More Related Content

PPTX
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会) 
PPTX

PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会 
PDF

PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜 ![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an... What's hot

PPTX

PPTX

PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) ![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法 
PDF

PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PPTX

PPTX

PDF
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用 
PPTX
Curriculum Learning (関東CV勉強会) 
PDF
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会) 
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc) ![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions 
PDF
Reinforcement Learning @ NeurIPS2018 
PDF

PDF

PDF
Similar to Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning 
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) 
PDF
Inverse Reward Design の紹介 
PPTX
【輪読会】Braxlines: Fast and Interactive Toolkit for RL-driven Behavior Engineeri... ![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Dl輪読会]introduction of reinforcement learning 
PDF

PDF

PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み 
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料) 
PPTX
Multi-agent Inverse reinforcement learning: 相互作用する行動主体の報酬推定 
PPTX

PDF

PDF
Reinforcement Learning: An Introduction 輪読会第1回資料 
PDF
Top-K Off-Policy Correction for a REINFORCE Recommender System 
PDF

PPTX

PDF

PPTX

PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning 
PPTX
マルチエージェント強化学習 (MARL) と M^3RL Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
- 1.
- 2.
- 3.
発表の構成
はじめに
3
1. IRLによる報酬関数の推定
• 線形関数の推定
•非線形関数の推定
2. 最大エントロピーの原理による解の曖昧さへの対処
• Maximum Entropy IRL(線形関数)
• Maximum Entropy Deep IRL(非線形関数)
3. 重要サンプリングによる分配関数Z(θ)の推定
• Relative Entropy IRL(線形関数,相対エントロピー最小化)
• Guided Cost Learning(非線形関数,Maximum Entropy)
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
Maximum Entropy IRL
2.最大エントロピーの原理による解の曖昧さへの対処
13
ラグランジュの未定乗数法で解くと次式が得られる.
軌跡が得られる確率は報酬の大きさに指数比例
この式に基づき に対して尤度最大化
- 14.
Maximum Entropy IRL
2.最大エントロピーの原理による解の曖昧さへの対処
14
対数尤度を勾配法で最大化
エキスパートと比較して
特徴期待値:小 → 重み:大きく更新
特徴期待値:大 → 重み:小さく更新
勾配の意味
- 15.
- 16.
Deep Maximum EntropyIRL
2. 最大エントロピーの原理による解の曖昧さへの対処
16
対数尤度を勾配法で最大化
エキスパートと比較して
状態を訪れる頻度:小 → 重み:報酬を大きく更新
状態を訪れる頻度:大 → 重み:報酬を小さく更新
勾配の意味
エキスパートが状態を訪れる頻度 θの元で状態を訪れる頻度
- 17.
- 18.
Deep Maximum EntropyIRL
2. 最大エントロピーの原理による解の曖昧さへの対処
18
勾配の計算方法
: から計算
: を更新するごとにDP or RLを行い計算
めちゃくちゃ大変!!!!!!
- 19.
Relative Entropy IRL
3.重要サンプリングによる分配関数の推定
19
DPやRLが必要なのは下の二つを計算したいから.
θに対する最適方策を使わずに上式を求めたい
最適方策が必要なければ試行錯誤が格段に減る!!
少し異なる問題設定を考える.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
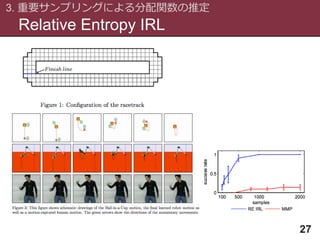
Relative Entropy IRL
3.重要サンプリングによる分配関数の推定
26
同じ環境で試行錯誤している→状態遷移確率が同じなので打ち消しあう
Zが求まる!!!
・軌跡をサンプリングする方策はランダム方策でも良い.
・報酬を更新する毎に最適方策を求める必要もない.
・状態遷移確率が分からなくても良い(モデルフリー)
- 27.
- 28.
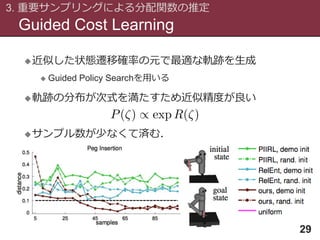
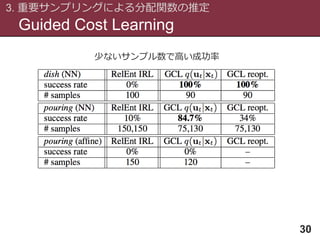
Guided Cost Learning
3.重要サンプリングによる分配関数の推定
28
Maximum Entropy IRLの問題設定でZを近似
Relative Entropy IRLでは状態遷移確率が消えた
Maximum Entropy IRLでは状態遷移確率が消えない
状態遷移確率を近似してP(ζ)を求める
- 29.
Guided Cost Learning
3.重要サンプリングによる分配関数の推定
29
近似した状態遷移確率の元で最適な軌跡を生成
Guided Policy Searchを用いる
軌跡の分布が次式を満たすため近似精度が良い
サンプル数が少なくて済む.
- 30.
- 31.
その他のIRL
31
IOC with Linearly-SolvableMDPs [Dvijotham 10]
モデルフリー,線形可解MDP
Deep IRL by Logistic Regression [Uchibe 16]
モデルフリー,線形可解MDP,非線形報酬関数
Generative Adversarial Imitation Learning [Ho 16]
モデルフリー,模倣学習,MaxEnt IRLと同じ方策
End-to-End Differentiable Adversarial Imitation Learning
[Baram 17]
状態遷移確率を学習し分散を減らすGAIL
- 32.



























![その他のIRL
31
IOC with Linearly-Solvable MDPs [Dvijotham 10]
モデルフリー,線形可解MDP
Deep IRL by Logistic Regression [Uchibe 16]
モデルフリー,線形可解MDP,非線形報酬関数
Generative Adversarial Imitation Learning [Ho 16]
モデルフリー,模倣学習,MaxEnt IRLと同じ方策
End-to-End Differentiable Adversarial Imitation Learning
[Baram 17]
状態遷移確率を学習し分散を減らすGAIL](https://image.slidesharecdn.com/maxdeeprelguided-170905142400/85/Maximum-Entropy-IRL-31-320.jpg)
