Download as PDF, PPTX





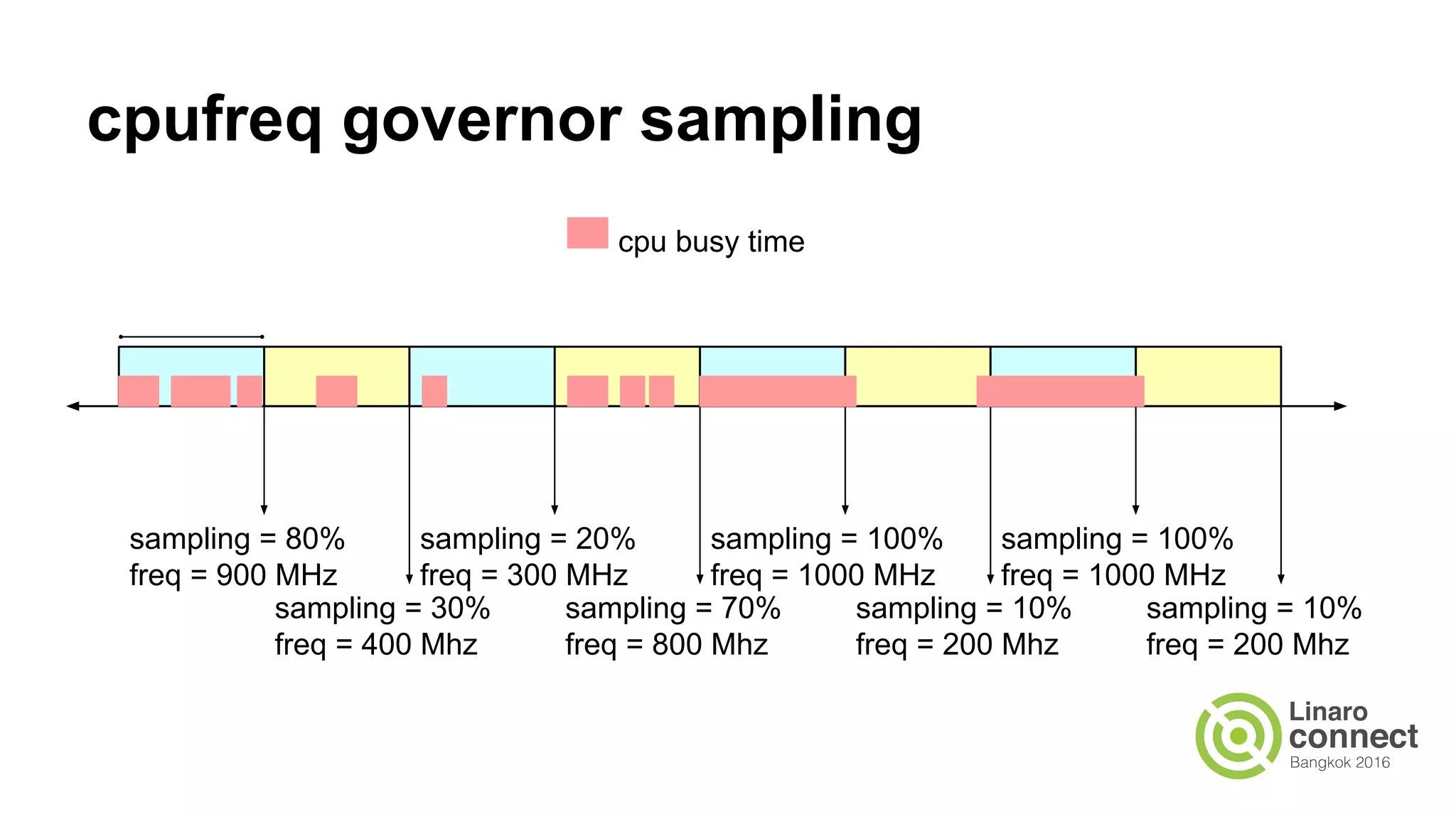

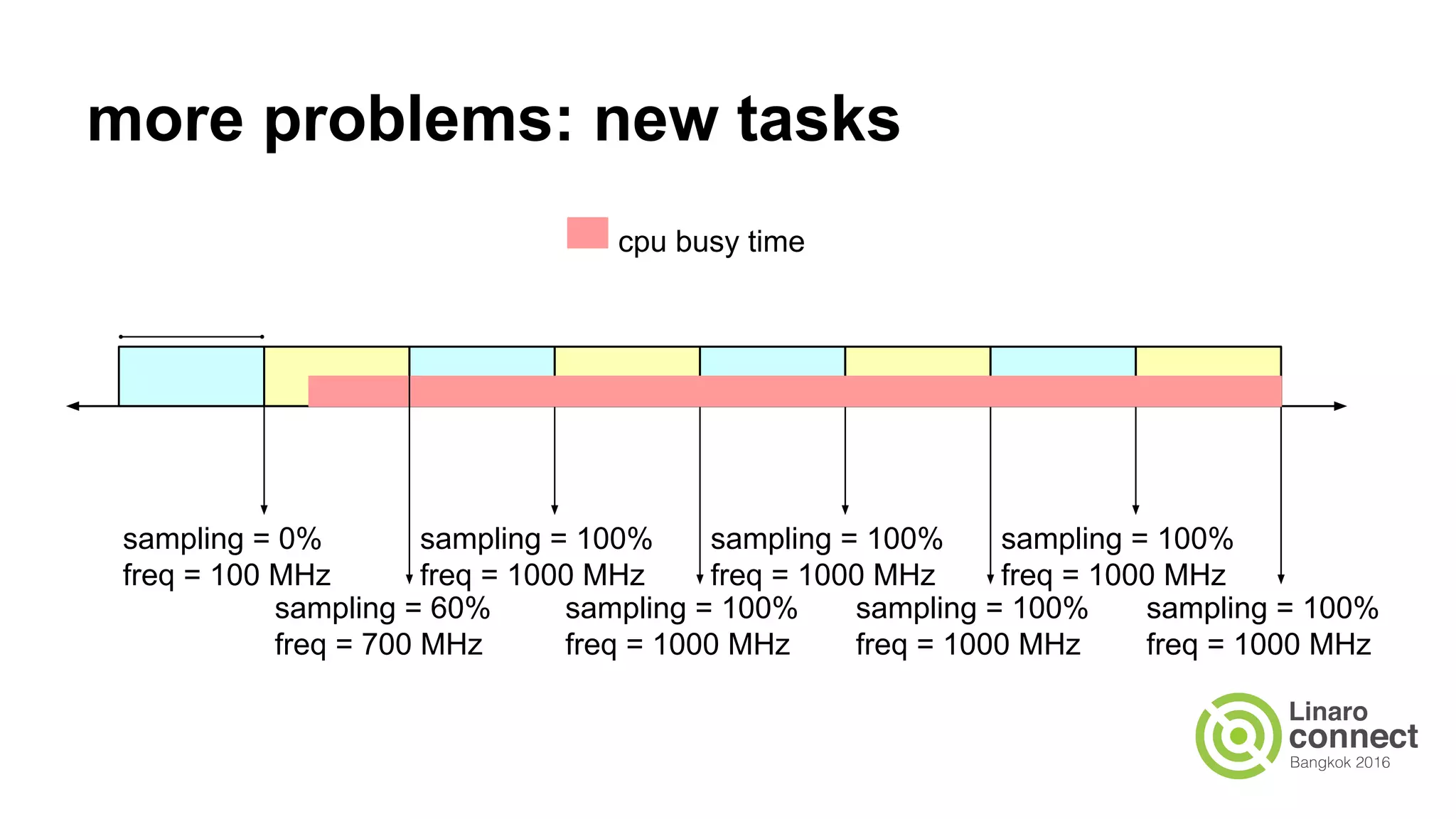







































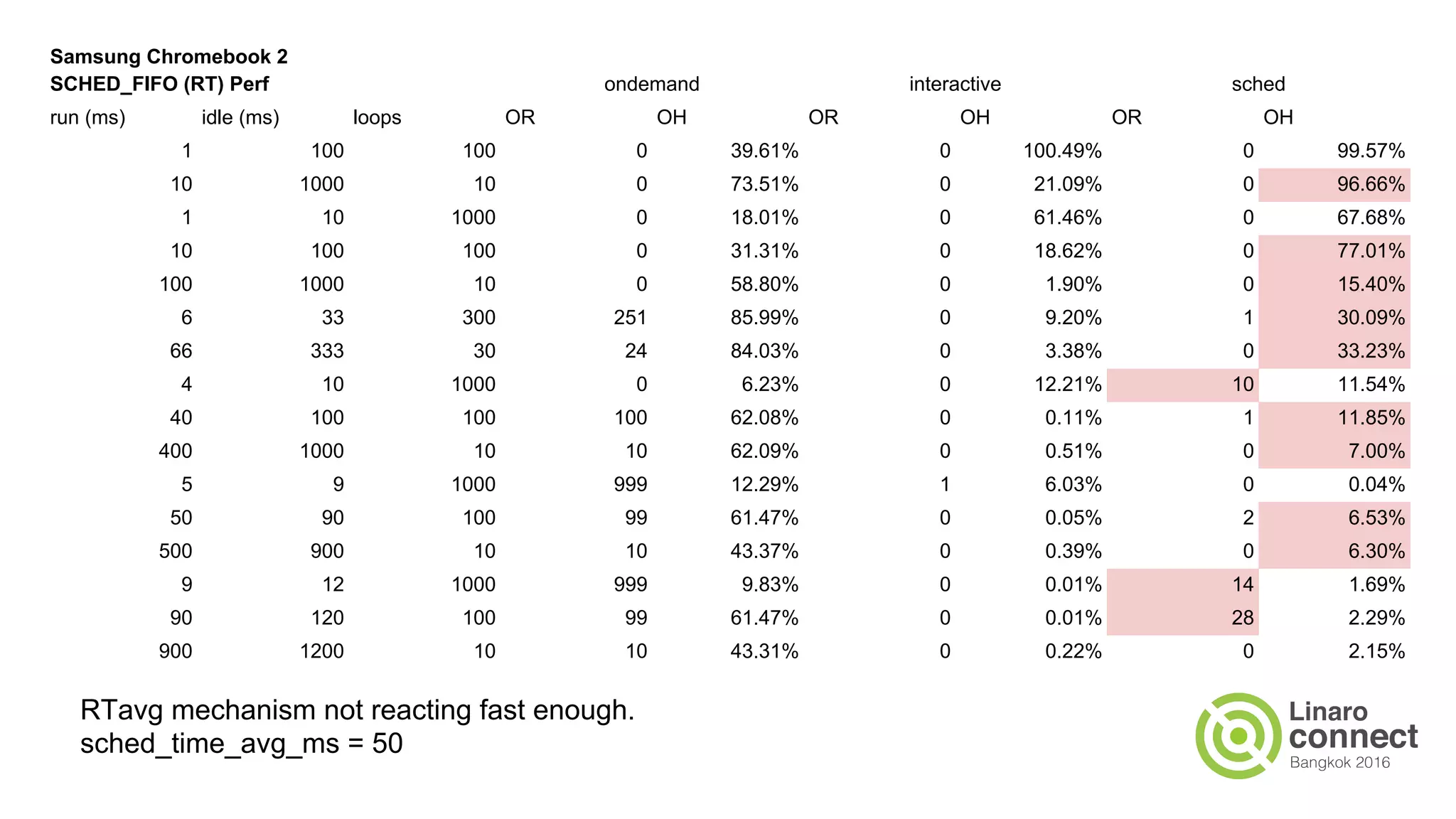















The document outlines a presentation on integrating the scheduler and CPU frequency (cpufreq) management, highlighting the current operational structure, design proposals, test results, and future steps. It discusses various cpufreq governors, their sampling methods, and the complexities of estimating CPU capacity for different task types. The document also covers performance measurements from specific test cases involving different hardware configurations and the implications of scheduler decisions on CPU efficiency.




























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














