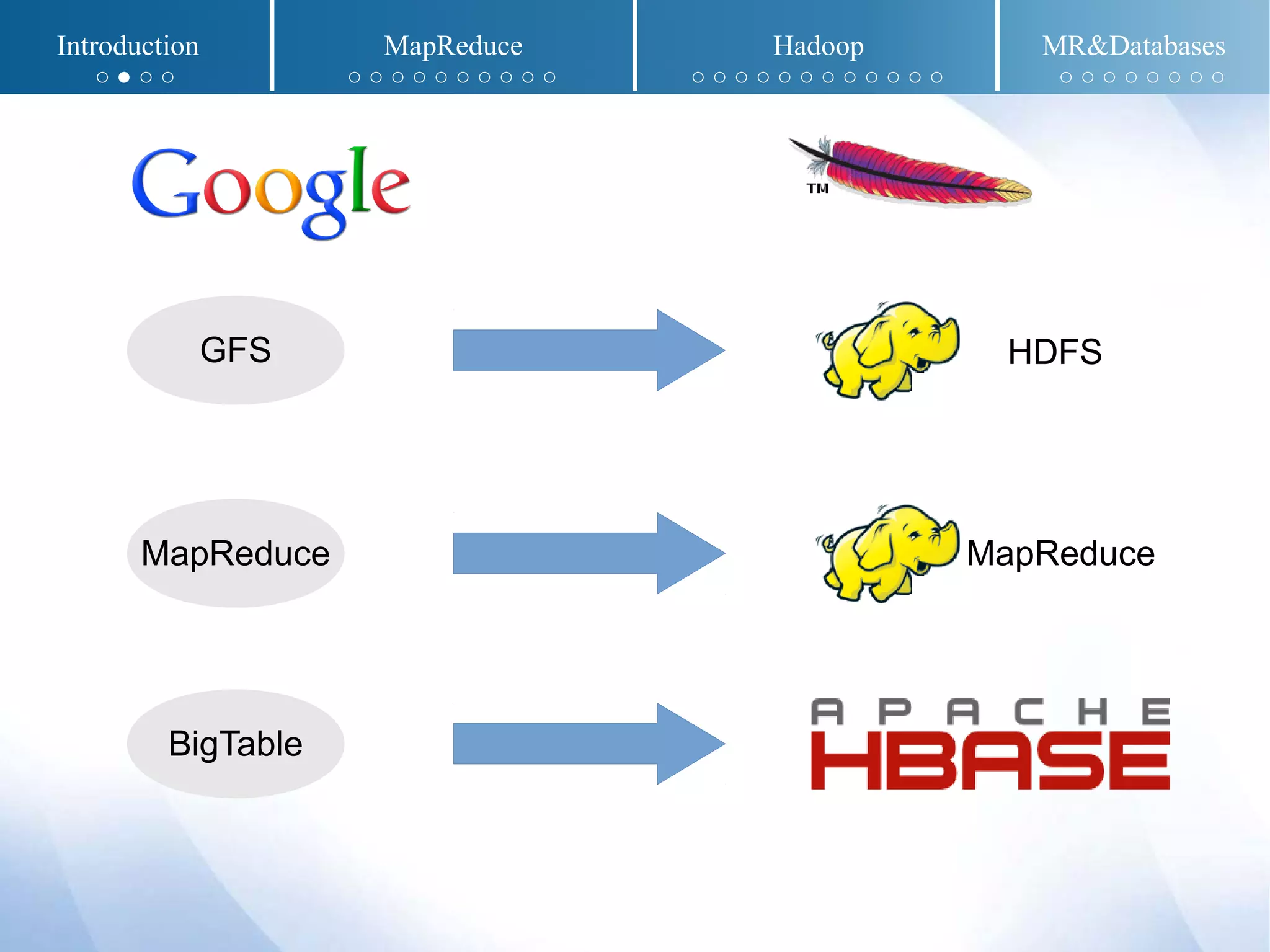
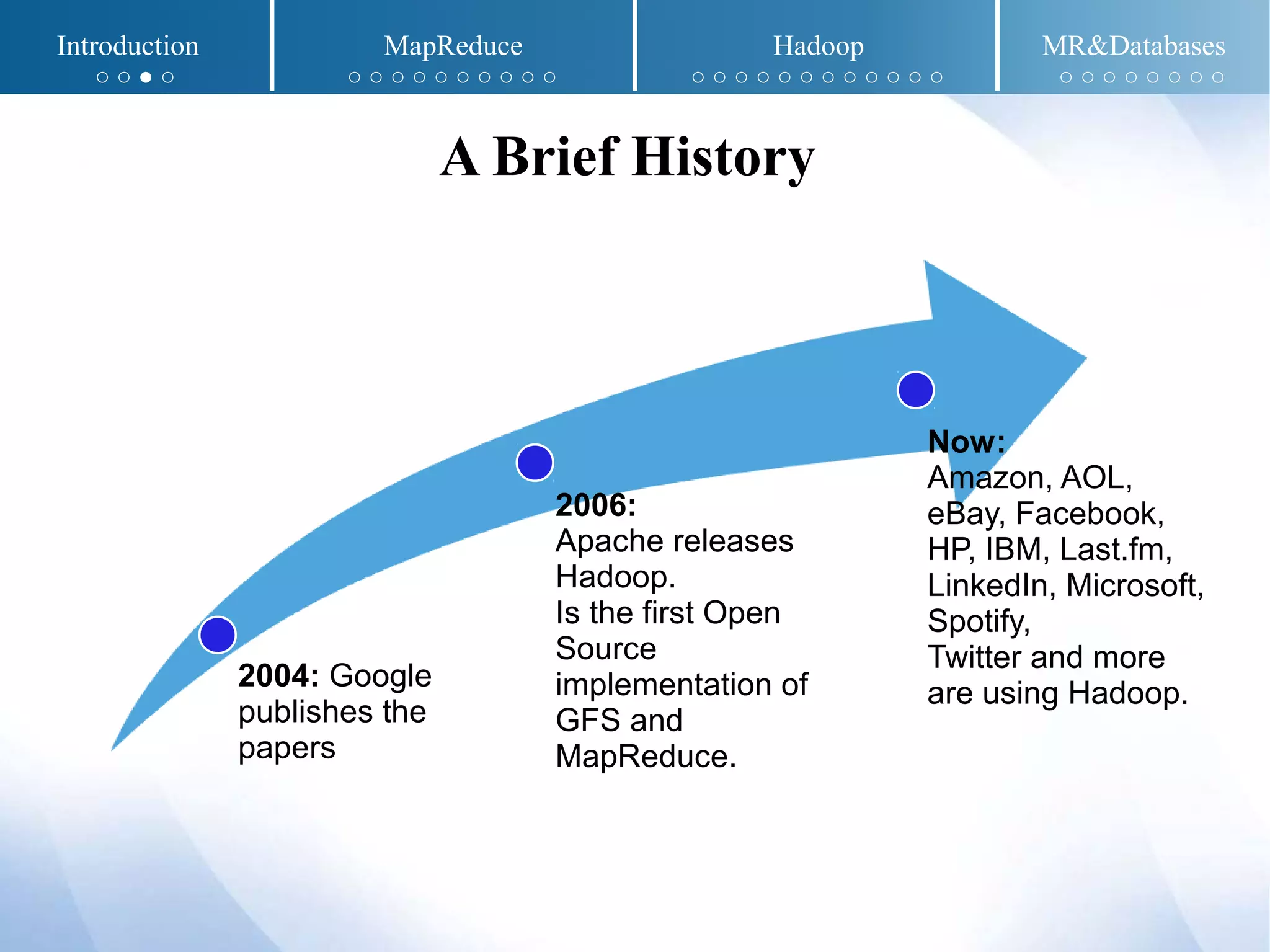
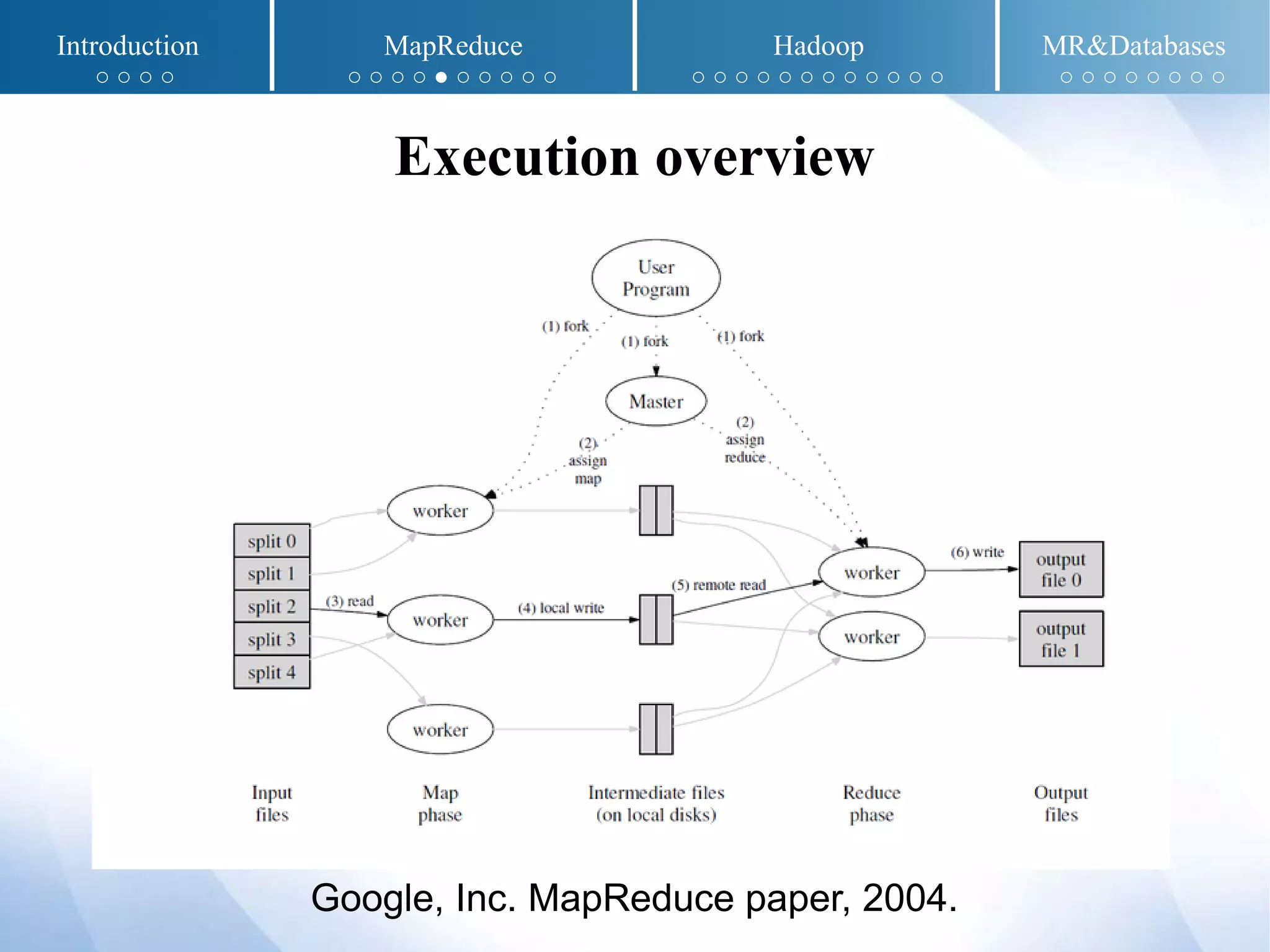
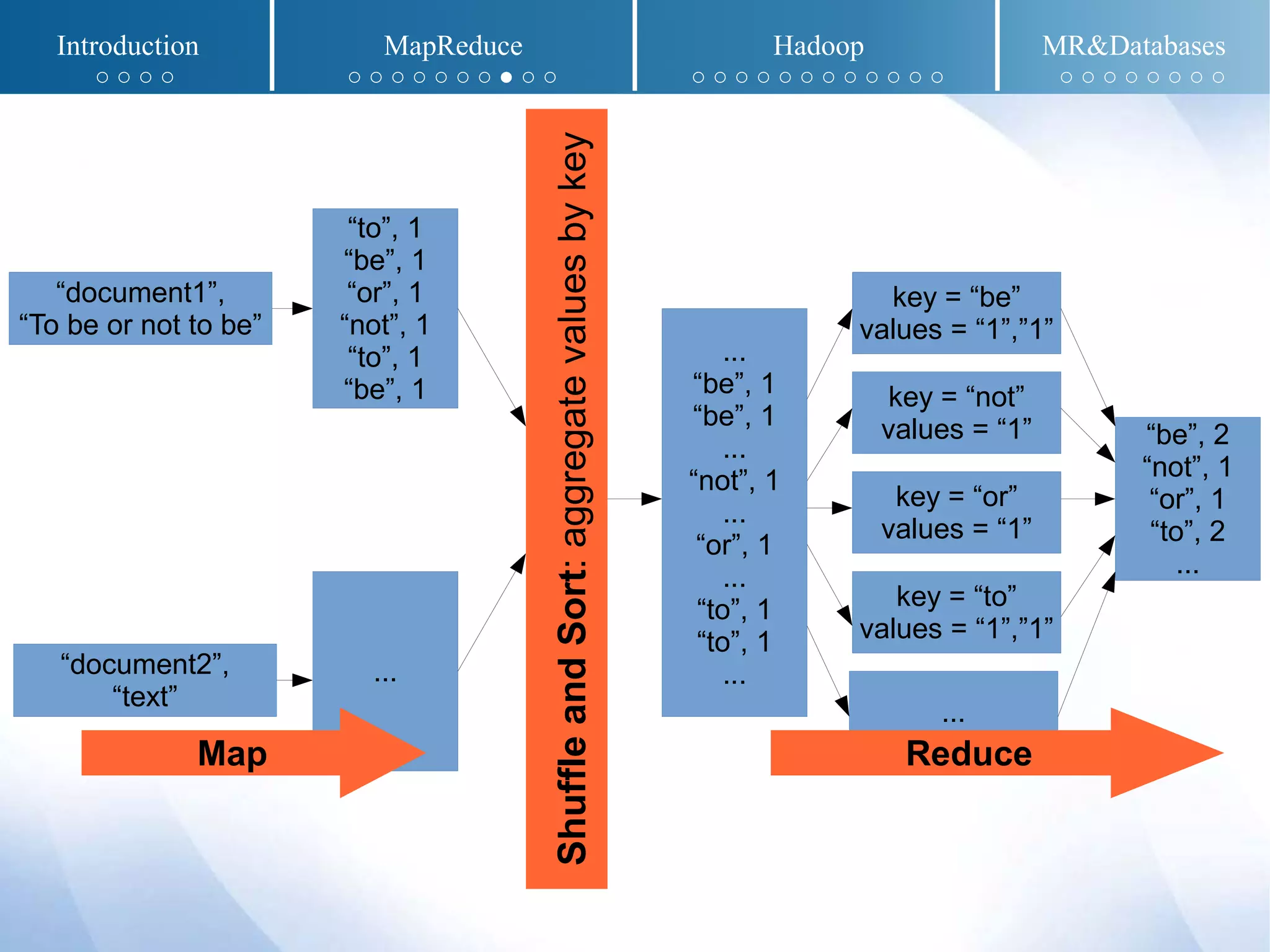
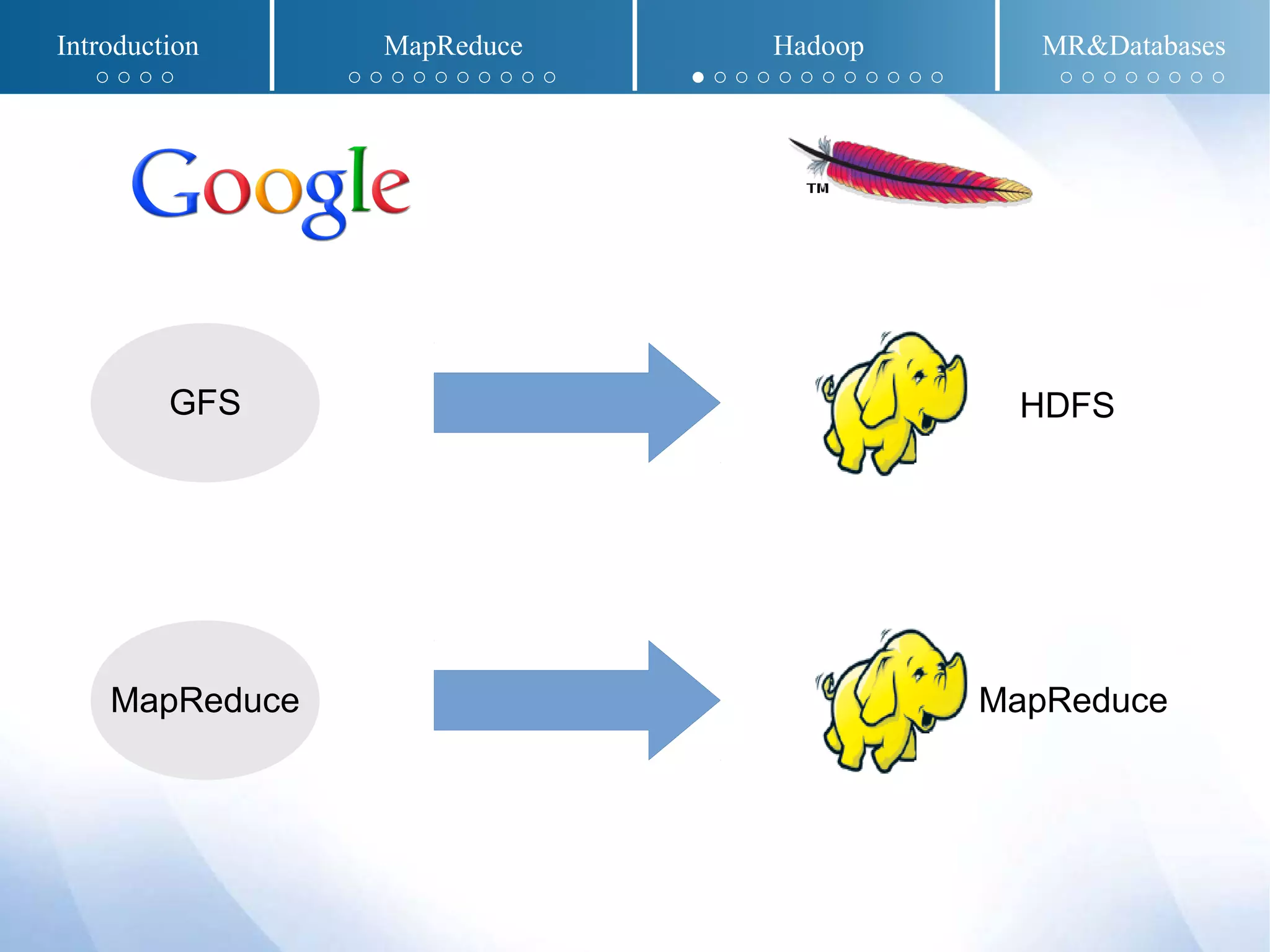
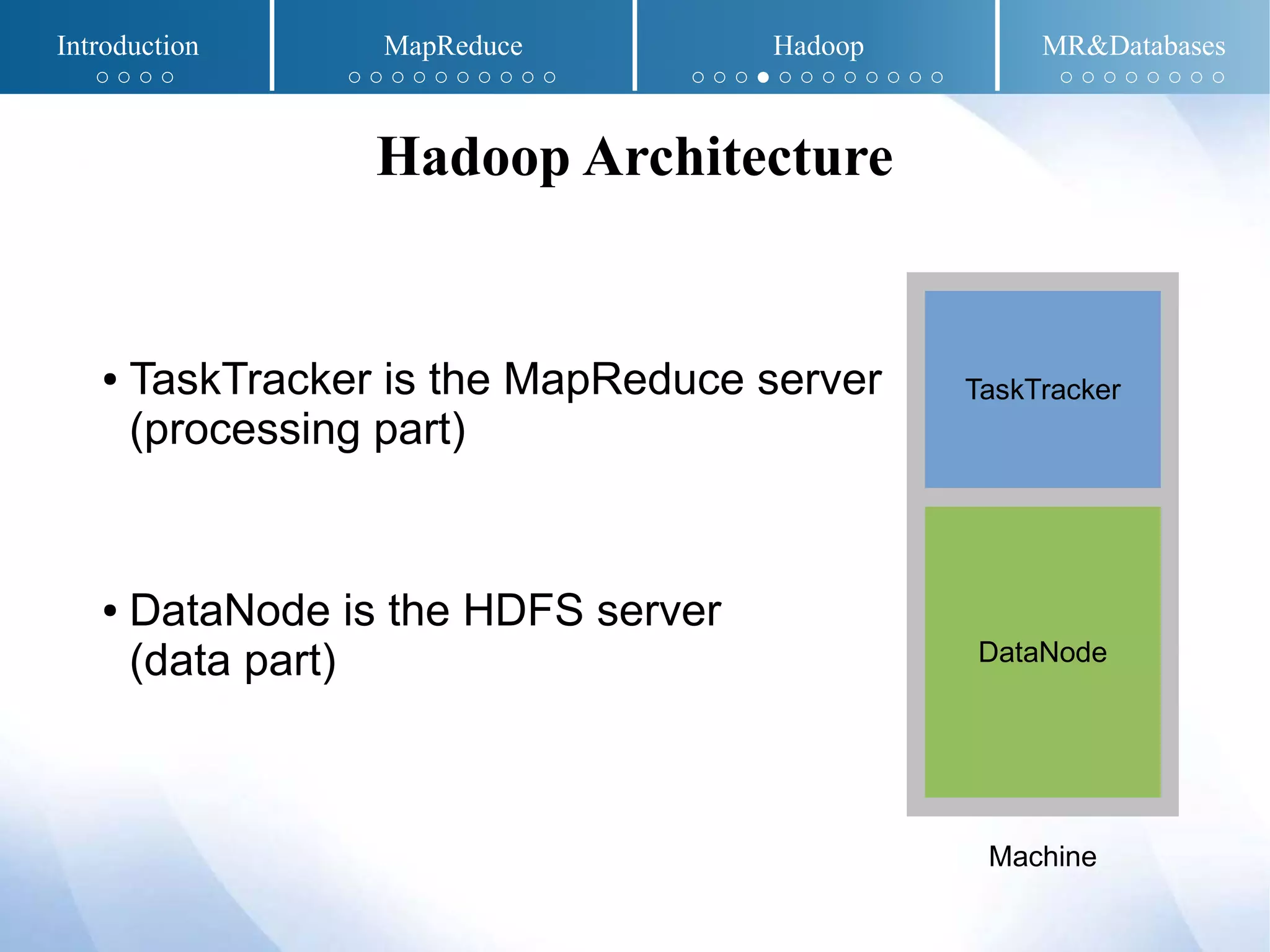
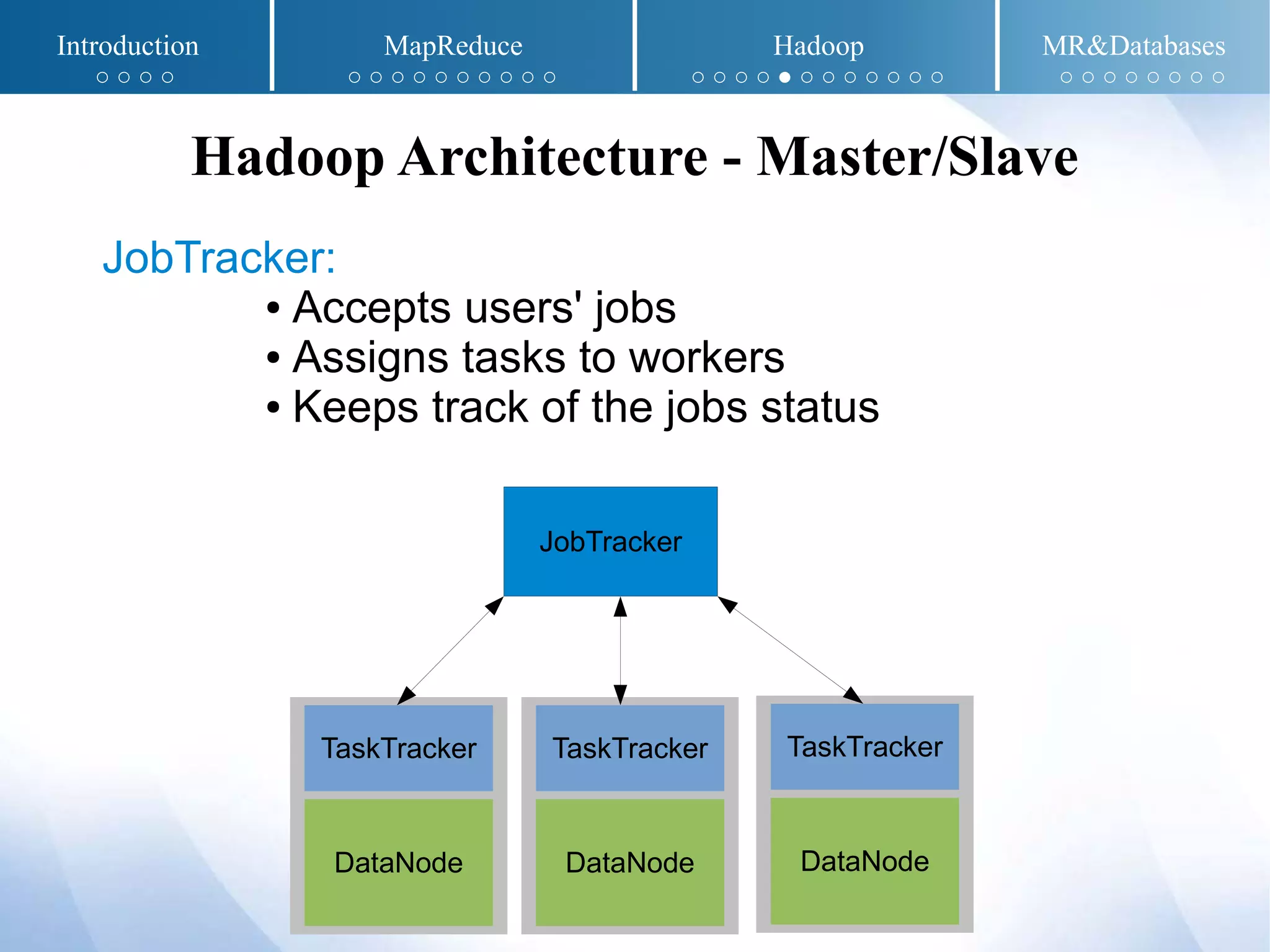
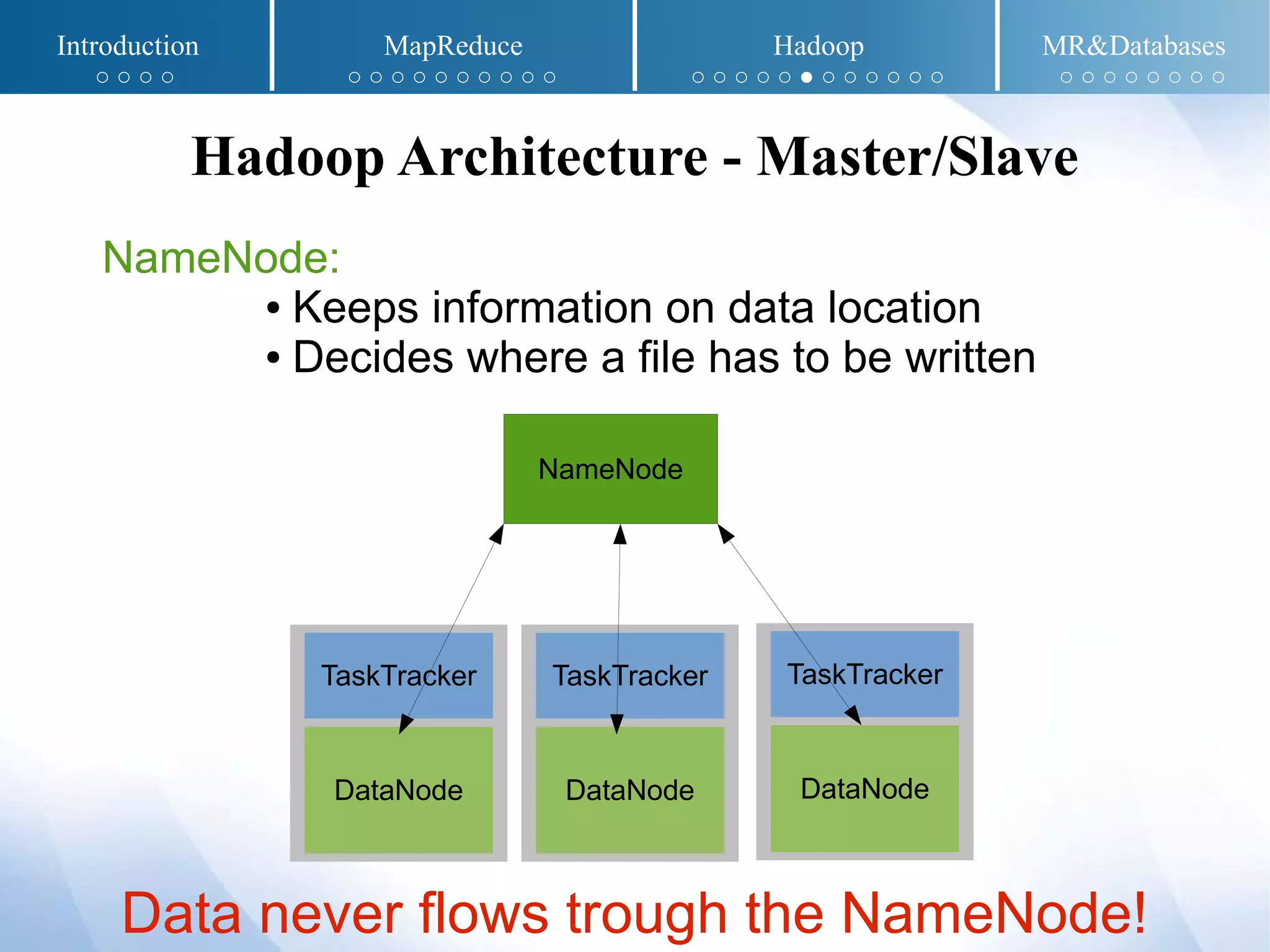
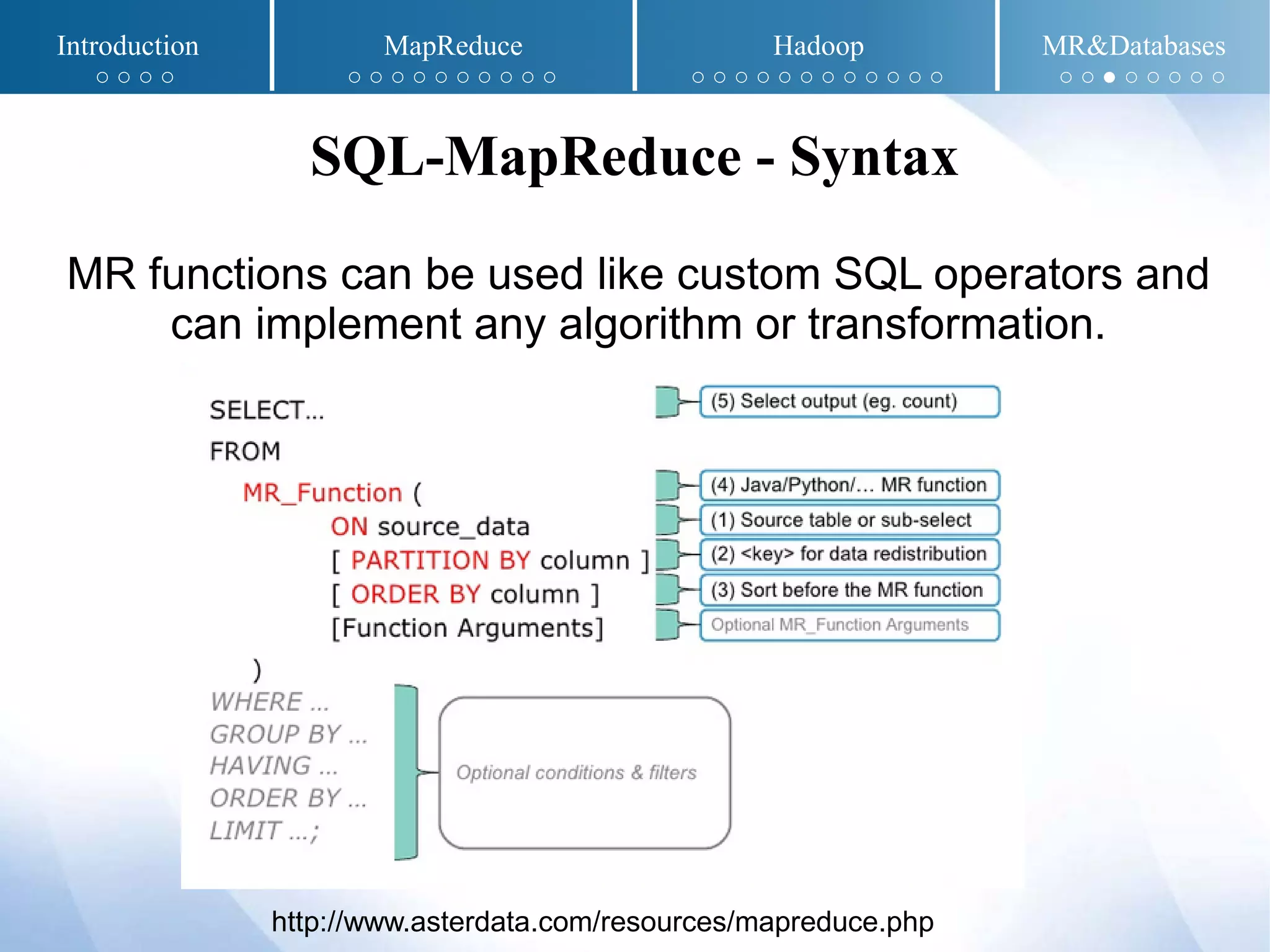
The document presents an overview of MapReduce and Hadoop, detailing their implementation techniques, architecture, and ecosystem. It explains the motivations behind their development, execution details, and real-world applications, emphasizing their relevance in processing large datasets. Additionally, it covers SQL-MapReduce and in-database MapReduce solutions to integrate these frameworks with traditional databases.


















































![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













