Downloaded 60 times










![13
Brick 3: Unweighted instantaneous load signal
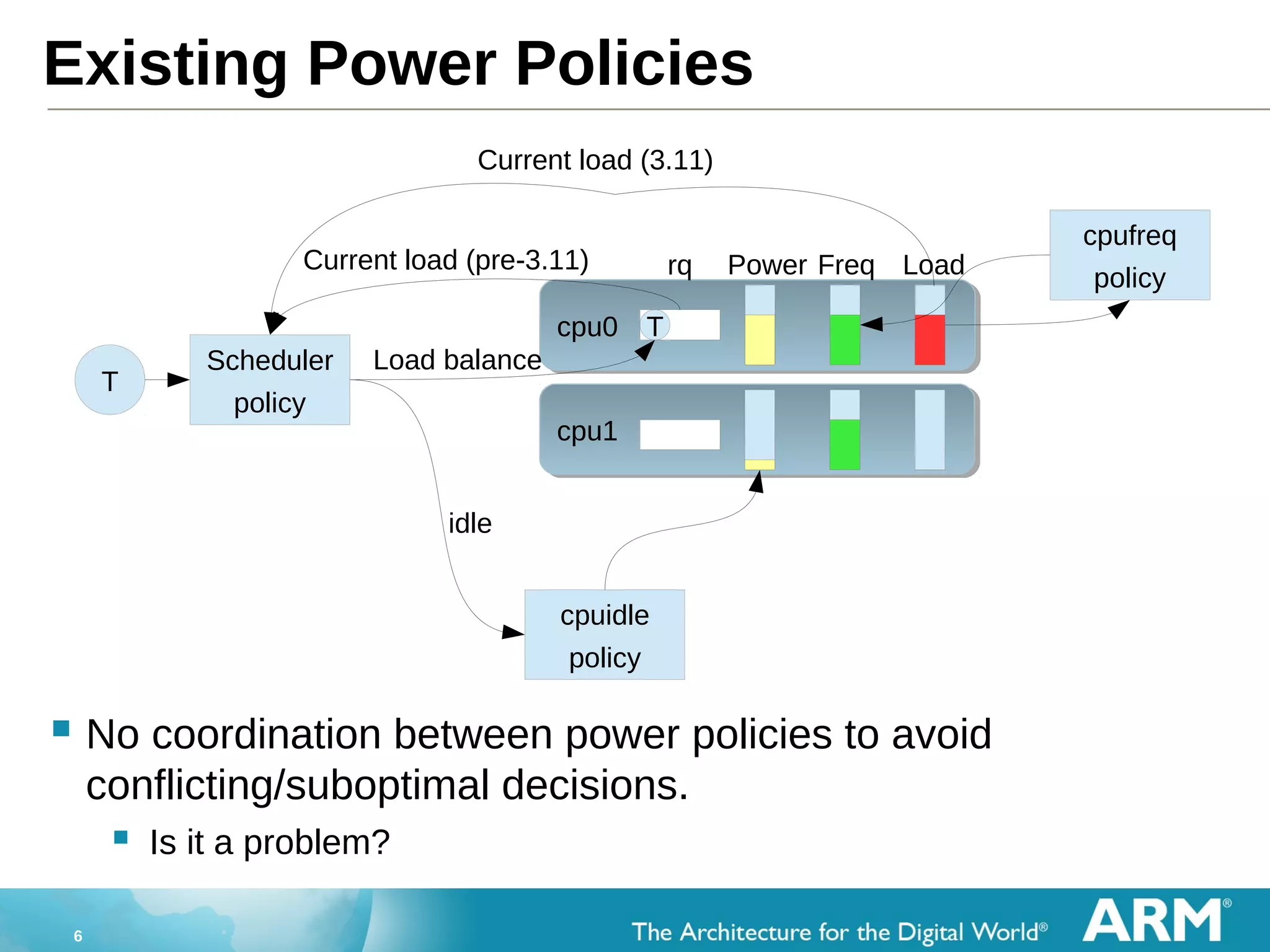
big.LITTLE MP & Task placement based on CPU suitability:
For sched entity and cfs_rq
struct sched_avg {
u32 runnable_avg_sum, runnable_avg_period;
u64 last_runnable_update;
s64 decay_count;
unsigned long load_avg_contrib;
unsigned long load_avg_ratio;
}
sched entity: runnable_avg_sum * NICE_0_LOAD / (runnable_avg_period + 1)
cfs_rq: set in [update/enqueue/dequeue]_entity_load_avg()](https://image.slidesharecdn.com/lcu13pwreffsched-140324084826-phpapp02/75/LCU13-Power-efficient-scheduling-and-the-latest-news-from-the-kernel-summit-13-2048.jpg)







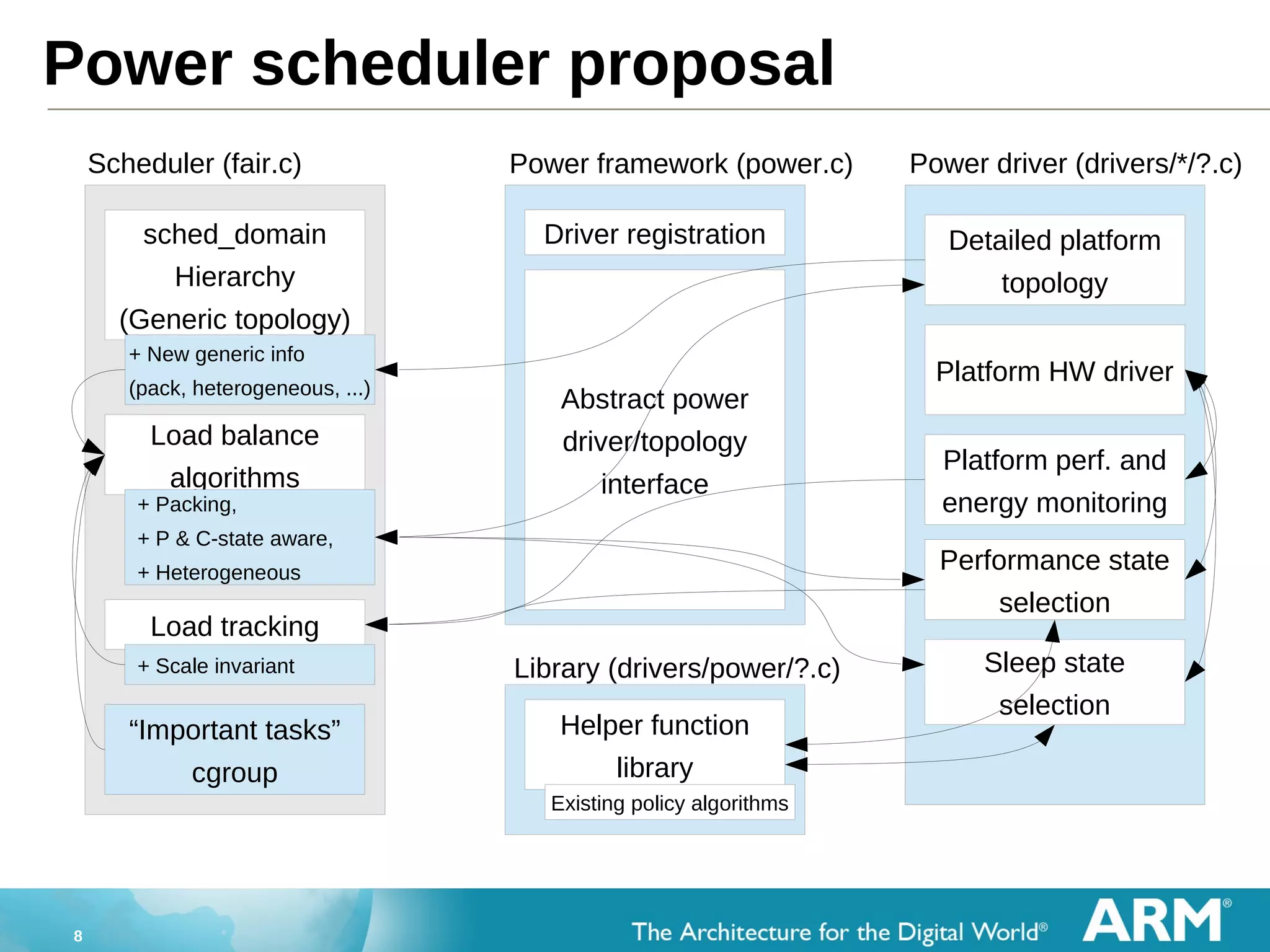
The document discusses power-efficient scheduling in the Linux kernel. It proposes moving power management capabilities from cpufreq and cpuidle into the scheduler to allow it to make more informed decisions. Key points include: - The scheduler currently lacks power/energy information to optimize task placement. - Cpufreq and cpuidle are not well coordinated with the scheduler. - A power driver would provide power/topology data to the scheduler. - Feedback from a kernel summit highlighted the need for use cases and benchmarks to evaluate proposals. - Patches have been prepared to implement task placement based on CPU suitability.






















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















