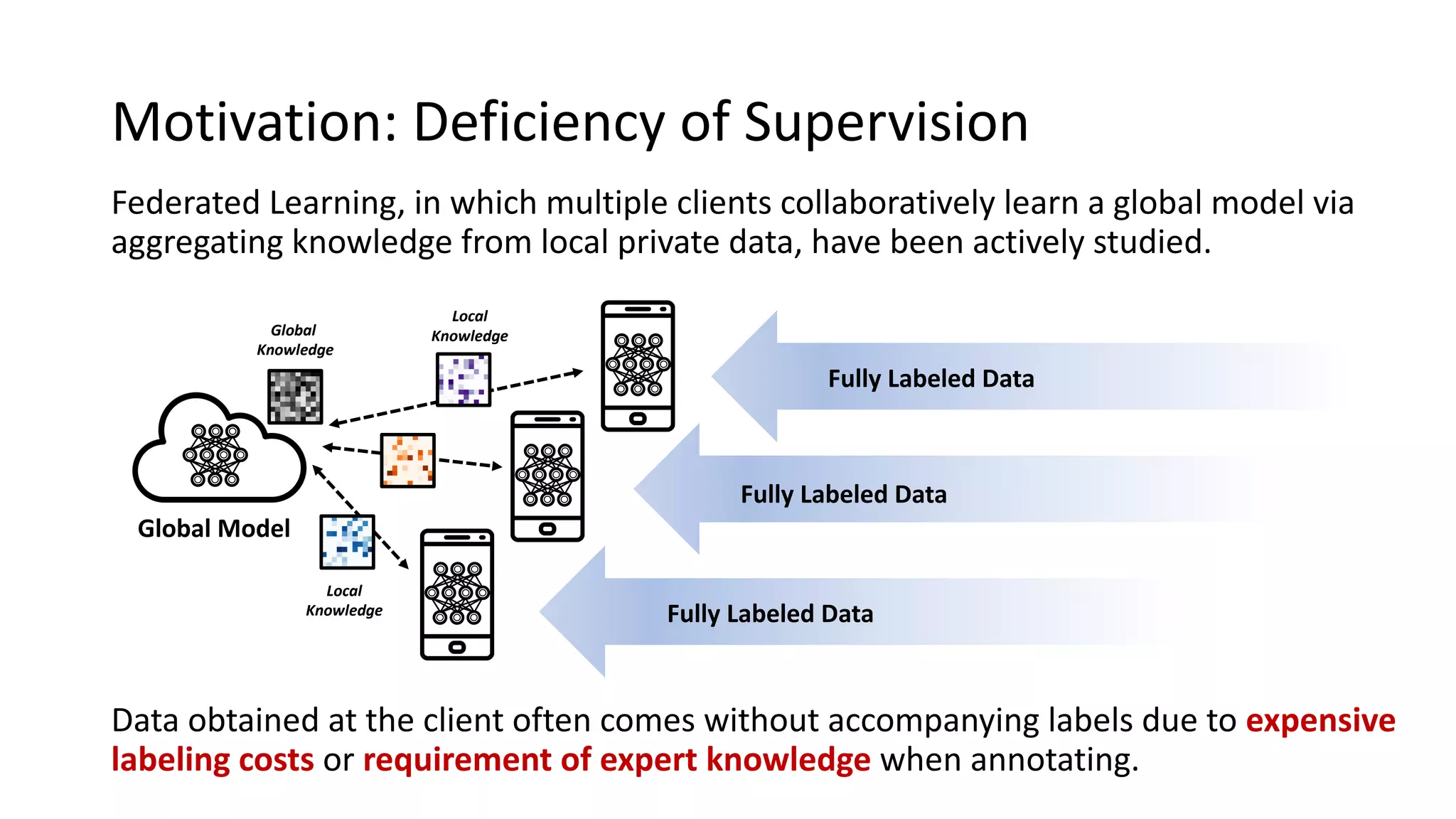
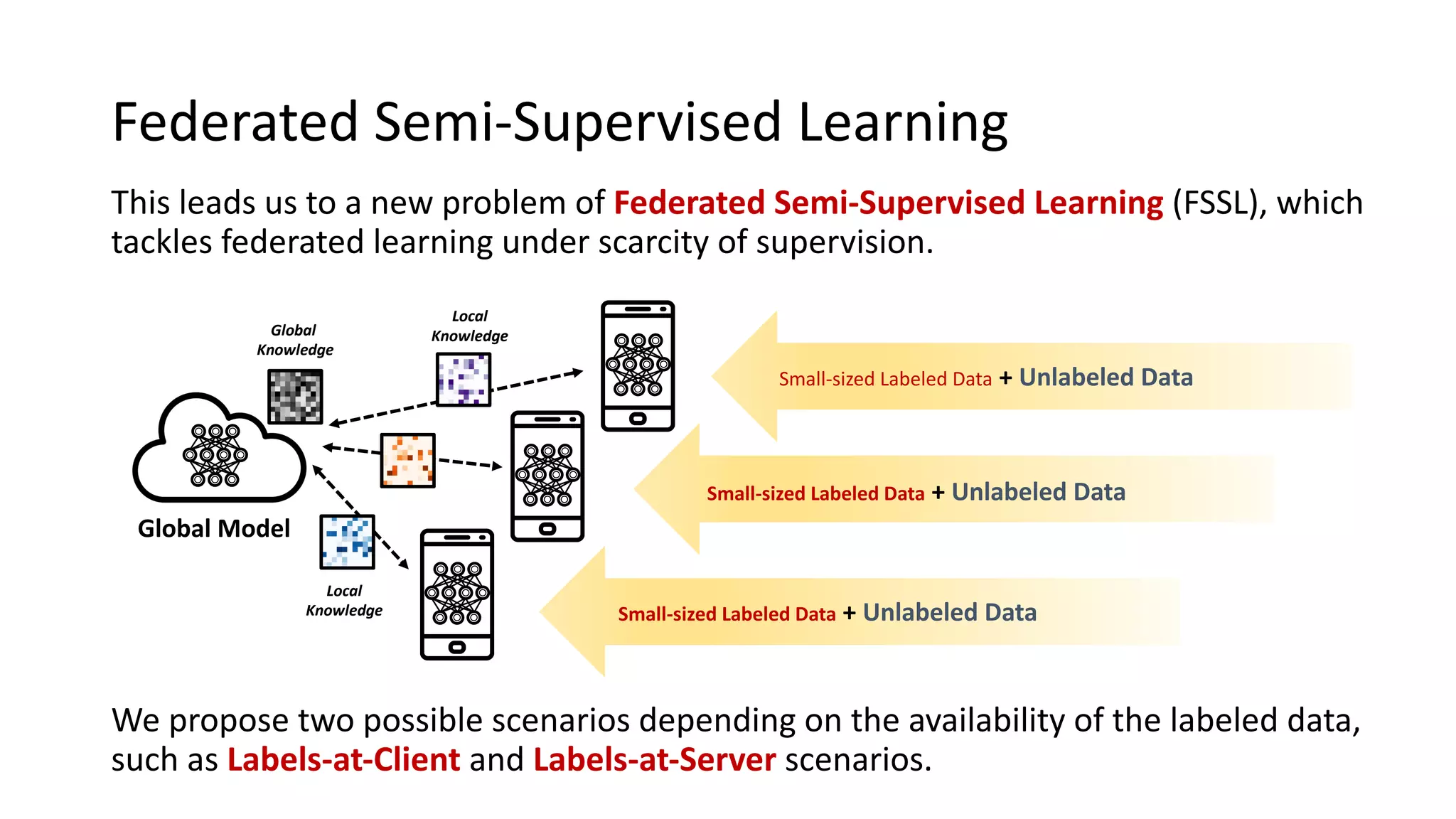
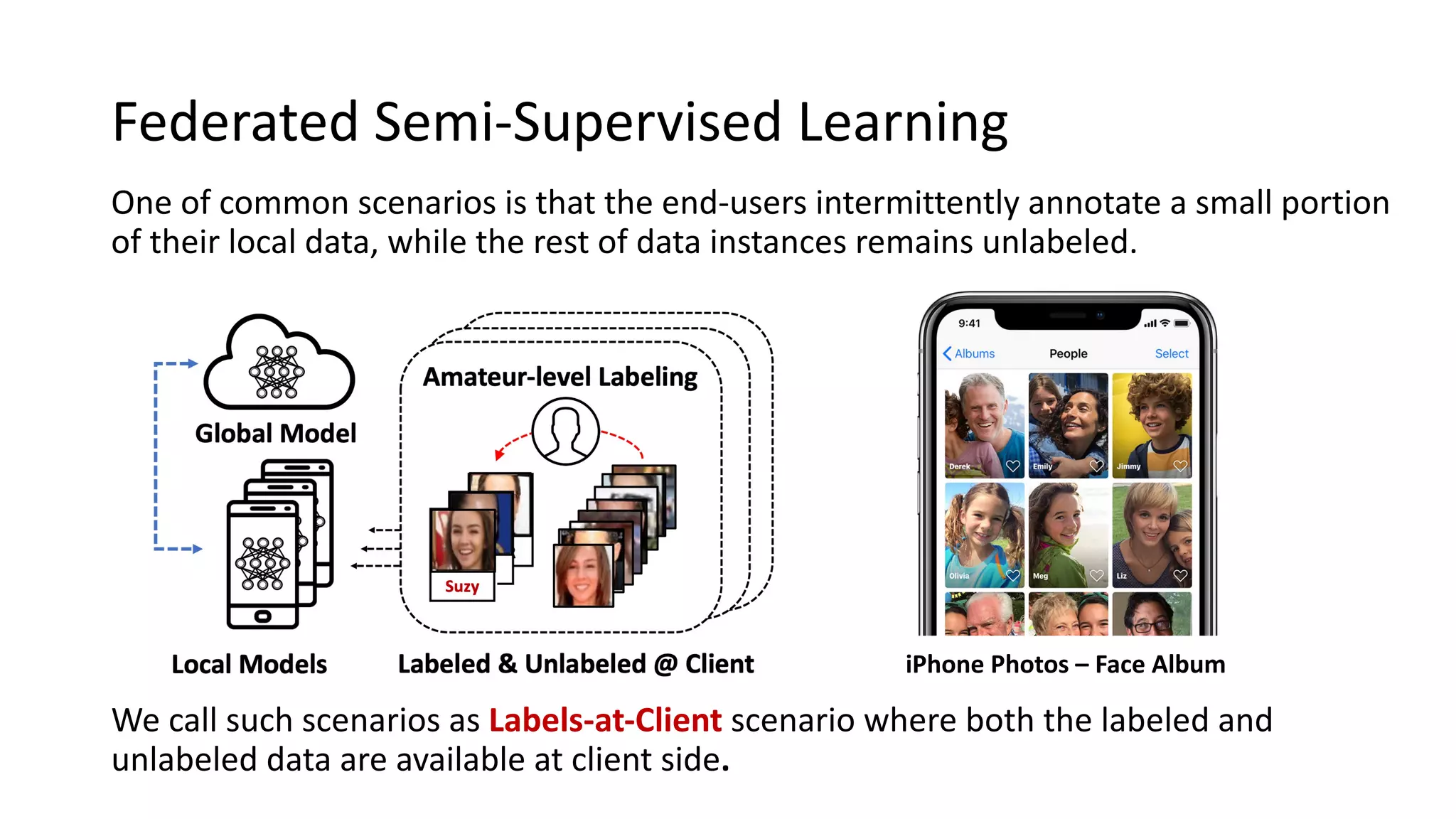
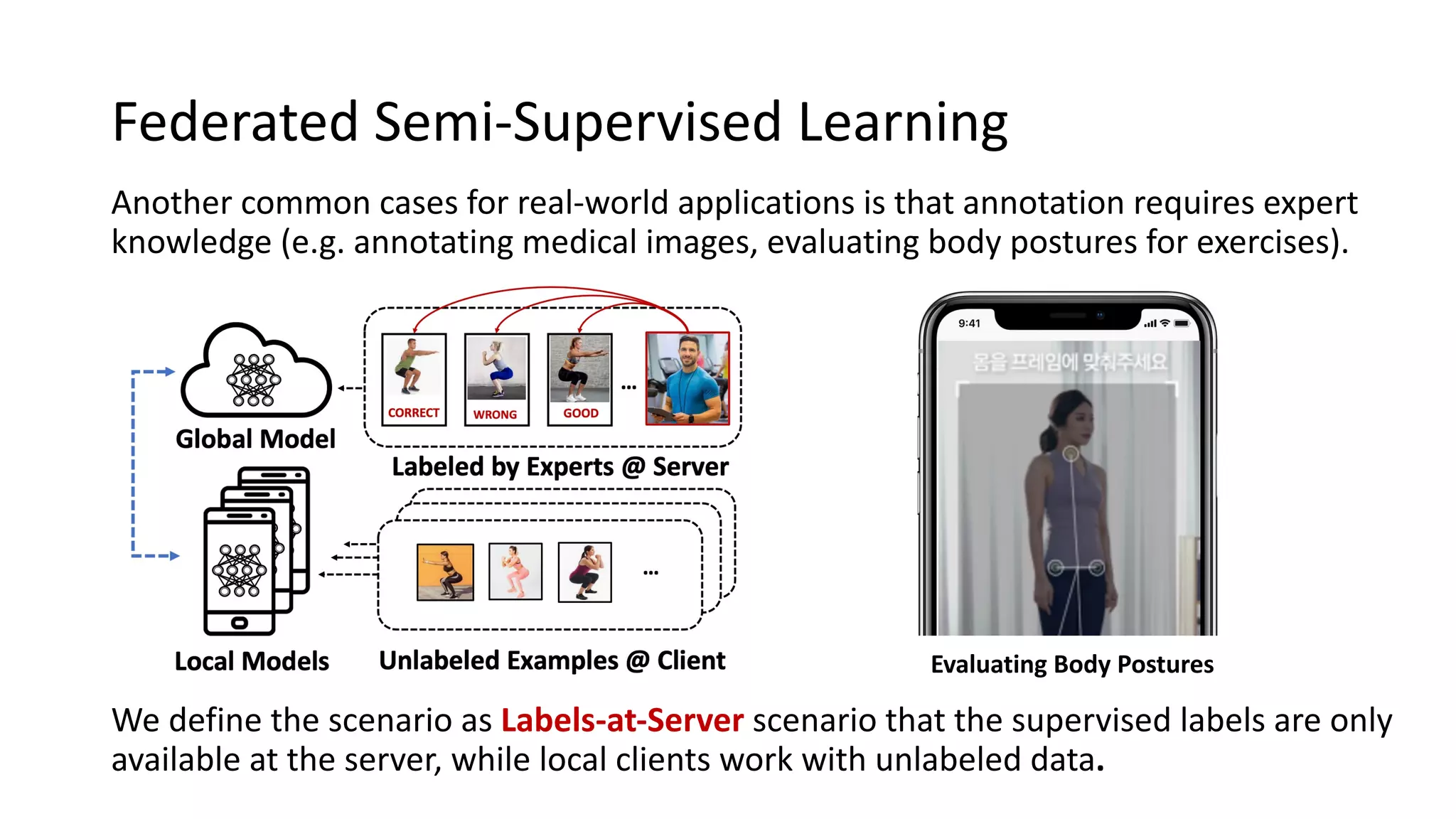
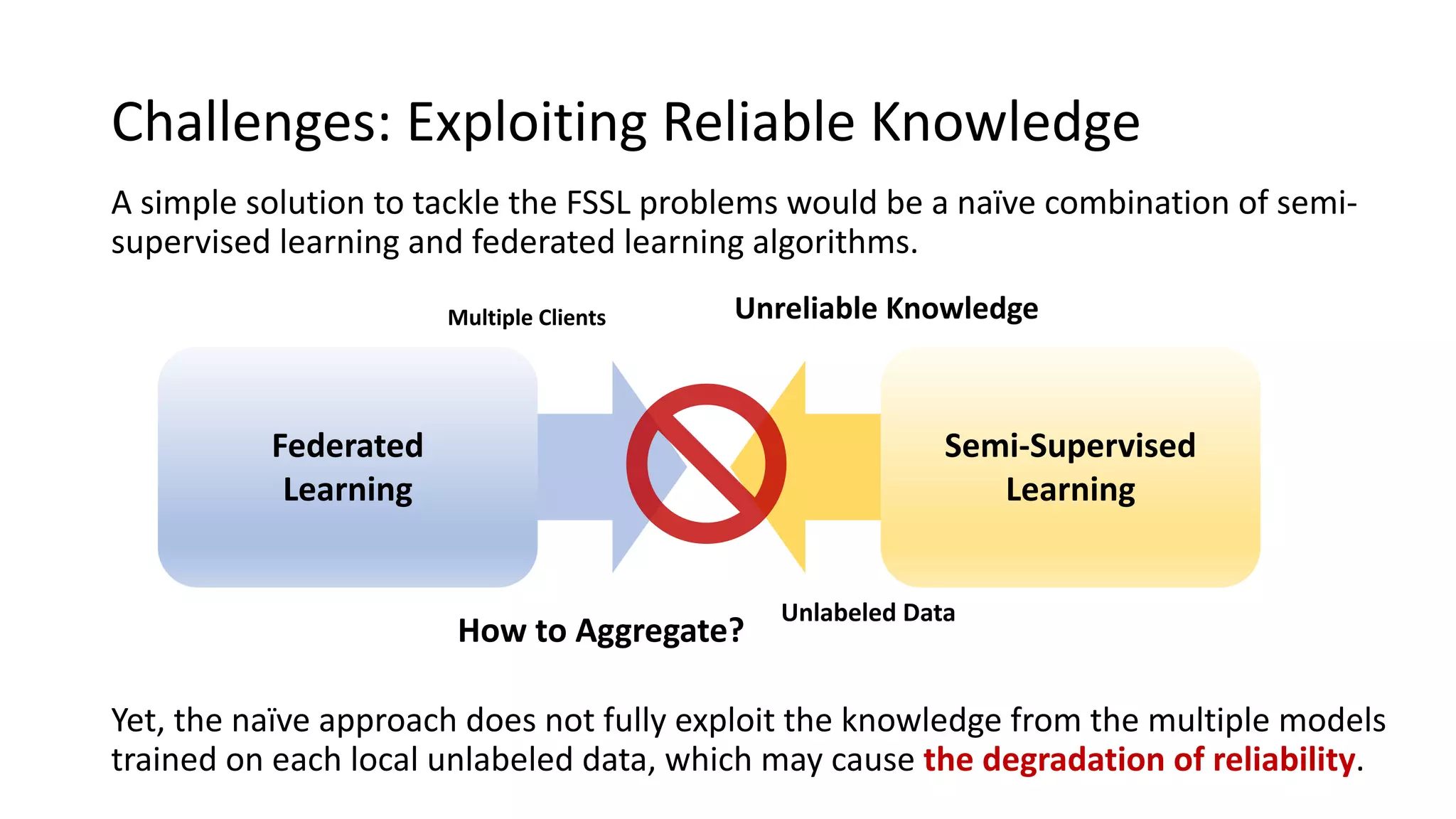
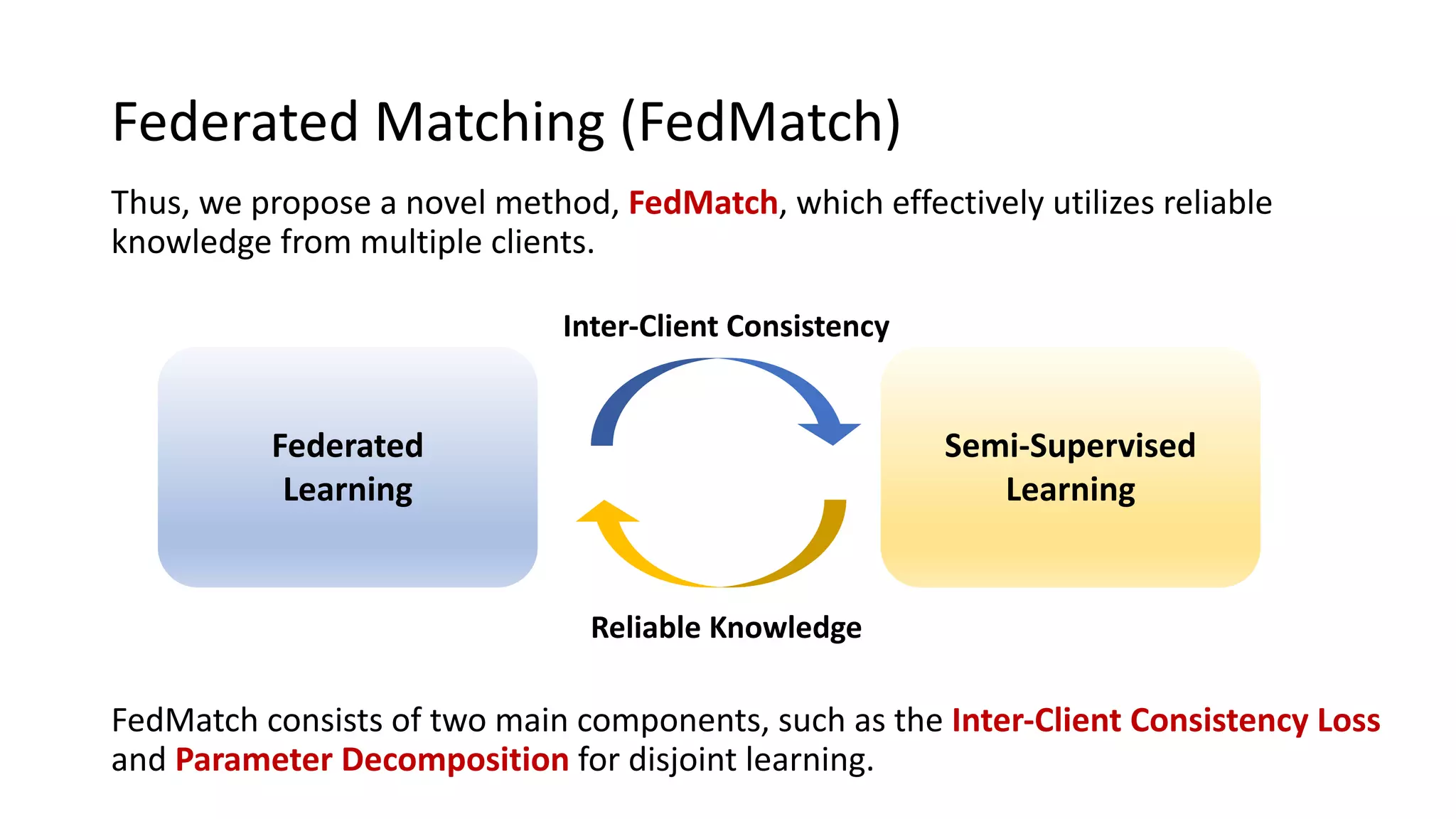
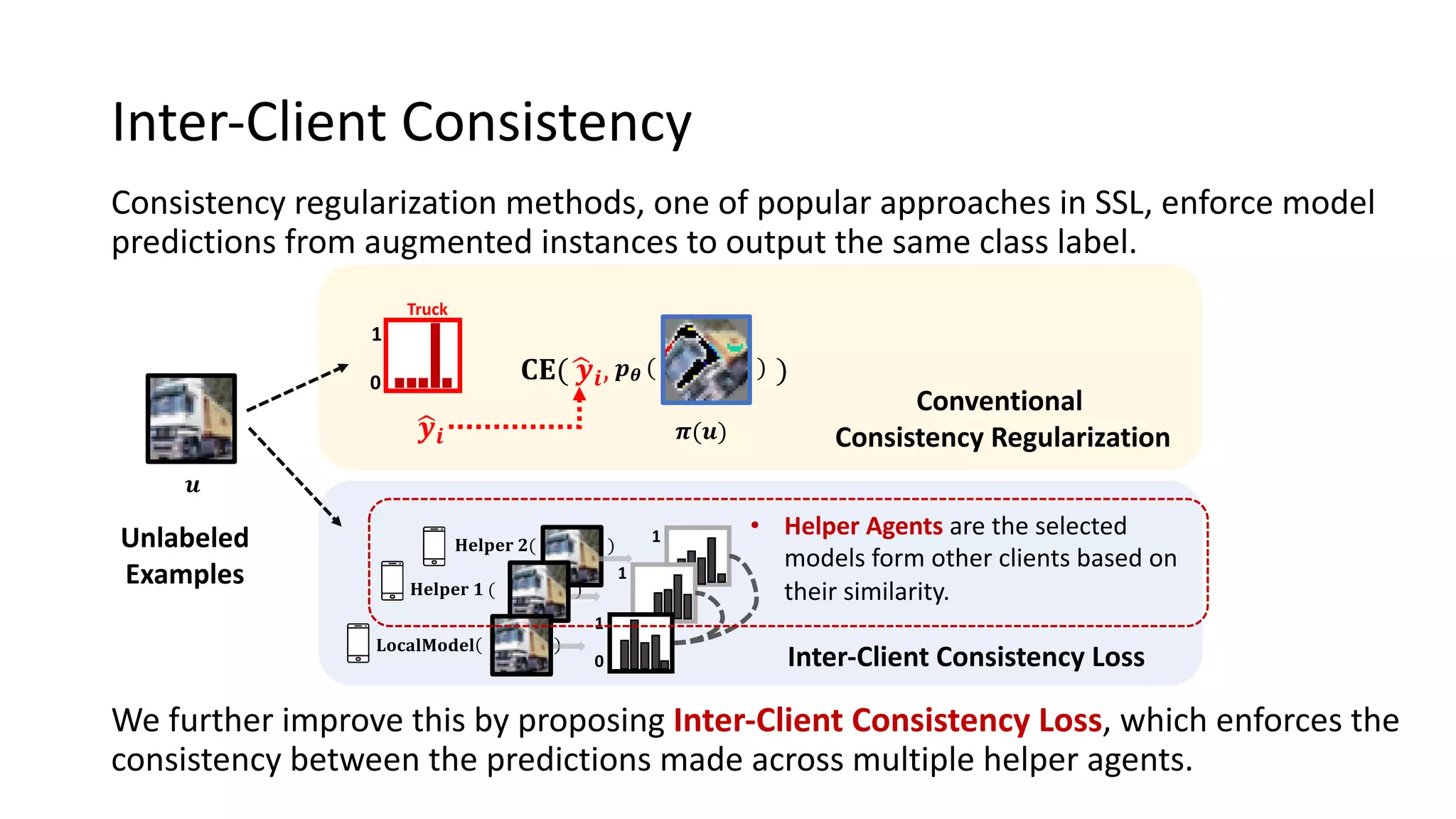
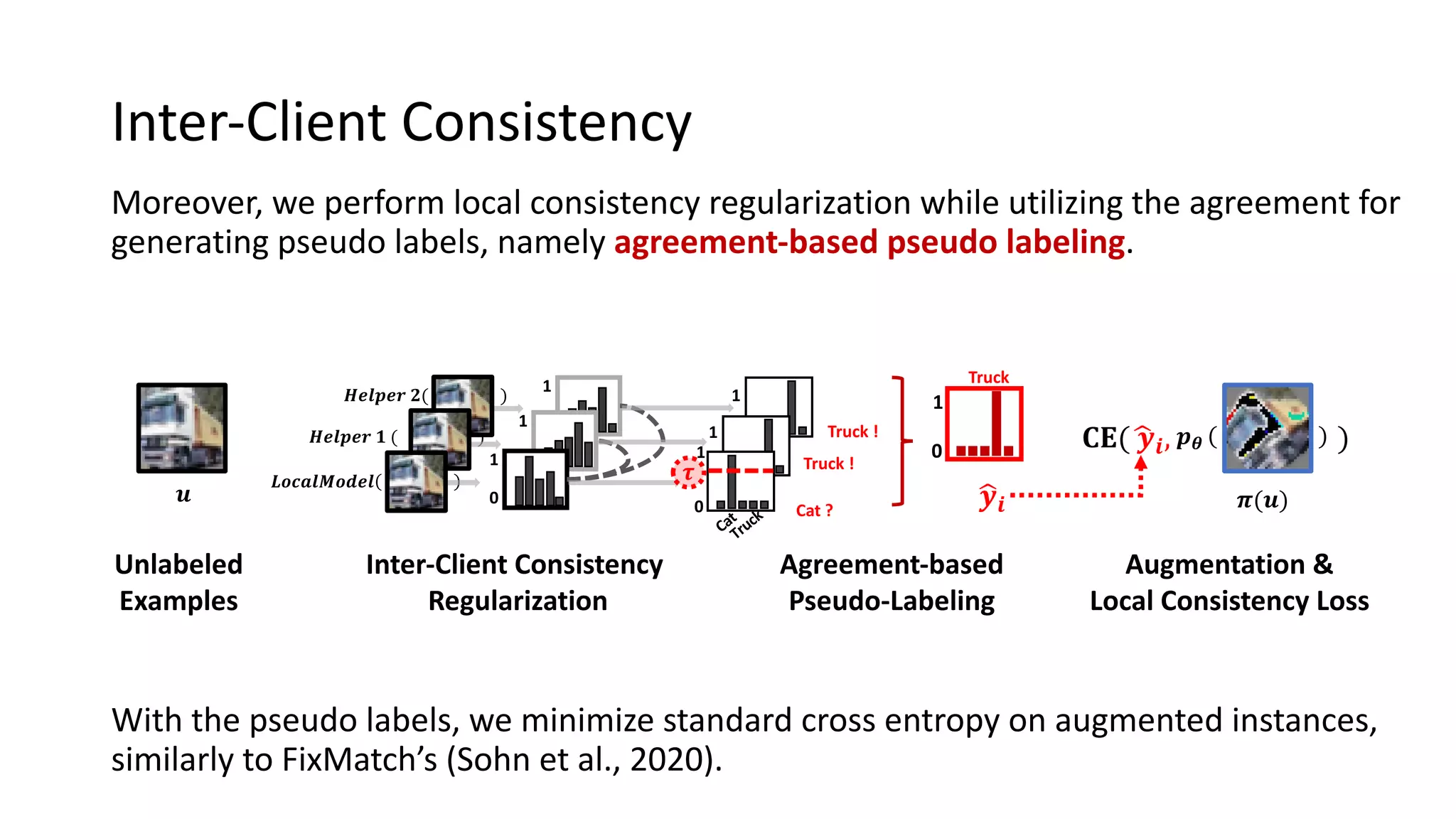
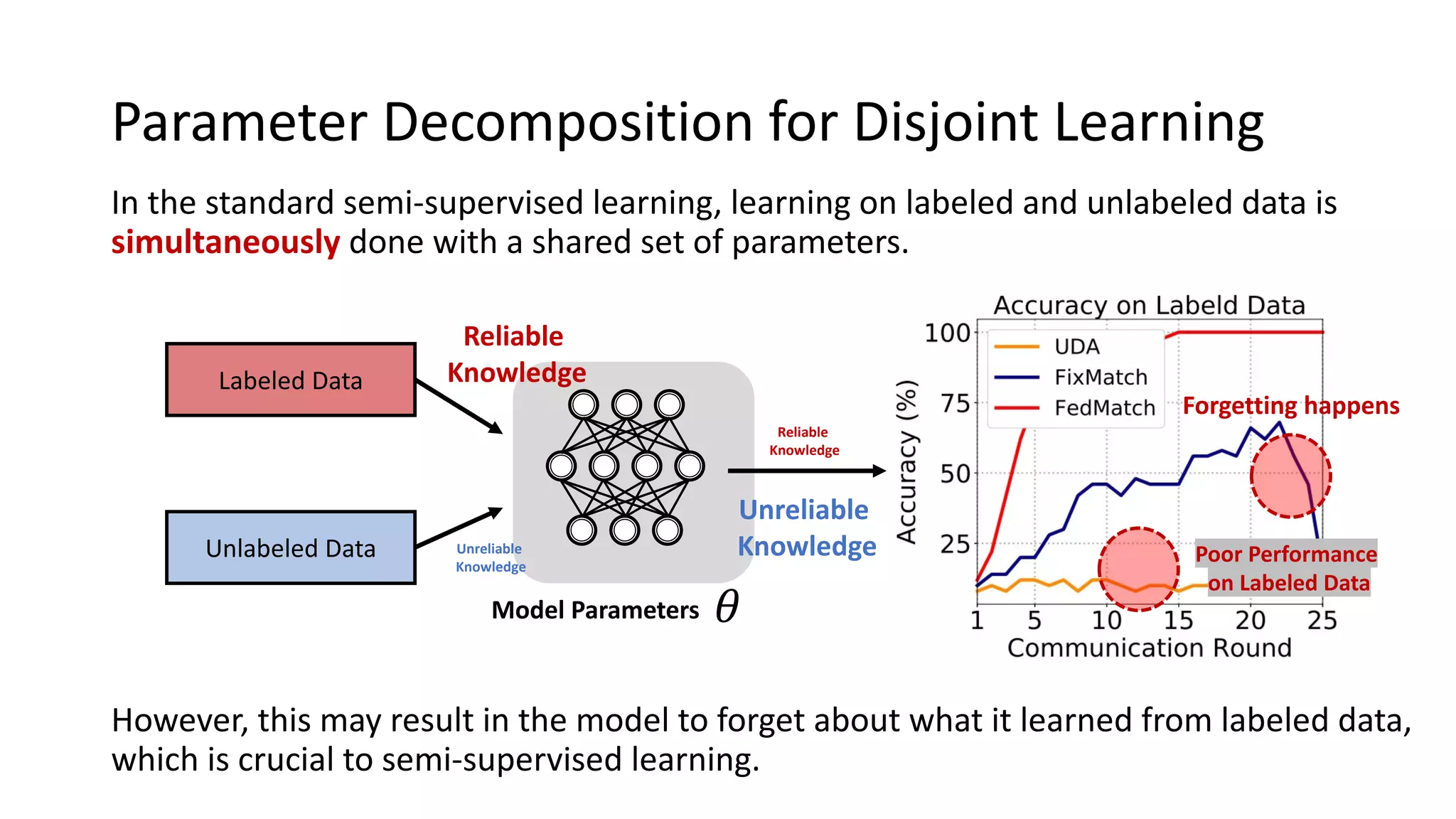
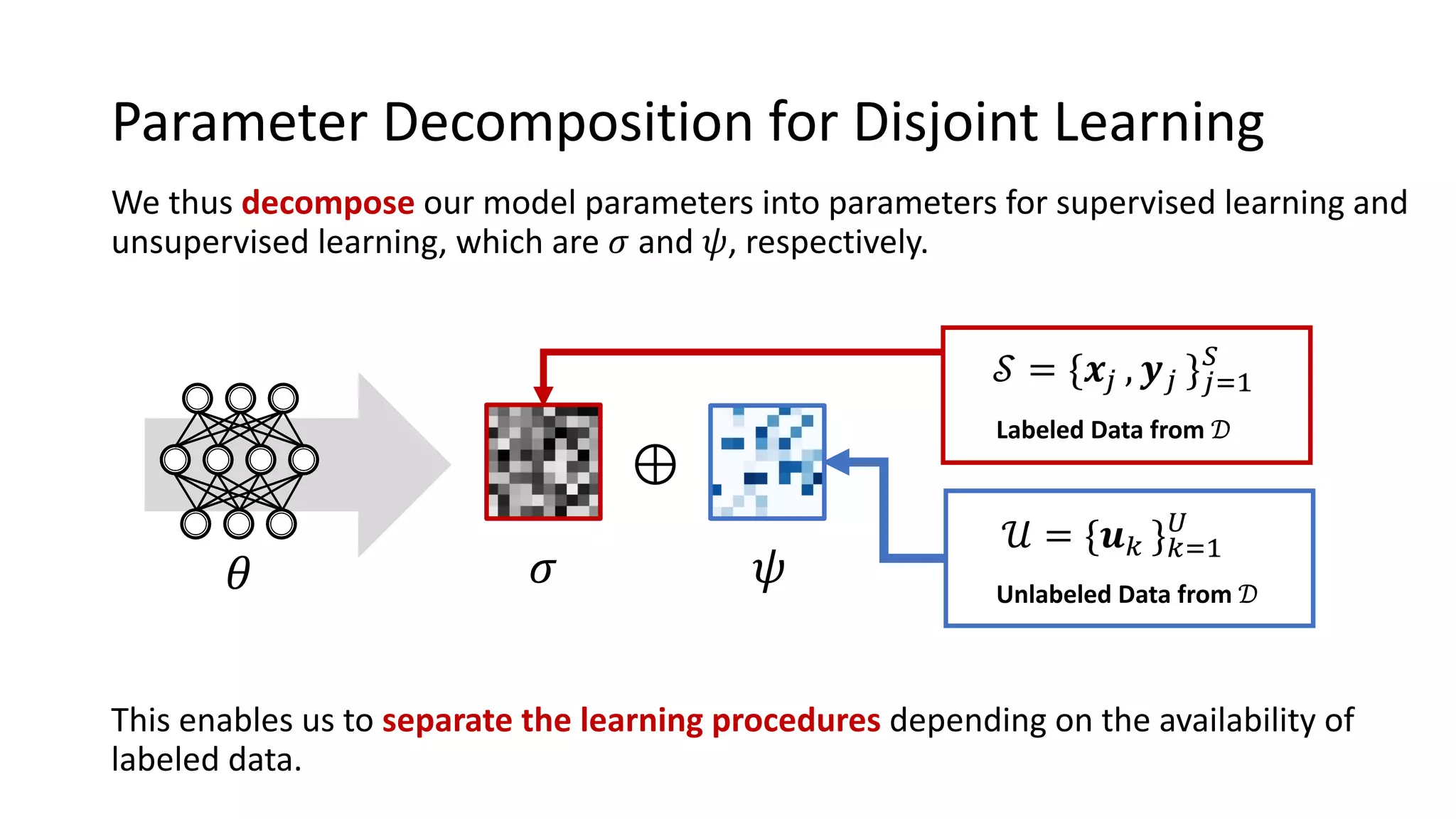
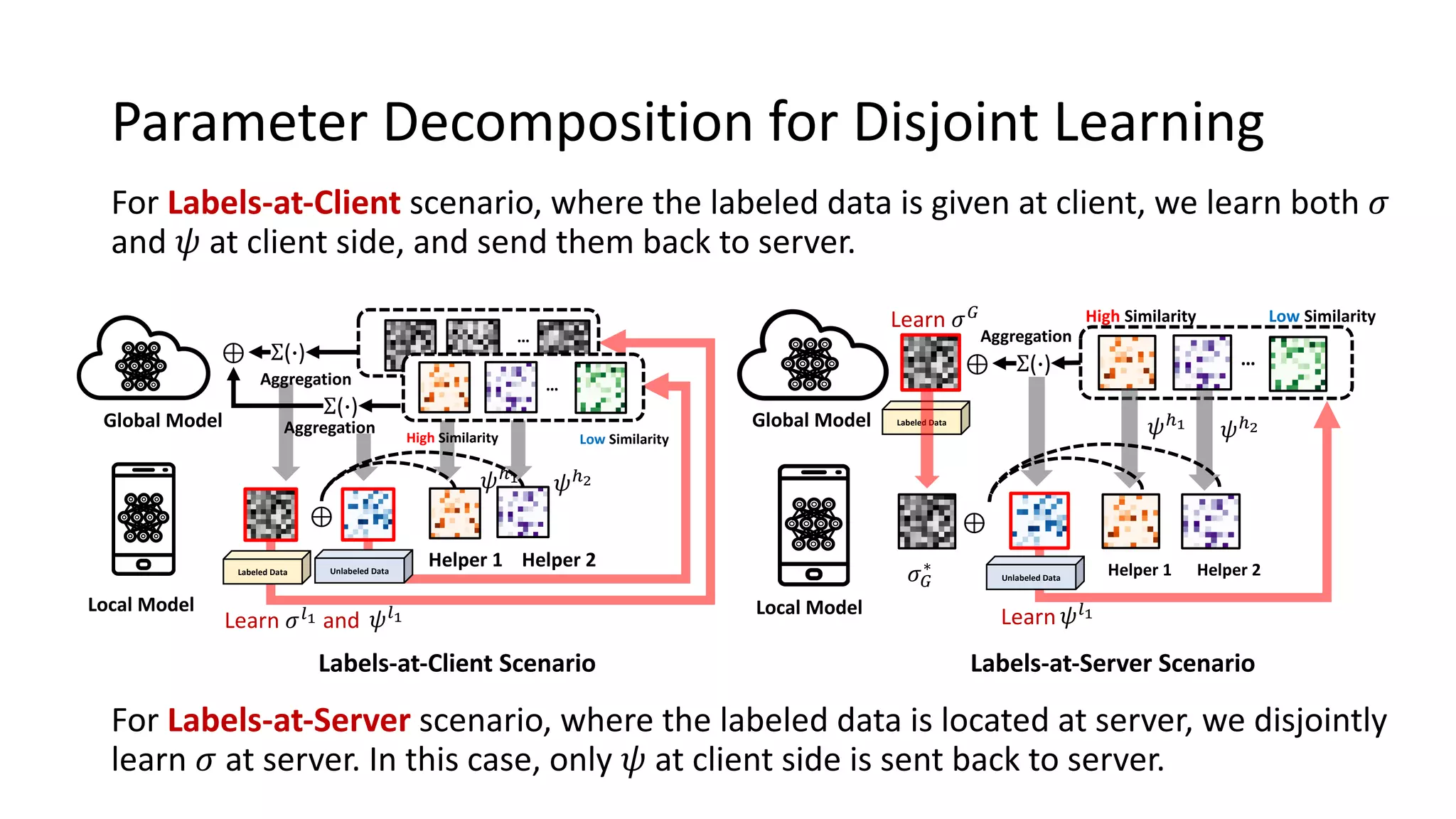
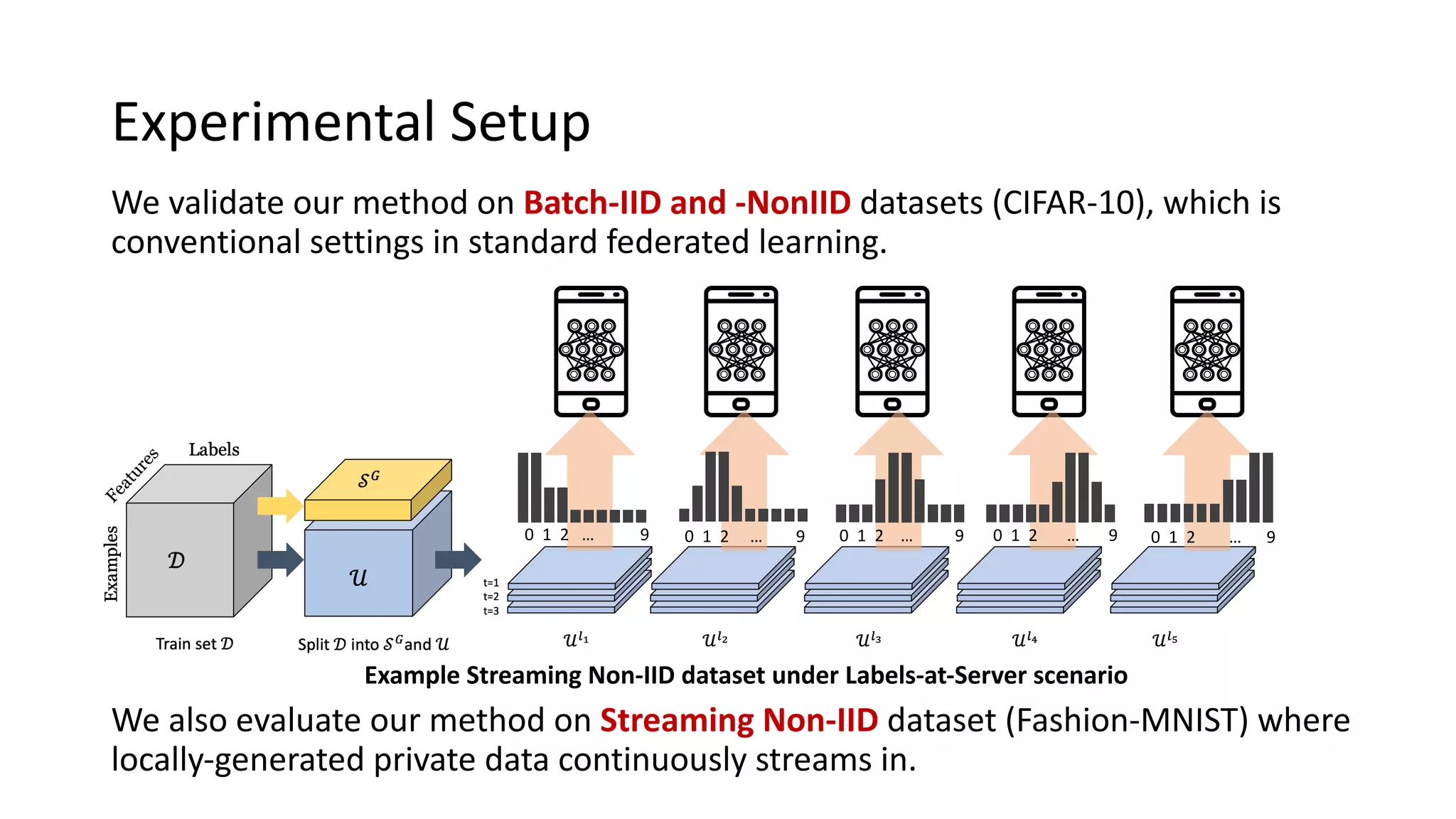
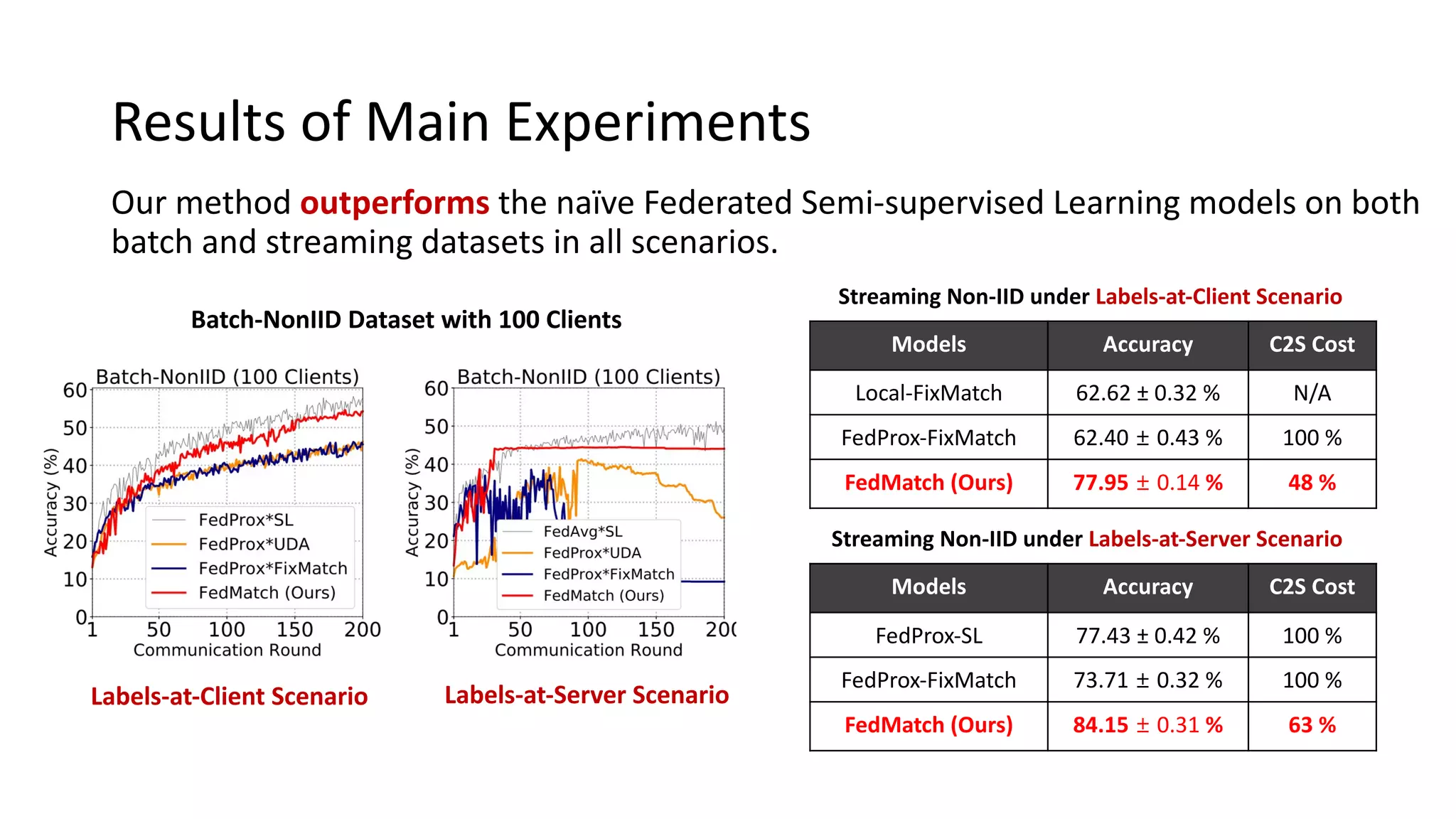
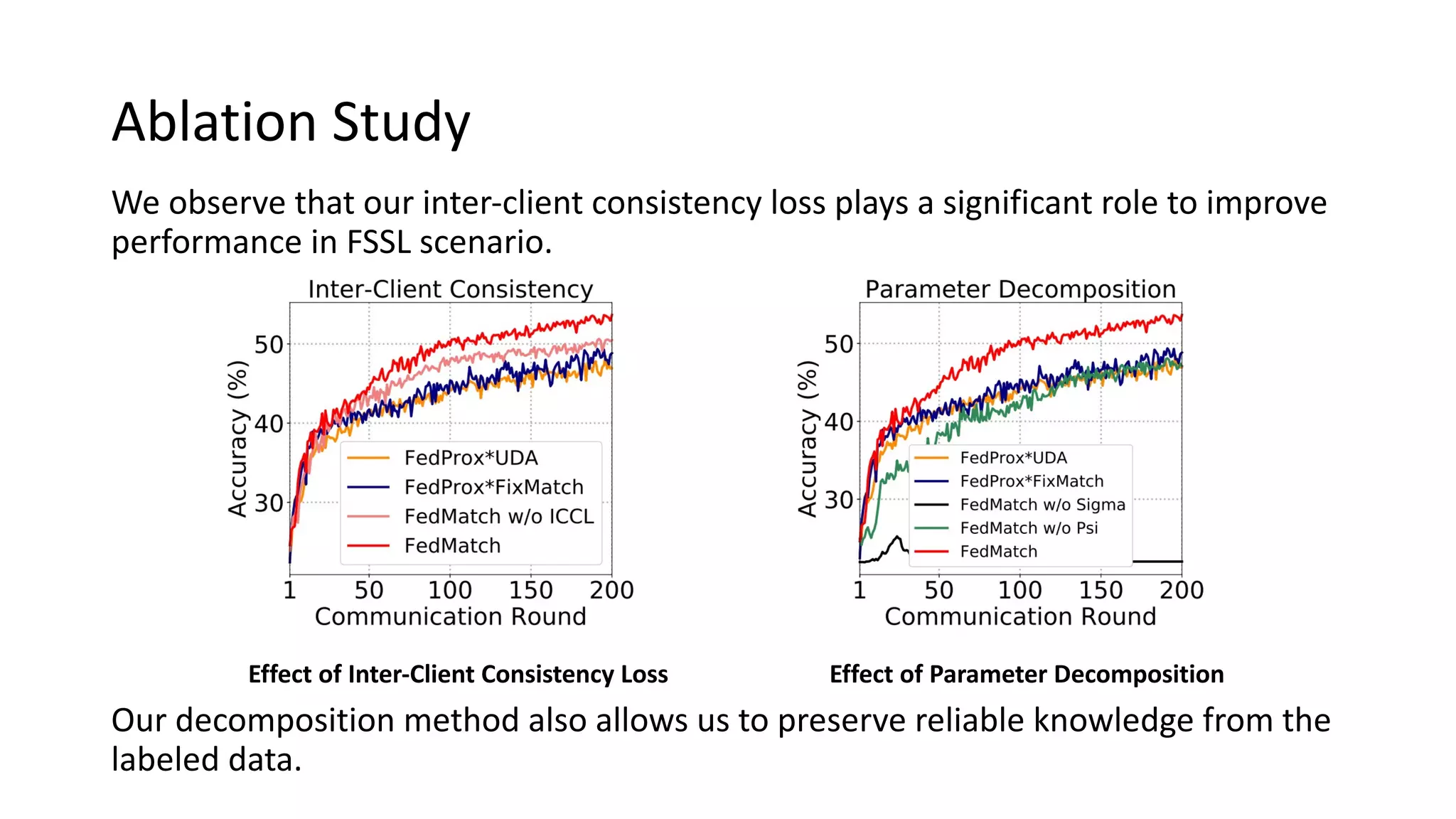
The document presents a method called federated semi-supervised learning (FSSL) designed to enhance knowledge sharing among clients with limited labeled data. It introduces 'fedmatch', which employs inter-client consistency loss and parameter decomposition for effective learning across different scenarios where either partially or completely unlabeled data is present. Experimental results demonstrate that fedmatch significantly outperforms traditional FSSL approaches in both batch and streaming datasets.


























![[논문리뷰] Data Augmentation for 1D 시계열 데이터](https://cdn.slidesharecdn.com/ss_thumbnails/20181204a-gistdataugwearableeegdkim-181212141033-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSC Europe 24] Nemanja Milosevic - Beyond Supervised Learning with Zero-Shot...](https://cdn.slidesharecdn.com/ss_thumbnails/nemanjamilosevic-241219150756-b1cc16e6-thumbnail.jpg?width=640&height=640&fit=bounds)

















































