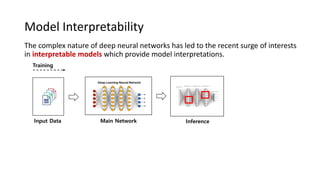
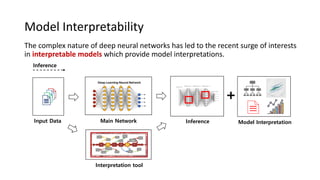
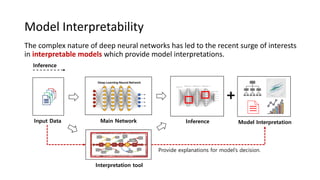
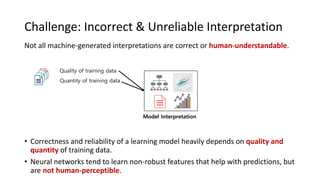
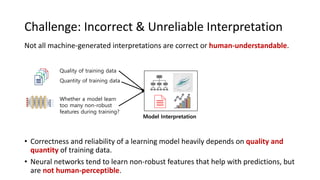
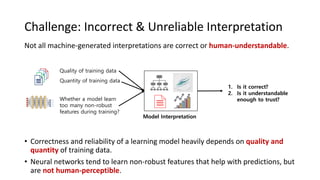
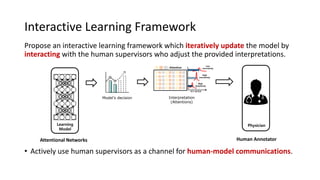
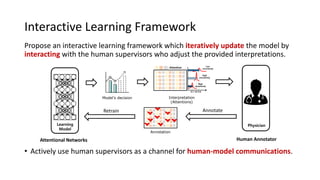
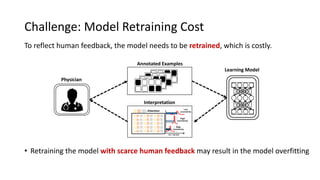
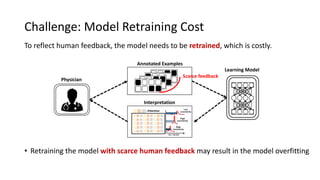
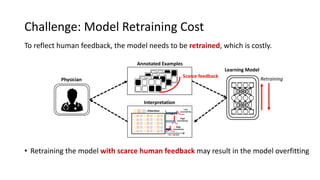
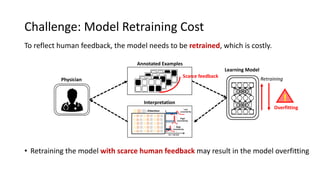
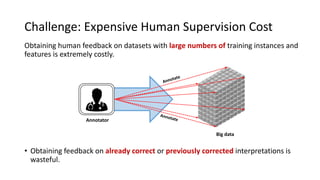
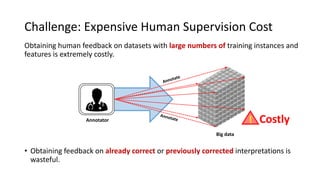
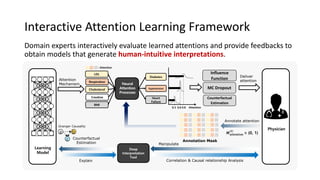
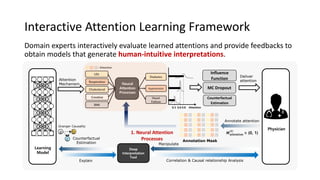
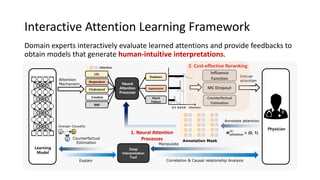
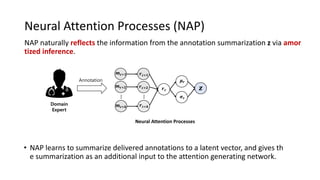
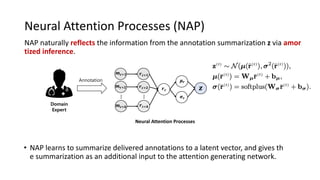
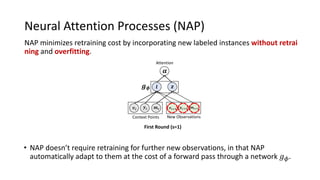
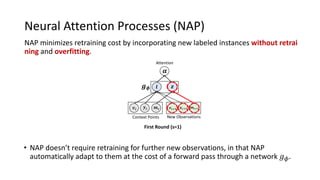
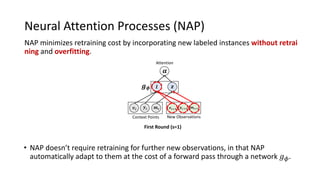
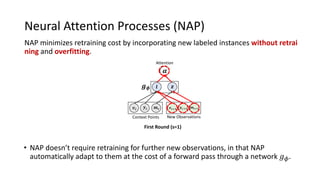
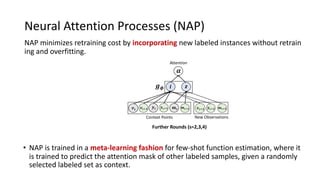
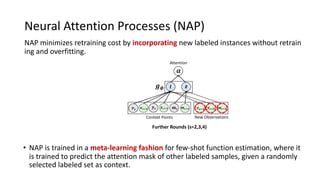
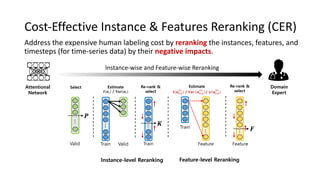
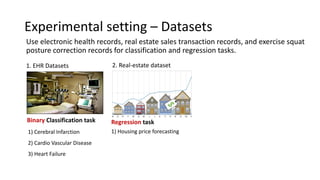
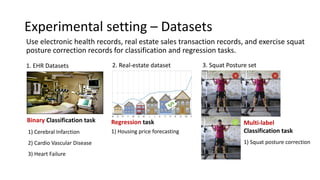
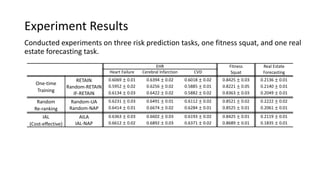
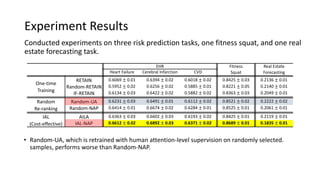
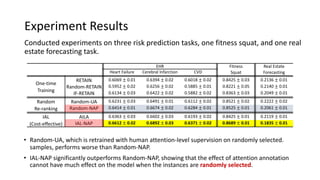
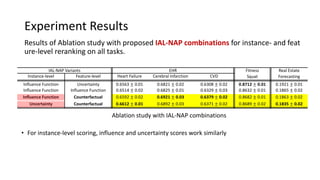
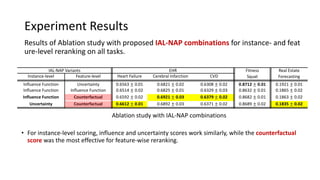
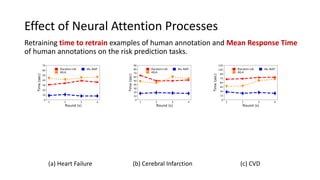
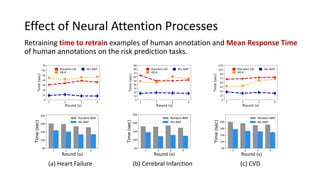
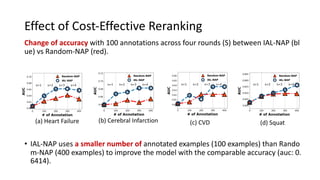
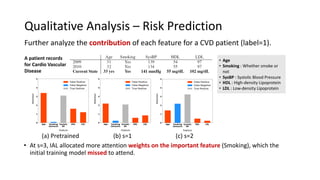
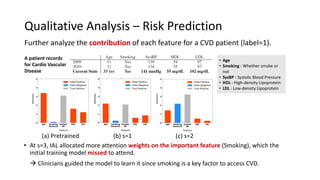
The document presents an interactive learning framework aimed at improving model interpretability in deep neural networks through human interaction and feedback. It addresses challenges such as incorrect interpretations and the high costs of retraining models, proposing cost-effective approaches for annotation and instance selection. The framework utilizes neural attention processes for efficient learning and evaluation across various datasets, including electronic health records and real estate transactions.





![CER: 1. Influence Score
Use the influence function (Koh & Liang, 2017) to approximate the impact of
individual training points on the model prediction.
Fish
Dog
Dog
“Dog”
Training
Training data Test Input
[Koh and Liang 17] Understanding Black-box Predictions via Influence Functions, ICML 2017](https://image.slidesharecdn.com/cost-effectiveinteractiveattentionlearningwithneuralattentionprocesses-200723084557/85/Cost-effective-Interactive-Attention-Learning-with-Neural-Attention-Process-32-320.jpg)
![CER: 2. Uncertainty Score
Measure the negative impacts using the uncertainty which can be measured by Mon
te-Carlo sampling (Gal & Ghahramani, 2016).
Uncertainty-aware Attention Mechanism
• Less expensive approach to measure the negative impacts.
• Assume that instances having high-predictive uncertainties are potential
candidate to be corrected.
Uncertainty
[Jay Heo*, Haebeom Lee*, Saehun Kim,, Juho Lee, Gwangjun Kim , Eunho Yang, Sung Joo Hwang] Uncertainty-aware Attention Mechanism for Reliable prediction and Interpretation, Neurips 2018.](https://image.slidesharecdn.com/cost-effectiveinteractiveattentionlearningwithneuralattentionprocesses-200723084557/85/Cost-effective-Interactive-Attention-Learning-with-Neural-Attention-Process-33-320.jpg)
![CER: 2. Uncertainty Score
Measure the negative impacts using the uncertainty which can be measured by Mon
te-Carlo sampling (Gal & Ghahramani, 2016).
Measure instance-wise &
feature-wise uncertainty
0.80.60.3
Low
uncertainty
High
uncertainty
High
uncertainty
µ σ, )(N
SpO2
Pulse
Respiration
• Less expensive approach to measure the negative impacts.
• Assume that instances having high-predictive uncertainties are potential
candidate to be corrected.
Uncertainty-aware Attention Mechanism
[Jay Heo*, Haebeom Lee*, Saehun Kim,, Juho Lee, Gwangjun Kim , Eunho Yang, Sung Joo Hwang] Uncertainty-aware Attention Mechanism for Reliable prediction and Interpretation, Neurips 2018.](https://image.slidesharecdn.com/cost-effectiveinteractiveattentionlearningwithneuralattentionprocesses-200723084557/85/Cost-effective-Interactive-Attention-Learning-with-Neural-Attention-Process-34-320.jpg)

















































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)







![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)


![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)







































