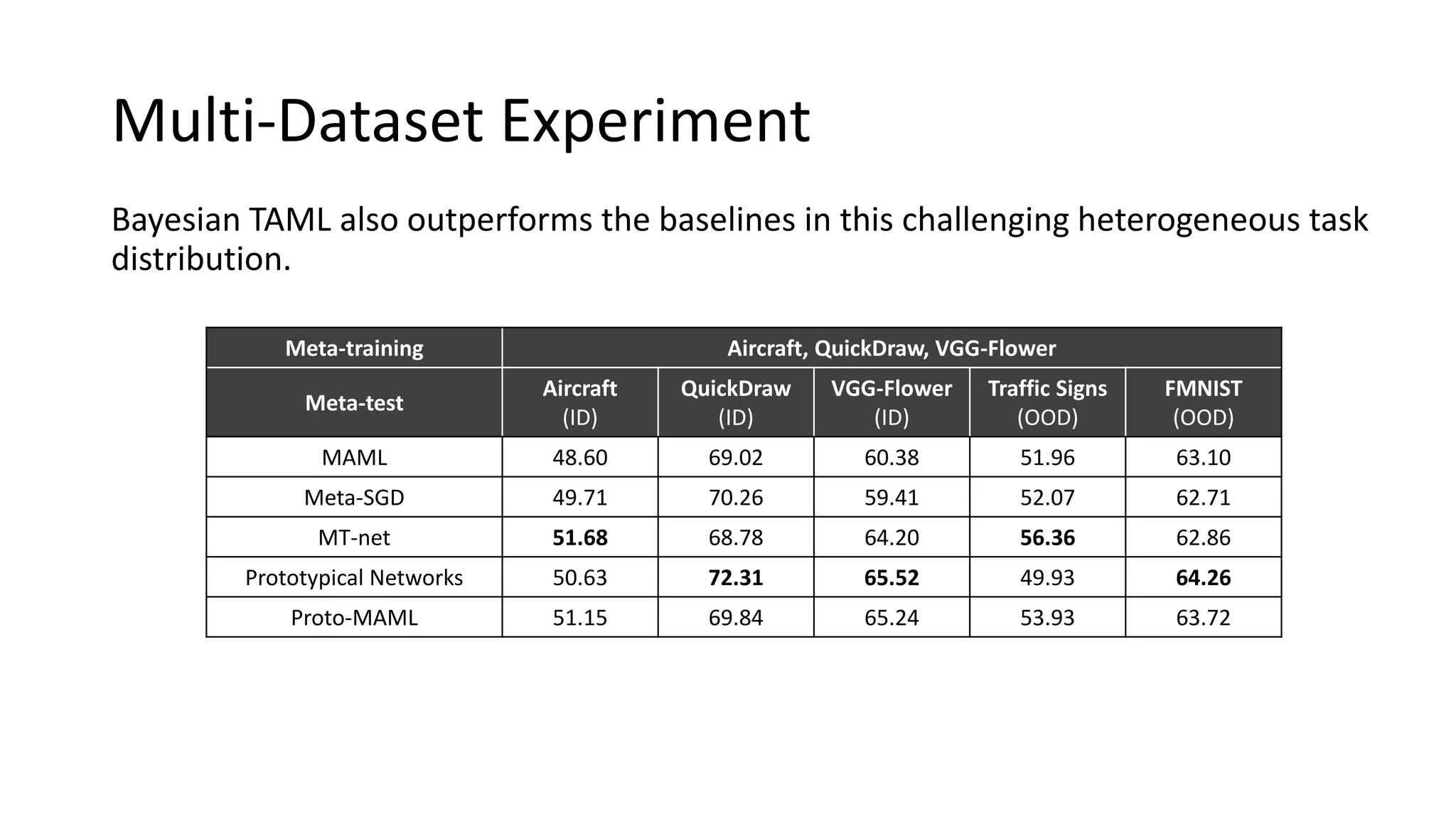
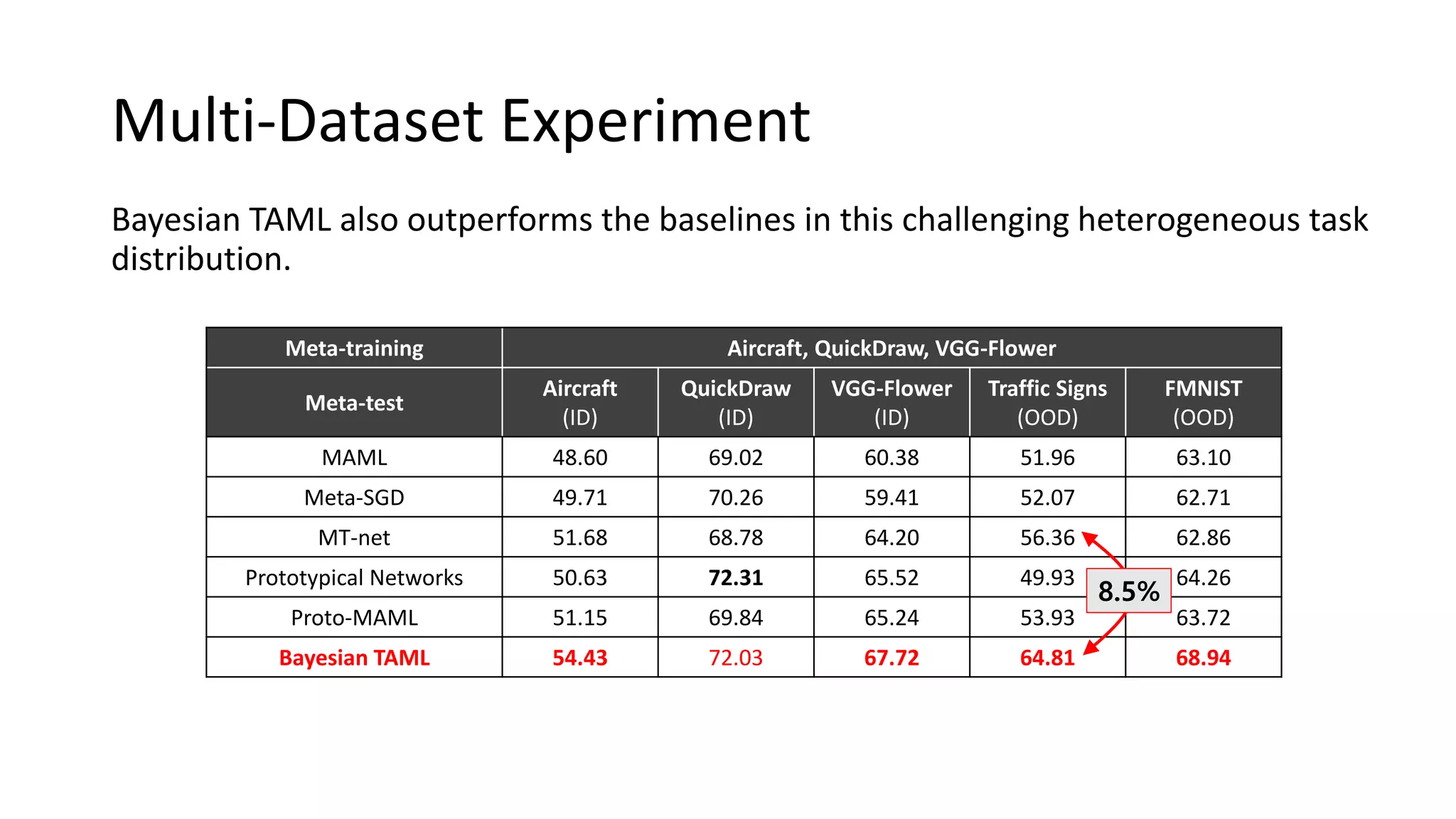
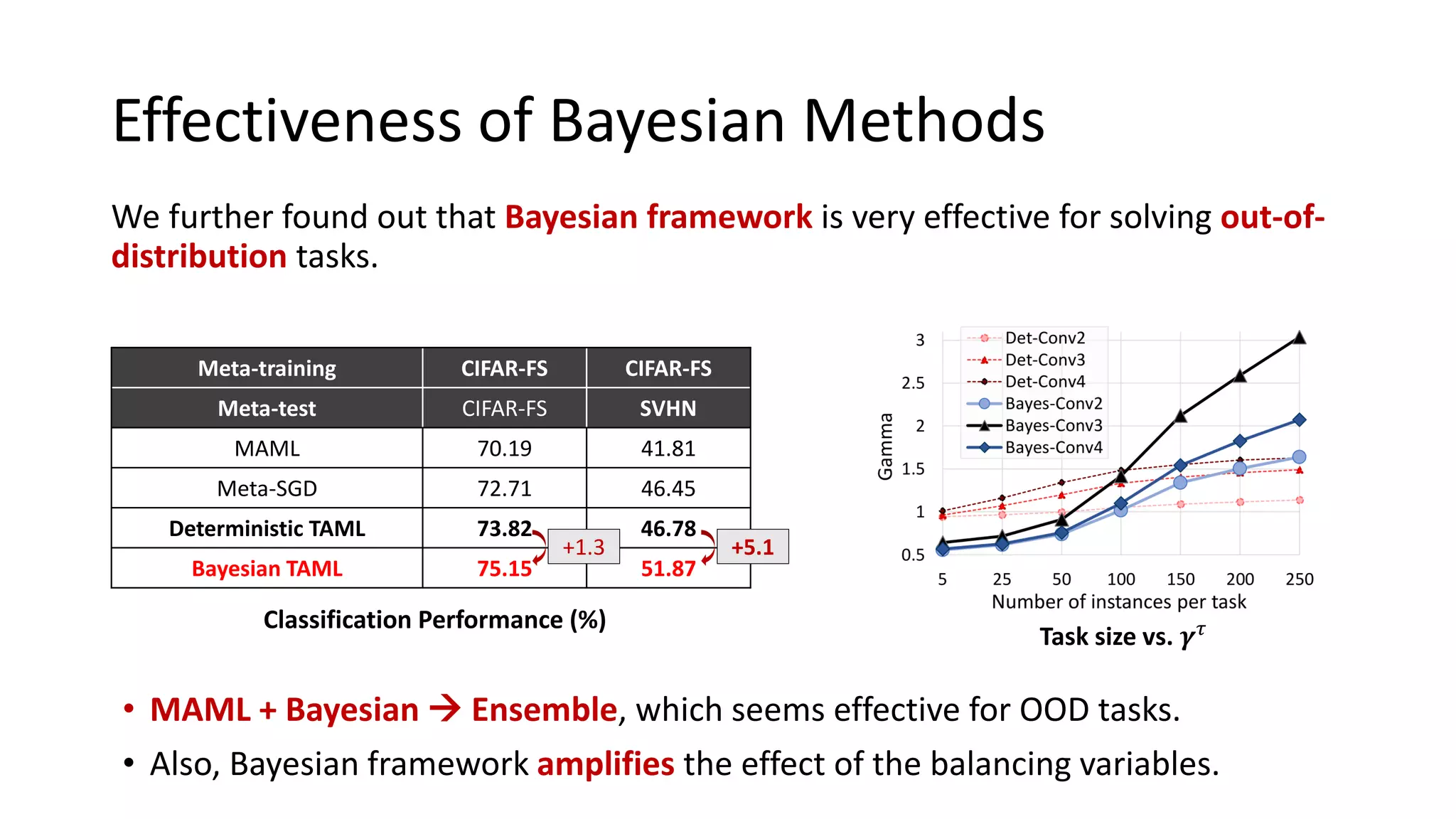
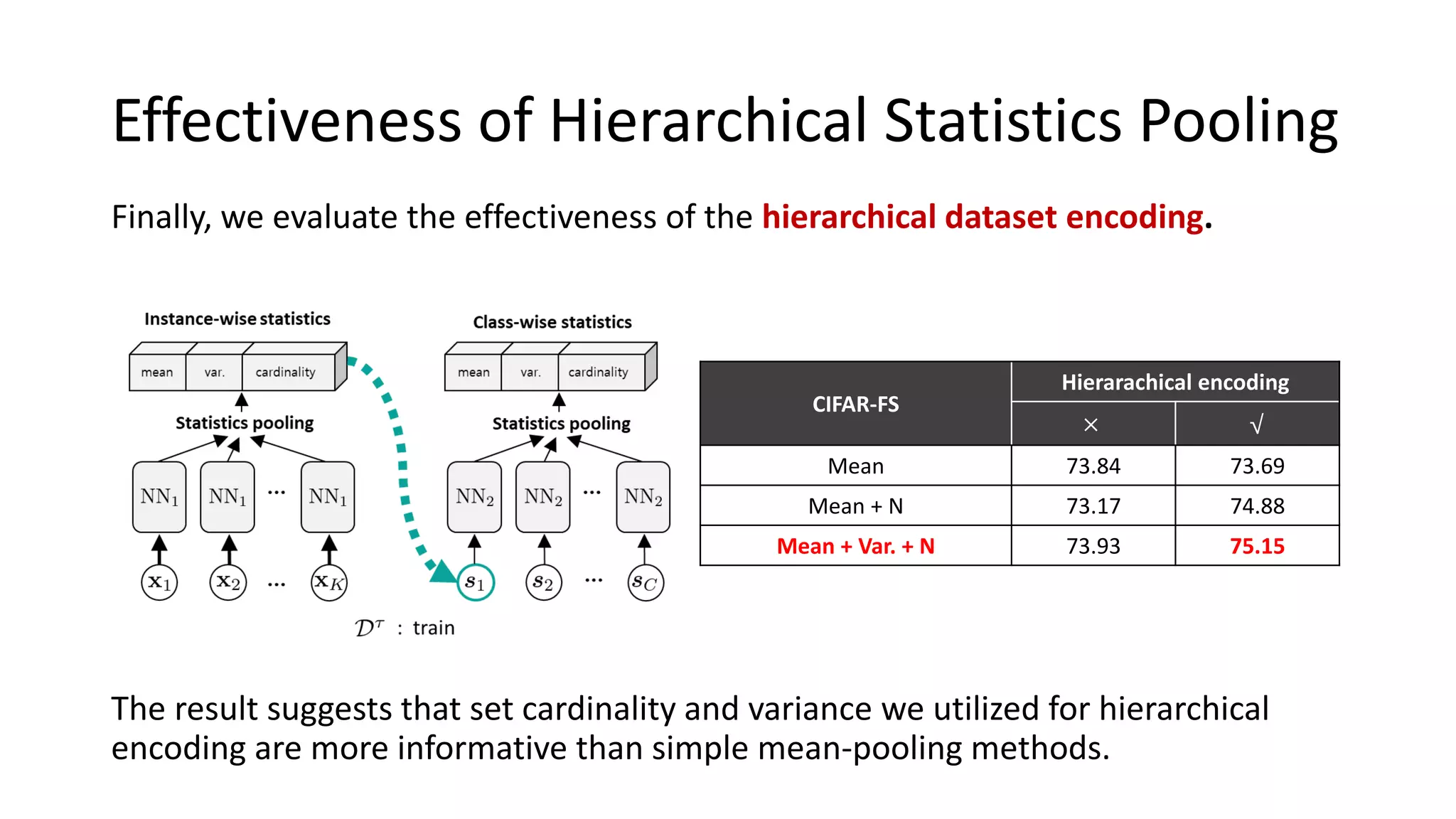
The document discusses Bayesian meta-learning methods for addressing challenges in few-shot learning, particularly regarding imbalanced and out-of-distribution tasks. It introduces techniques for balancing task-specific learning through the use of Bayesian frameworks and hierarchical statistics pooling to improve model performance. Experimental results demonstrate that the proposed methods, particularly Bayesian TAML, outperform traditional meta-learning approaches, especially in real-world scenarios with data imbalances and distributional shifts.

![Few-shot Learning
Humans can generalize even with a single observation of a class.
[Lake et al. 11] One shot Learning of Simple Visual Concepts, CogSci 2011
Observation
Query examples
Human](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-2-2048.jpg)
![Few-shot Learning
On the other hand, deep neural networks require large number of training instances
to generalize well, and overfits with few training instances.
Few-shot
learning
Observation
Deep Neural Networks
How can we learn a model that generalize well even with few training instances?
Human
Query examples
[Lake et al. 11] One shot Learning of Simple Visual Concepts, CogSci 2011](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-3-2048.jpg)
![Meta-Learning for few-shot classification
Humans generalize well because we never learn from scratch.
→ Learn a model that can generalize over a task distribution!
Few-shot Classification
Knowledge
Transfer !
Meta-training
Meta-test
Test
Test
Training Test
Training
Training
: meta-knowledge
[Ravi and Larochelle. 17] Optimization as a Model for Few-shot Learning, ICLR 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-4-2048.jpg)
![Model-Agnostic Meta-Learning
Model Agnostic Meta Learning (MAML) aims to find initial model parameter
that can rapidly adapt to any tasks only with a few gradient steps.
[Finn et al. 17] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, ICML 2017
Task-specific
parameter
Task-specific
parameter
Task-specific
parameter
Initial model
parameter
𝐷1
𝐷2 𝐷3](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-5-2048.jpg)
![Model-Agnostic Meta-Learning
Model Agnostic Meta Learning (MAML) aims to find initial model parameter
that can rapidly adapt to any tasks only with a few gradient steps.
[Finn et al. 17] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, ICML 2017
Initial model
parameter
Task-specific
parameter
Task-specific
parameter
Task-specific
parameter
Task-specific parameter
for a novel task
𝐷1
𝐷2 𝐷3
𝐷∗](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-6-2048.jpg)
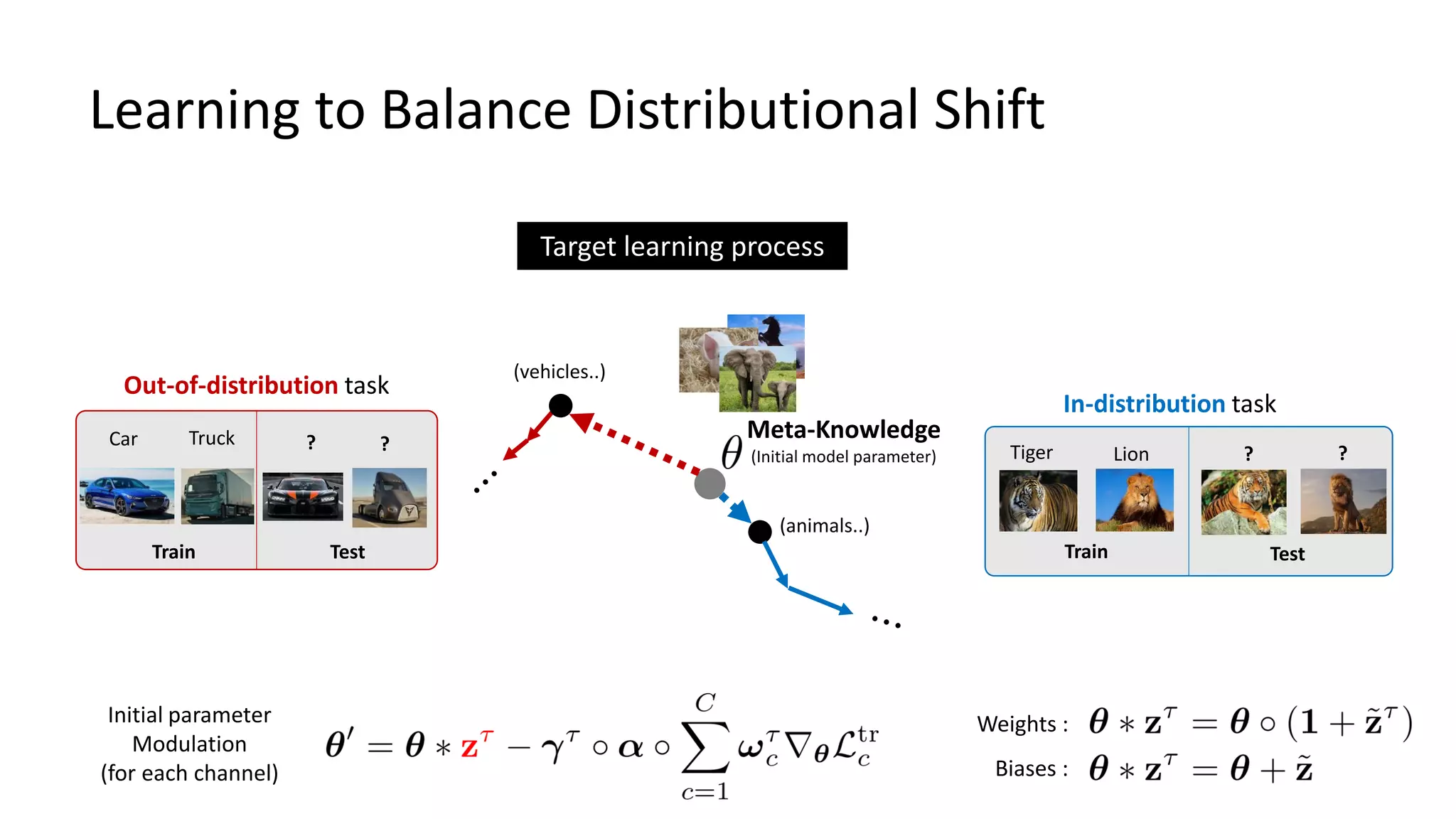
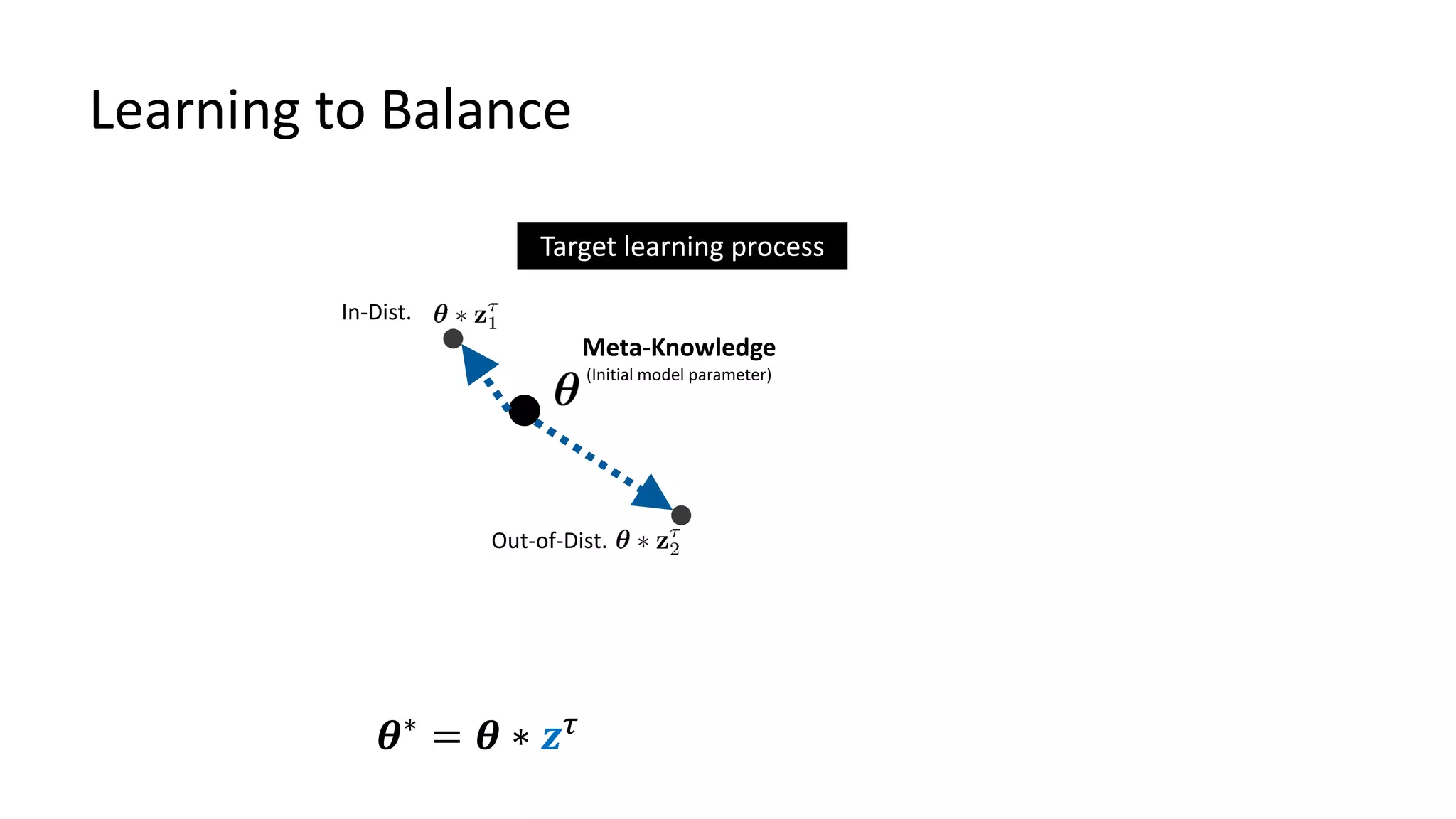
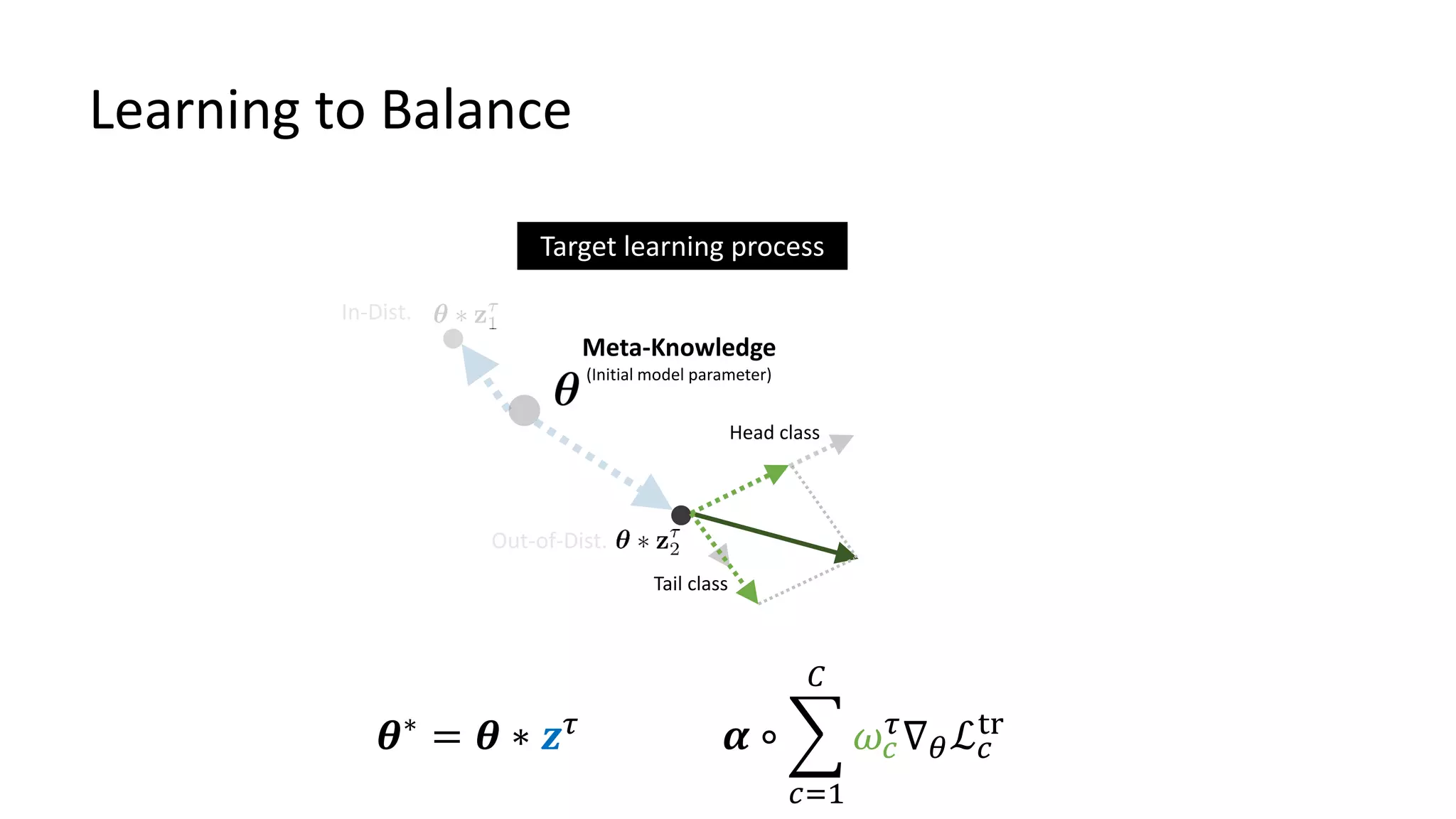
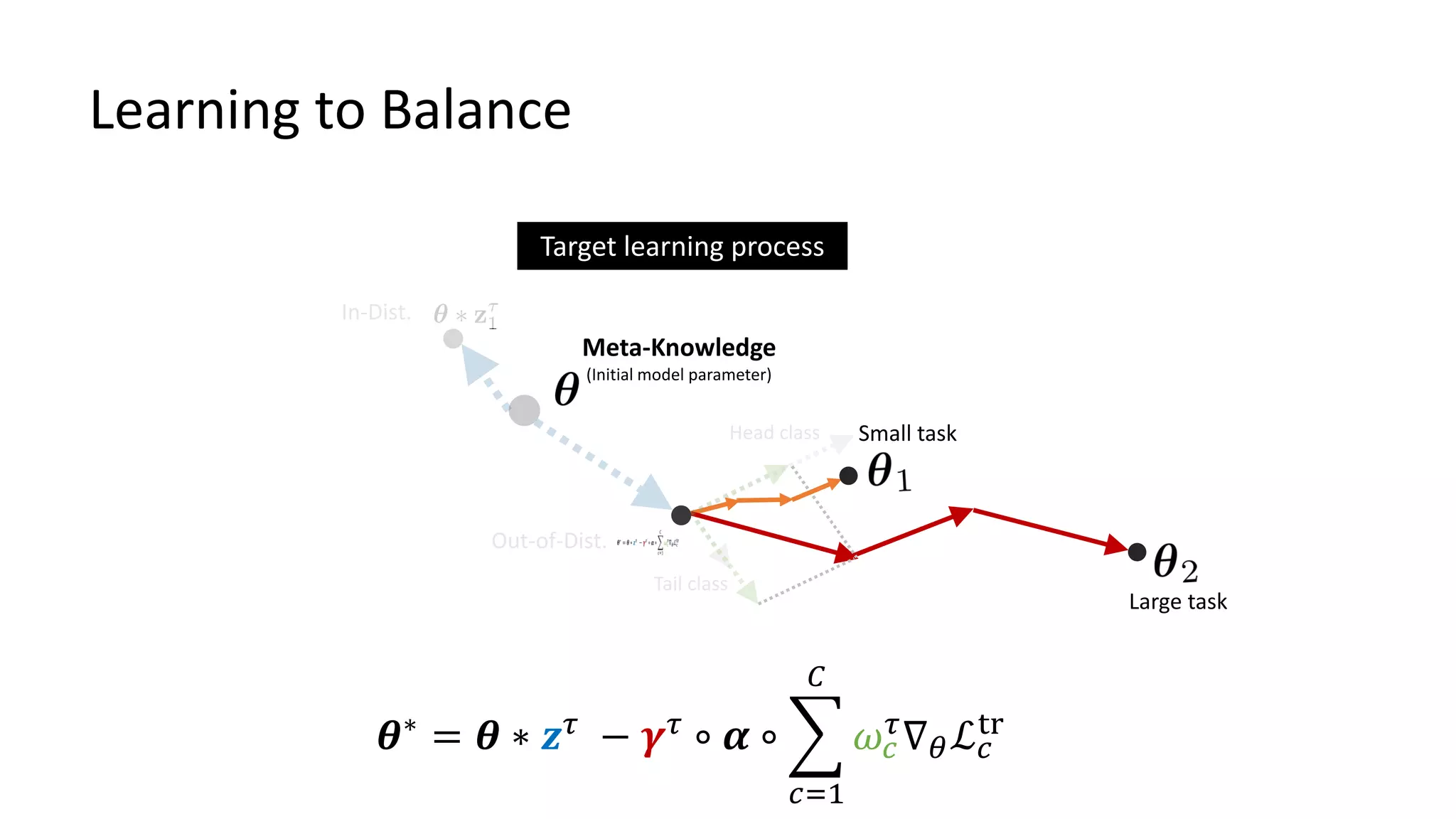
![Bayesian TAML
Generative Process
Bayesian framework [1][2]
• Allows robust inference on the latent variables.
• In MAML → results in the ensemble of diverse task-specific predictors [3].
[1] Finn et al., Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
[2] Gordon et al., Meta-Learning Probabilistic Inference For Prediction, ICLR 2019
TrainTest
[3] Lakshminarayanan et al., Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, NIPS 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-15-2048.jpg)
![Bayesian TAML
Generative Process
Bayesian framework [1][2]
• Allows robust inference on the latent variables.
• In MAML → results in the ensemble of diverse task-specific predictors [3].
[1] Finn et al., Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
[2] Gordon et al., Meta-Learning Probabilistic Inference For Prediction, ICLR 2019
TrainTest
[3] Lakshminarayanan et al., Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, NIPS 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-16-2048.jpg)
![Bayesian TAML
Generative Process
Bayesian framework [1][2]
• Allows robust inference on the latent variables.
• In MAML → results in the ensemble of diverse task-specific predictors [3].
[1] Finn et al., Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
[2] Gordon et al., Meta-Learning Probabilistic Inference For Prediction, ICLR 2019
TrainTest
[3] Lakshminarayanan et al., Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, NIPS 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-17-2048.jpg)
![Bayesian TAML
Generative Process
Bayesian framework [1][2]
• Allows robust inference on the latent variables.
• In MAML → results in the ensemble of diverse task-specific predictors [3].
[1] Finn et al., Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
[2] Gordon et al., Meta-Learning Probabilistic Inference For Prediction, ICLR 2019
TrainTest
[3] Lakshminarayanan et al., Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, NIPS 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-18-2048.jpg)
![Bayesian TAML
Generative Process
Bayesian framework [1][2]
• Allows robust inference on the latent variables.
• In MAML → results in the ensemble of diverse task-specific predictors [3].
[1] Finn et al., Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
[2] Gordon et al., Meta-Learning Probabilistic Inference For Prediction, ICLR 2019
TrainTest
[3] Lakshminarayanan et al., Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, NIPS 2017](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-19-2048.jpg)
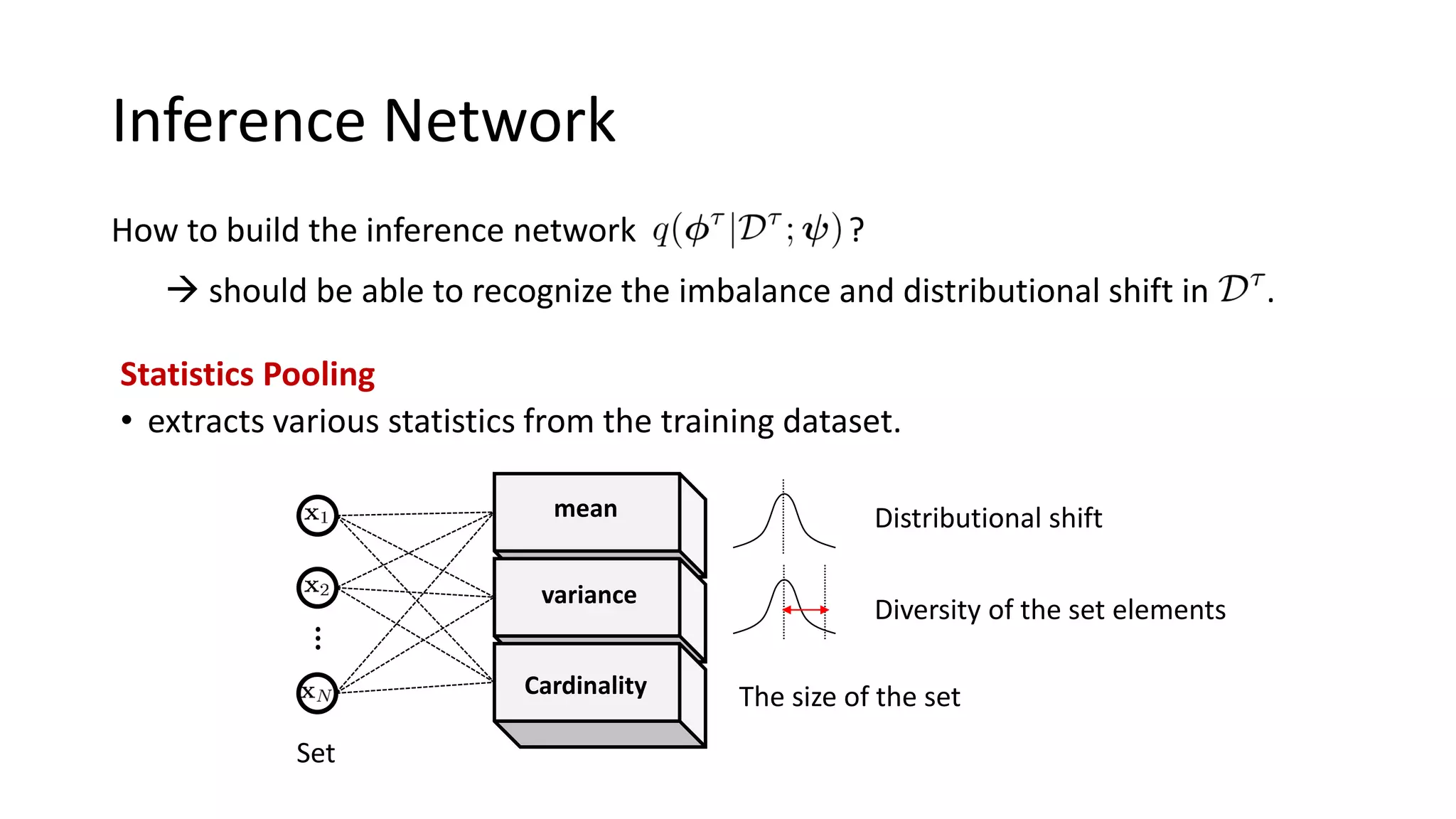
![Variational Inference
Inference
TrainTest
dependent only
on training dataset [1]
[1] Ravi and Beatson, Amortized Bayesian Meta-Learning, ICLR 2019
Generative Process
TrainTest
Variational
distribution
We cannot access to the test label at meta-testing time.
→ Variational distribution should not have dependency on the test set.](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-20-2048.jpg)

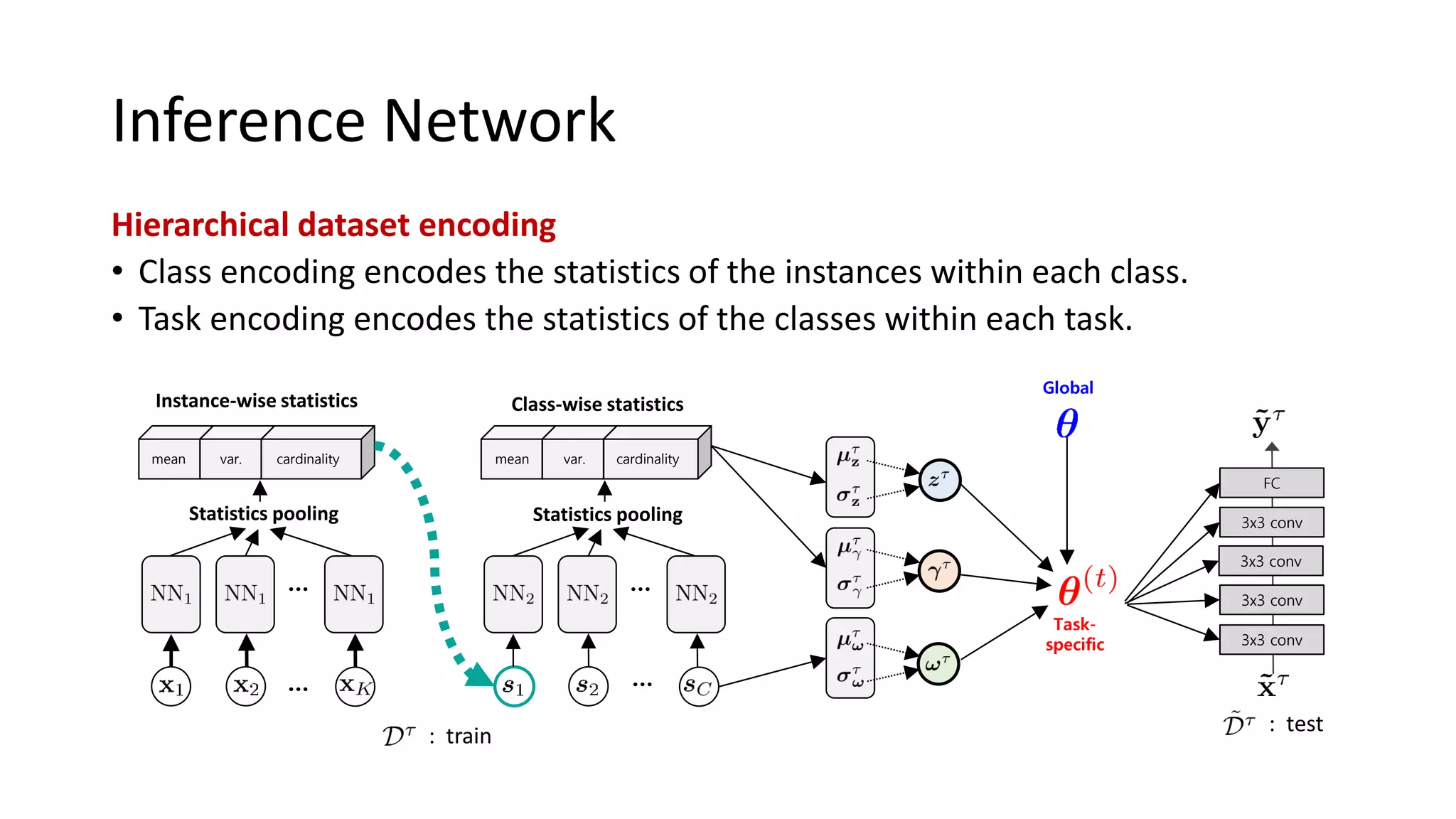
![𝒛 𝜏 for Distributional Shift
Meta-training CIFAR-FS miniImageNet
Meta-test SVHN CUB
MAML 45.17 65.77
Meta-SGD 46.45 65.94
Bayesian z-TAML 52.29 69.11
Large task
Classification Performance (%)
TSNE visualization of 𝔼[𝒛 𝜏
]
Initial
parameter
𝒛-TAML: Meta-SGD + 𝒛 𝜏](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-33-2048.jpg)
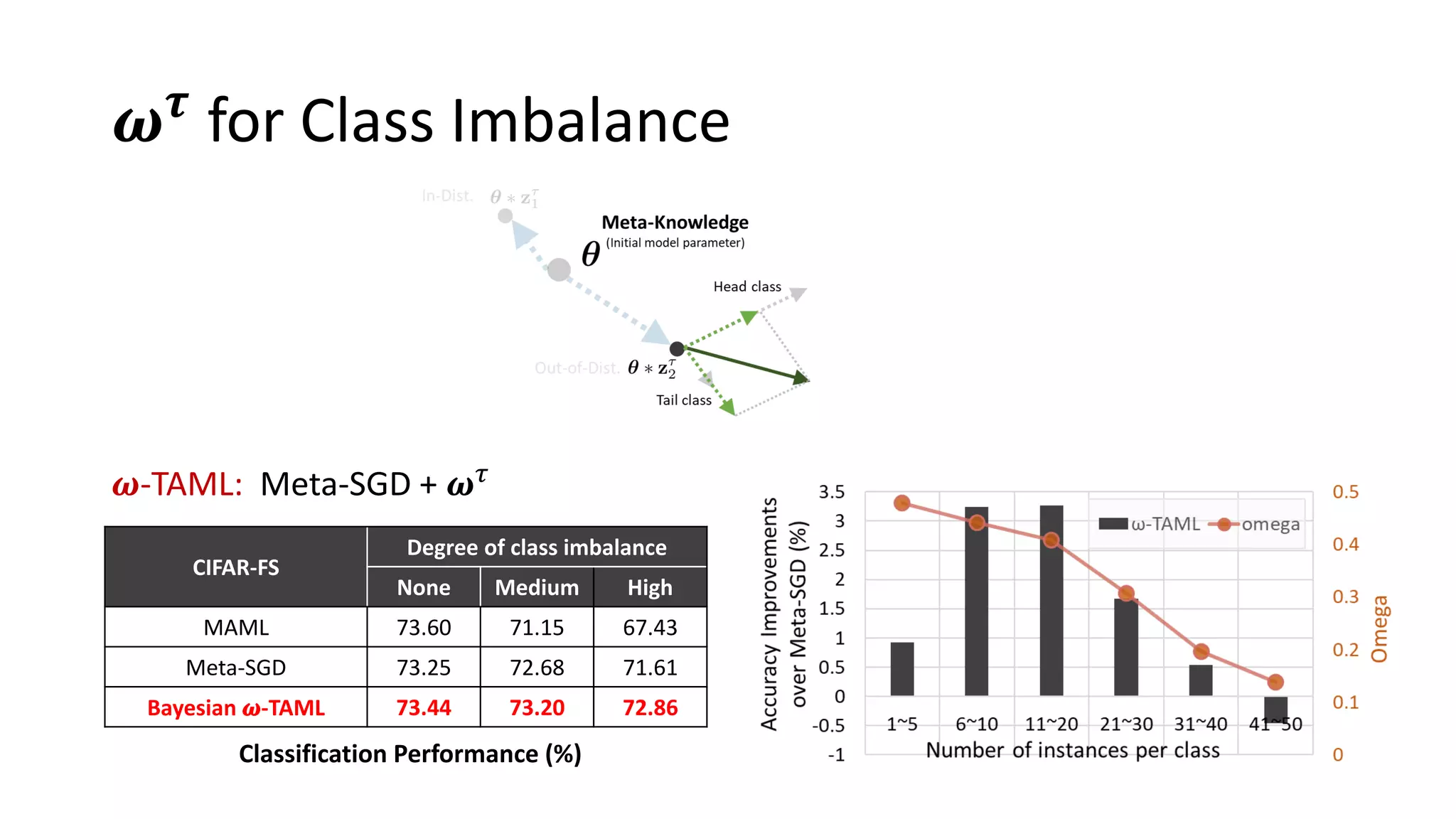
![𝜸 𝜏 for Task Imbalance
Task size vs. Acc. Task size vs. 𝔼[𝜸 𝝉
]
𝜸-TAML: Meta-SGD + 𝜸 𝜏](https://image.slidesharecdn.com/learningtobalancebayesianmeta-learningforimbalancedandout-of-distributiontasks-200529022020/75/Learning-to-Balance-Bayesian-Meta-Learning-for-Imbalanced-and-Out-of-distribution-Tasks-35-2048.jpg)



![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/pvrcnn-200311050009-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]物理学による帰納バイアスを組み込んだダイナミクスモデル作成に関する論文まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/physicsinductivebias1-200703042625-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DL輪読会] off-policyなメタ強化学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190405journalclub-190415082841-thumbnail.jpg?width=640&height=640&fit=bounds)









































