Download to read offline


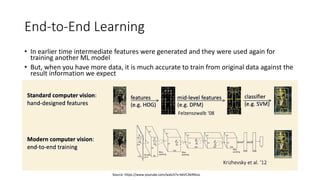

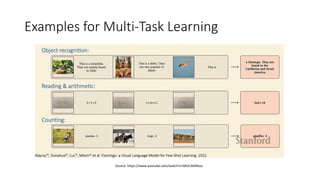

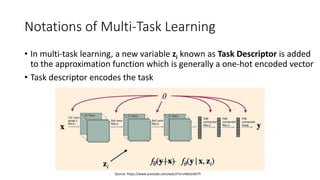
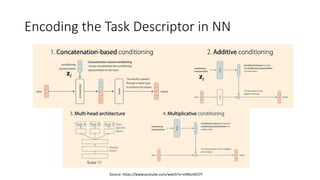













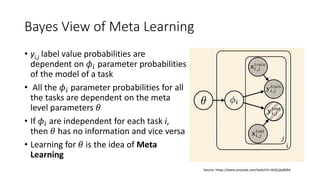



The document discusses advanced machine learning techniques, focusing on end-to-end learning, multi-task learning, and transfer learning. It covers the importance of using original data for training, the challenges of insufficient labeled datasets, and how models can leverage knowledge from related tasks to improve performance. Additionally, it explores meta learning, which optimizes the ability to learn quickly from a set of tasks, along with various practical applications and strategies, including inductive and transductive transfer learning.



































































